溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“CNN如何解決Flowers圖像分類任務”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
(1)該數據需要從網上下載,需要耐心等待片刻,下載下來自動會存放在“你的主目錄.keras\datasets\flower_photos”。
(2)數據中總共有 5 種類,分別是 daisy、 dandelion、roses、sunflowers、tulips,總共包含了 3670 張圖片。
(3) 隨機展示了一張花朵的圖片。
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import pathlib
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import random
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("總共包含%d張圖片,下面隨便展示一張玫瑰的圖片樣例:"%image_count)
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(random.choice(roses)))(1)使用 tf.keras.utils.image_dataset_from_directory 可以將我們的花朵圖片數據,從磁盤加載到內存中,并形成 tensorflow 高效的 tf.data.Dataset 類型。
(2)我們將數據集 shuffle 之后,進行二八比例的隨機抽取分配,80% 的數據作為我們的訓練集,共 2936 張圖片, 20% 的數據集作為我們的測試集,共 734 張圖片。
(3)我們使用 Dataset.cache 和 Dataset.prefetch 來提升數據的處理速度,使用 cache 在將數據從磁盤加載到 cache 之后,就可以將數據一直放 cache 中便于我們的后續訪問,這可以保證在訓練過程中數據的處理不會成為計算的瓶頸。另外使用 prefetch 可以在 GPU 訓練模型的時候,CPU 將之后需要的數據提前進行處理放入 cache 中,也是為了提高數據的處理性能,加快整個訓練過程,不至于訓練模型時浪費時間等待數據。
(4)我們隨便選取了 6 張圖像進行展示,可以看到它們的圖片以及對應的標簽。
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.utils.image_dataset_from_directory( data_dir, validation_split=0.2, subset="training", seed=1, image_size=(img_height, img_width), batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory( data_dir, validation_split=0.2, subset="validation", seed=1, image_size=(img_height, img_width),batch_size=batch_size)
class_names = train_ds.class_names
num_classes = len(class_names)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
plt.figure(figsize=(5, 5))
for images, labels in train_ds.take(1):
for i in range(6):
ax = plt.subplot(2, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")結果打印:
Found 3670 files belonging to 5 classes.
Using 2936 files for training.
Found 3670 files belonging to 5 classes.
Using 734 files for validation.
(1)因為最初的圖片都是 RGB 三通道圖片,像素點的值在 [0,255] 之間,為了加速模型的收斂,我們要將所有的數據進行歸一化操作。所以在模型的第一層加入了 layers.Rescaling 對圖片進行處理。
(2)使用了三個卷積塊,每個卷積塊中包含了卷積層和池化層,并且每一個卷積層中都添加了 relu 激活函數,卷積層不斷提取圖片的特征,池化層可以有效的所見特征矩陣的尺寸,同時也可以減少最后連接層的中的參數數量,權重參數少的同時也起到了加快計算速度和防止過擬合的作用。
(3)最后加入了兩層全連接層,輸出對圖片的分類預測 logit 。
(4)使用 Adam 作為我們的模型優化器,使用 SparseCategoricalCrossentropy 計算我們的損失值,在訓練過程中觀察 accuracy 指標。
model = Sequential([ layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)), layers.Conv2D(16, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Conv2D(32, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Conv2D(64, 3, padding='same', activation='relu'), layers.MaxPooling2D(), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dense(num_classes) ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
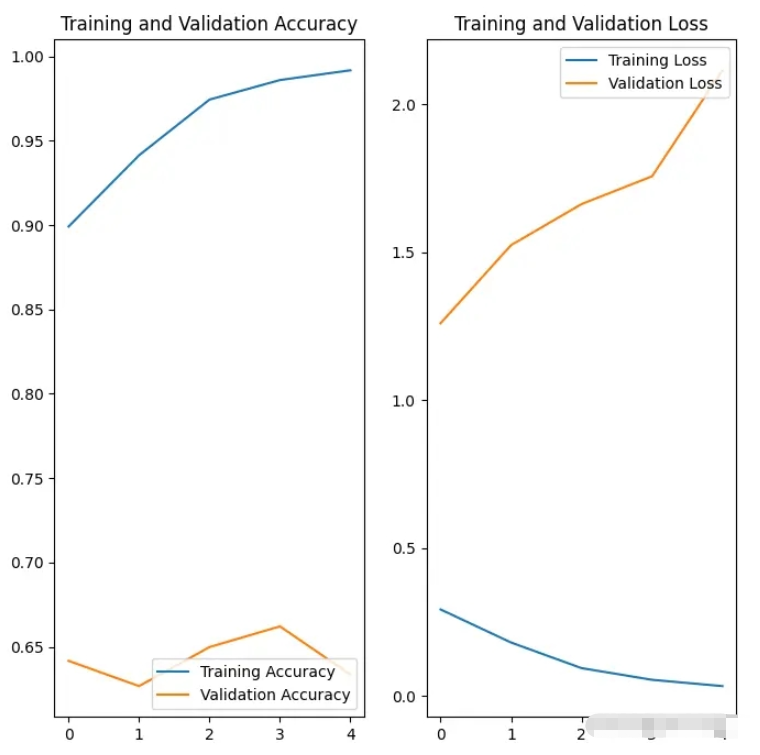
(1)我們使用訓練集進行模型的訓練,使用驗證集進行模型的驗證,總共訓練 5 個 epoch 。
(2)我們通過對訓練過程中產生的準確率和損失值,與驗證過程中產生的準確率和損失值進行繪圖對比,訓練時的準確率高出驗證時的準確率很多,訓練時的損失值遠遠低于驗證時的損失值,這說明模型存在過擬合風險。正常的情況這兩個指標應該是大體呈現同一個發展趨勢。
