溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python怎么使用Pandas處理測試數據”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Python怎么使用Pandas處理測試數據”文章能幫助大家解決問題。
功能極其強大的數據分析庫
可以高效地操作各種數據集
csv格式的文件
Excel文件
HTML文件
XML格式的文件
JSON格式的文件
數據庫操作
通過面試題引出主題,讀者可以思考,如果你遇到這題,該如何解答呢?

a.通過Pypi來安裝
pip install pandas
b.通過源碼來安裝
git clone git://github.com/pydata/pandas.gitcd pandaspython setup.py install
案例中的lemon_cases.xlsx文件內容如下所示:
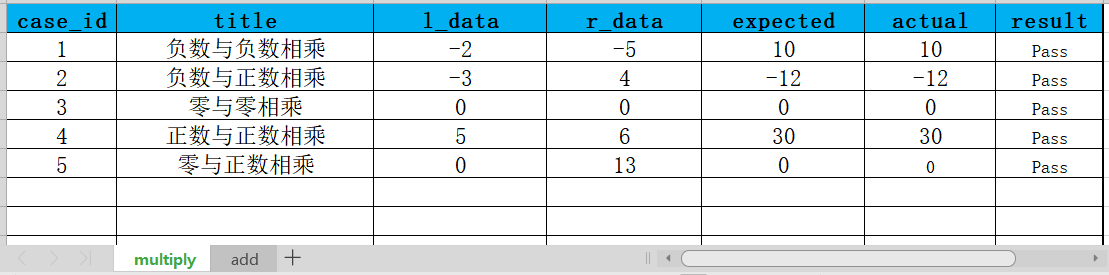
import pandas as pd
# 讀excel文件
# 返回一個DataFrame對象,多維數據結構
df = pd.read_excel('lemon_cases.xlsx', sheet_name='multiply')
print(df)
# 1.讀取一列數據
# df["title"] 返回一個Series對象,記錄title這列的數據
print(df["title"])
# Series對象能轉化為任何序列類型和dict字典類型
print(list(df['title'])) # 轉化為列表
# title為DataFrame對象的屬性
print(list(df.title)) # 轉化為列表
print(tuple(df['title'])) # 轉化為元組
print(dict(df['title'])) # 轉化為字典,key為數字索引
# 2.讀取某一個單元格數據
# 不包括表頭,指定列名和行索引
print(df['title'][0]) # title列,不包括表頭的第一個單元格
# 3.讀取多列數據
print(df[["title", "actual"]])import pandas as pd
# 讀excel文件
df = pd.read_excel('lemon_cases.xlsx', sheet_name='multiply') # 返回一個DataFrame對象,多維數據結構
print(df)
# 1.讀取一行數據
# 不包括表頭,第一個索引值為0
# 獲取第一行數據,可以將其轉化為list、tuple、dict
print(list(df.iloc[0])) # 轉成列表
print(tuple(df.iloc[0])) # 轉成元組
print(dict(df.iloc[0])) # 轉成字典
print(dict(df.iloc[-1])) # 也支持負索引
# 2.讀取某一個單元格數據
# 不包括表頭,指定行索引和列索引(或者列名)
print(df.iloc[0]["l_data"]) # 指定行索引和列名
print(df.iloc[0][2]) # 指定行索引和列索引
# 3.讀取多行數據
print(df.iloc[0:3])import pandas as pd
# 讀excel文件
df = pd.read_excel('lemon_cases.xlsx', sheet_name='multiply') # 返回一個DataFrame對象,多維數據結構
print(df)
# 1.iloc方法
# iloc使用數字索引來讀取行和列
# 也可以使用iloc方法讀取某一列
print(df.iloc[:, 0])
print(df.iloc[:, 1])
print(df.iloc[:, -1])
# 讀取多列
print(df.iloc[:, 0:3])
# 讀取多行多列
print(df.iloc[2:4, 1:4])
print(df.iloc[[1, 3], [2, 4]])
# 2.loc方法
# loc方法,基于標簽名或者索引名來選擇
print(df.loc[1:2, "title"]) # 多行一列
print(df.loc[1:2, "title":"r_data"]) # 多列多行
# 基于布爾類型來選擇
print(df["r_data"] > 5) # 某一列中大于5的數值為True,否則為False
print(df.loc[df["r_data"] > 5]) # 把r_data列中大于5,所在的行選擇出來
print(df.loc[df["r_data"] > 5, "r_data":"actual"]) # 把r_data到actual列選擇出來import pandas as pd
# 讀excel文件
df = pd.read_excel('lemon_cases.xlsx', sheet_name='multiply') # 返回一個DataFrame對象,多維數據結構
print(df)
# 讀取的數據為嵌套列表的列表類型,此方法不推薦使用
print(df.values)
# 嵌套字典的列表
datas_list = []
for r_index in df.index:
datas_list.append(df.iloc[r_index].to_dict())
print(datas_list)import pandas as pd
# 讀excel文件
df = pd.read_excel('lemon_cases.xlsx', sheet_name='multiply') # 返回一個DataFrame對象,多維數據結構
print(df)
df['result'][0] = 1000
print(df)
with pd.ExcelWriter('lemon_cases_new.xlsx') as writer:
df.to_excel(writer, sheet_name="New", index=False)案例中的data.log文件內容如下所示:
TestID,TestTime,Success
0,149,0
1,69,0
2,45,0
3,18,1
4,18,1
import pandas as pd
# 讀取csv文件
# 方法一,使用read_csv讀取,列與列之間默認以逗號分隔(推薦方法)
# a.第一行為列名信息
csvframe = pd.read_csv('data.log')
# b.第一行沒有列名信息,直接為數據
csvframe = pd.read_csv('data.log', header=None)
# c.第一行沒有列名信息,直接為數據,也可以指定列名
csvframe = pd.read_csv('data.log', header=None, names=["Col1", "Col2", "Col3"])
# 方法二,read_table,需要指定列與列之間分隔符為逗號
csvframe = pd.read_table('data.log', sep=",")import pandas as pd
# 1.讀取csv文件
csvframe = pd.read_csv('data.log')
# 2.選擇Success為0的行
new_csvframe = csvframe.loc[csvframe["Success"] == 0]
result_csvframe = new_csvframe["TestTime"]
avg_result = round(sum(result_csvframe)/len(result_csvframe), 2)
print("TestTime最小值為:{}\nTestTime最大值為:{}\nTestTime平均值為:{}".
format(min(result_csvframe), max(result_csvframe), avg_result))關于“Python怎么使用Pandas處理測試數據”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





