溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“NumPy與Python內置列表計算標準差區別是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
NumPy,是 Numerical Python 的簡稱,用于高性能科學計算和數據分析的基礎包,像數學科學工具(pandas)和框架(Scikit-learn)中都使用到了 NumPy 這個包。
NumPy 中的基本數據結構是ndarray或者 N 維數值數組,在形式上來說,它的結構有點像 Python 的基礎類型——Python列表。
但本質上,這兩者并不同,可以看到一個簡單的對比。
我們創建兩個列表,當我們創建好了之后,可以使用 +運算符進行連接:
list1 = [i for i in range(1,11)] list2 = [i**2 for i in range(1,11)] print(list1+list2) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
列表中元素的處理感覺像對象,不是很數字,不是嗎? 如果這些是數字向量而不是簡單的數字列表,您會期望 + 運算符的行為略有不同,并將第一個列表中的數字按元素添加到第二個列表中的相應數字中。
接下來看一下 Nympy 的數組版本:
import numpy as np arr1 = np.array(list1) arr2 = np.array(list2) arr1 + arr2 # array([ 2, 6, 12, 20, 30, 42, 56, 72, 90, 110])
通過 numpy 的np.array數組方法實現了兩個列表內的逐個值進行相加。
我們通過dir 函數來看兩者的區別,先看 Python 內置列表 list1的內置方法:

再用同樣的方法看一下 arr1中的方法:
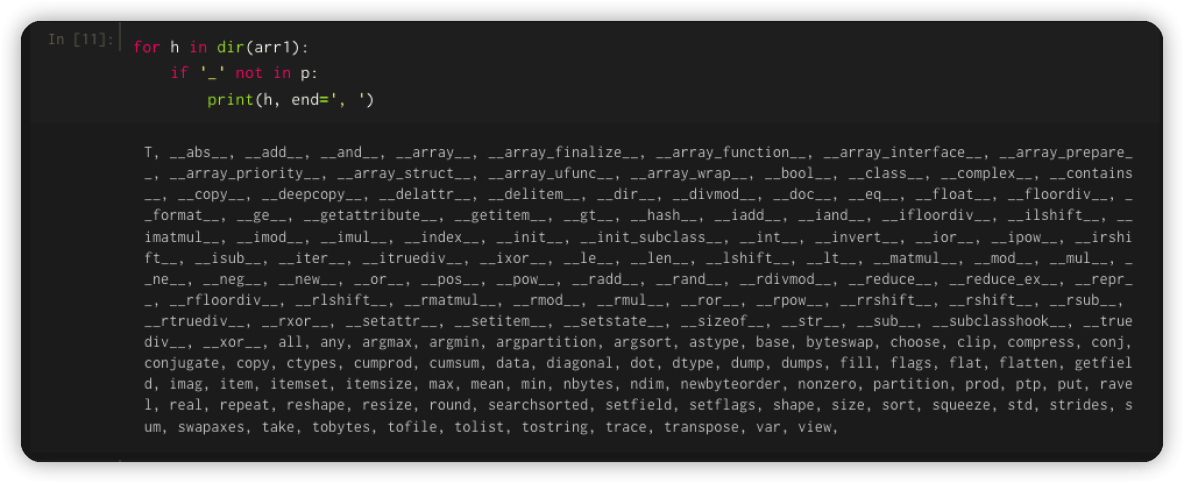
NumPy 數組對象還有更多可用的函數和屬性。 特別要注意諸如mean、std和sum之類的方法,因為它們清楚地表明重點關注使用這種數組對象的數值/統計計算。 而且這些操作也很快。
NumPy 的速度要快得多,因為它的矢量化實現以及它的許多核心例程最初是用 C 語言(基于 CPython 框架)編寫的。 NumPy 數組是同構類型的密集排列的數組。 相比之下,Python 列表是指向對象的指針數組,即使它們都屬于同一類型。 因此,我們得到了參考局部性的好處。
許多 NumPy 操作是用 C 語言實現的,避免了 Python 中的循環、指針間接和逐元素動態類型檢查的一般成本。 特別是,速度的提升取決于您正在執行的操作。 對于數據科學和 ML 任務,這是一個無價的優勢,因為它避免了長和多維數組中的循環。
讓我們使用 @timing計時裝飾器來說明這一點。 這是一個圍繞兩個函數 std_dev和std_dev_python包裝裝飾器的代碼,分別使用 NumPy 和本機 Python 代碼實現列表/數組的標準差計算。
我們可以使用 Python 裝飾器和functools模塊的wrapping來寫一個 時間裝飾器timing:
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap然后利用這個時間裝飾器來看 Numpy 數組和 Python 內置的列表,然后計算他們的標準差,
公式如圖:
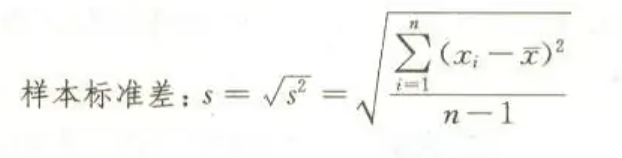
定義 Numpy 計算標準差的函數std_dev(),numpy 模塊中內置了標準差公式的函數 a.std(),我們可以直接調用
列表計算公式方法需要按照公式一步一步計算:
先求求出宗和s
然后求出平均值average
計算每個數值與平均值的差的平方,再求和sumsq
再求出sumsq 的平均值 sumsq_average
得到最終的標準差結果result
代碼如下:
from functools import wraps
from time import time
import numpy as np
from math import sqrt
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
# print(f"Function '{func.__name__}' with arguments {args},keywords {kw} took {end_time-begin_time} seconds to run")
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap
@timing
def std_dev(a):
if isinstance(a, list):
a = np.array(a)
s = a.std()
return s
@timing
def std_dev_python(lst):
length = len(lst)
s = sum(lst)
average = s / length
sumsq = 0
for i in lst:
sumsq += (i-average)**2
sumsq_average = sumsq/length
result = sqrt(sumsq_average)
return result運行結果,最終可以看到 1000000 個值得標準差的值為 288675.13459,而 Numpy 計算時間為 0.0080 s,而 Python 原生計算方式為 0.2499 s:
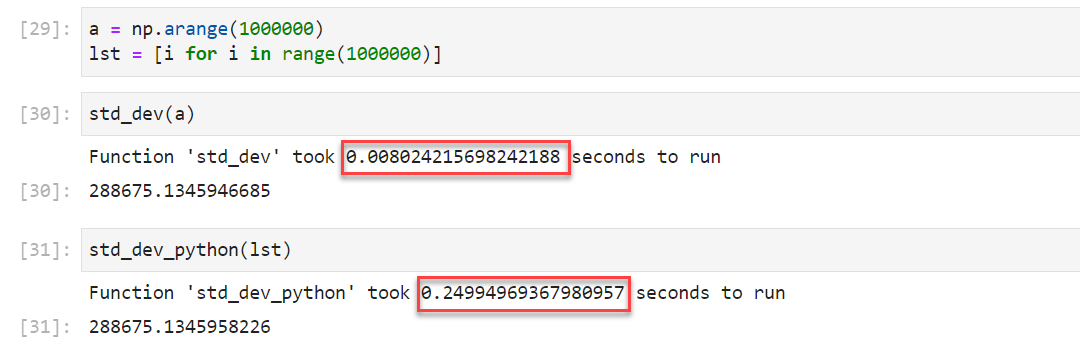
由此可見,Numpy 的方式明顯更快。
“NumPy與Python內置列表計算標準差區別是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