epochs = 5
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()結果打印:
Epoch 1/5
92/92 [==============================] - 45s 494ms/step - loss: 0.2932 - accuracy: 0.8992 - val_loss: 1.2603 - val_accuracy: 0.6417
Epoch 2/5
92/92 [==============================] - 40s 436ms/step - loss: 0.1814 - accuracy: 0.9414 - val_loss: 1.5241 - val_accuracy: 0.6267
Epoch 3/5
92/92 [==============================] - 36s 394ms/step - loss: 0.0949 - accuracy: 0.9745 - val_loss: 1.6629 - val_accuracy: 0.6499
Epoch 4/5
92/92 [==============================] - 48s 518ms/step - loss: 0.0554 - accuracy: 0.9860 - val_loss: 1.7566 - val_accuracy: 0.6621
Epoch 5/5
92/92 [==============================] - 39s 419ms/step - loss: 0.0341 - accuracy: 0.9918 - val_loss: 2.1150 - val_accuracy: 0.6335
(1)當訓練樣本數量較少時,通常會發生過擬合現象。我們可以操作數據增強技術,通過隨機翻轉、旋轉等方式來增加樣本的豐富程度。常見的數據增強處理方式有:tf.keras.layers.RandomFlip、tf.keras.layers.RandomRotation和 tf.keras.layers.RandomZoom。這些方法可以像其他層一樣包含在模型中,并在 GPU 上運行。
(2)這里挑選了一張圖片,對其進行 6 次執行數據增強,可以看到得到了經過一定程度縮放、旋轉、反轉的數據集。
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal", input_shape=(img_height, img_width, 3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.5)
])
plt.figure(figsize=(5, 5))
for images, _ in train_ds.take(1):
for i in range(6):
augmented_images = data_augmentation(images)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")
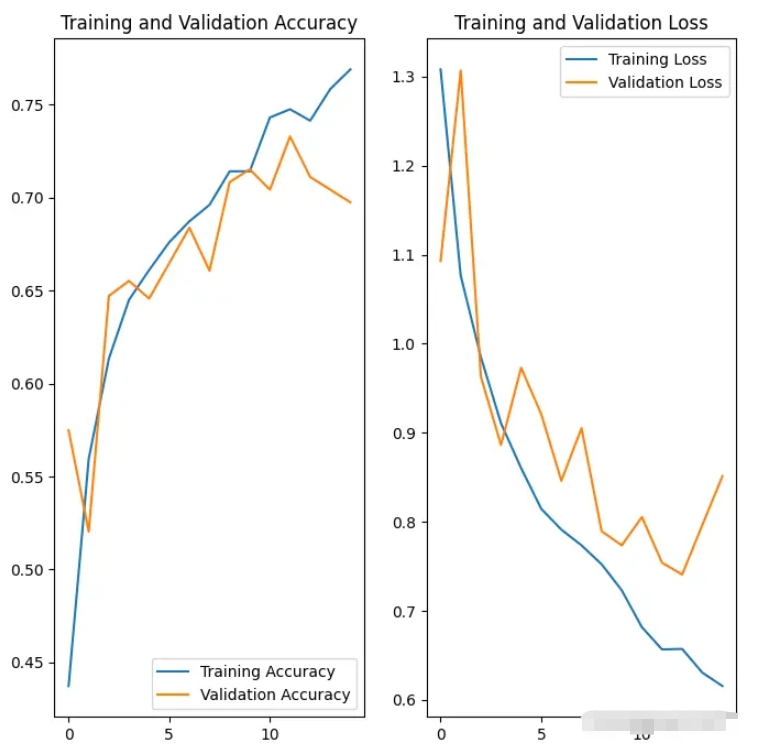
(3)在模型架構的開始加入數據增強層,同時在全連接層的地方加入 Dropout ,進行神經元的隨機失活,這兩個方法的加入可以有效抑制模型過擬合的風險。其他的模型結構、優化器、損失函數、觀測值和之前相同。通過繪制數據圖我們發現,使用這些措施很明顯減少了過擬合的風險。
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, name="outputs")
])
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
epochs = 15
history = model.fit( train_ds, validation_data=val_ds, epochs=epochs)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()結果打印:
92/92 [==============================] - 57s 584ms/step - loss: 1.3080 - accuracy: 0.4373 - val_loss: 1.0929 - val_accuracy: 0.5749
Epoch 2/15
92/92 [==============================] - 41s 445ms/step - loss: 1.0763 - accuracy: 0.5596 - val_loss: 1.3068 - val_accuracy: 0.5204
...
Epoch 14/15
92/92 [==============================] - 59s 643ms/step - loss: 0.6306 - accuracy: 0.7585 - val_loss: 0.7963 - val_accuracy: 0.7044
Epoch 15/15
92/92 [==============================] - 42s 452ms/step - loss: 0.6155 - accuracy: 0.7691 - val_loss: 0.8513 - val_accuracy: 0.6975
(4)最后我們使用一張隨機下載的圖片,用模型進行類別的預測,發現可以識別出來。
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img( sunflower_path, target_size=(img_height, img_width) )
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0)
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print( "這張圖片最有可能屬于 {} ,有 {:.2f} 的置信度。".format(class_names[np.argmax(score)], 100 * np.max(score)))結果打印:
這張圖片最有可能屬于 sunflowers ,有 97.39 的置信度。
“CNN如何解決Flowers圖像分類任務”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





