溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Node中的可讀流是什么的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Node中的可讀流是什么文章都會有所收獲,下面我們一起來看看吧。
1.1. 流的歷史演變
流不是 Nodejs 特有的概念。 它們是幾十年前在 Unix 操作系統中引入的,程序可以通過管道運算符(|)對流進行相互交互。
在基于Unix系統的MacOS以及Linux中都可以使用管道運算符(|),他可以將運算符左側進程的輸出轉換成右側的輸入。
在Node中,我們使用傳統的readFile去讀取文件的話,會將文件從頭到尾都讀到內存中,當所有內容都被讀取完畢之后才會對加載到內存中的文件內容進行統一處理。
這樣做會有兩個缺點:
內存方面:占用大量內存
時間方面:需要等待數據的整個有效負載都加載完才會開始處理數據
為了解決上述問題,Node.js效仿并實現了流的概念,在Node.js流中,一共有四種類型的流,他們都是Node.js中EventEmitter的實例:
可讀流(Readable Stream)
可寫流(Writable Stream)
可讀可寫全雙工流(Duplex Stream)
轉換流(Transform Stream)
為了深入學習這部分的內容,循序漸進的理解Node.js中流的概念,并且由于源碼部分較為復雜,本人決定先從可讀流開始學習這部分內容。
1.2. 什么是流(Stream)
流是一種抽象的數據結構,是數據的集合,其中存儲的數據類型只能為以下類型(僅針對objectMode === false的情況):
string
Buffer
我們可以把流看作這些數據的集合,就像液體一樣,我們先把這些液體保存在一個容器里(流的內部緩沖區BufferList),等到相應的事件觸發的時候,我們再把里面的液體倒進管道里,并通知其他人在管道的另一側拿自己的容器來接里面的液體進行處理。
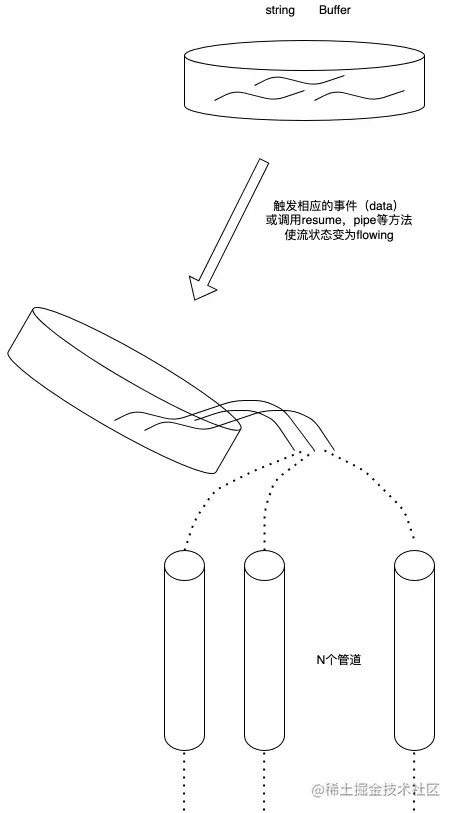
1.3. 什么是可讀流(Readable Stream)
可讀流是流的一種類型,他有兩種模式三種狀態
兩種讀取模式:
流動模式:數據會從底層系統讀取,并通過EventEmitter盡快的將數據傳遞給所注冊的事件處理程序中
暫停模式:在這種模式下將不會讀取數據,必須顯示的調用Stream.read()方法來從流中讀取數據
三種狀態:
readableFlowing === null:不會產生數據,調用Stream.pipe()、Stream.resume會使其狀態變為true,開始產生數據并主動觸發事件
readableFlowing === false:此時會暫停數據的流動,但不會暫停數據的生成,因此會產生數據積壓
readableFlowing === true:正常產生和消耗數據
2.1. 內部狀態定義(ReadableState)
ReadableState
_readableState: ReadableState {
objectMode: false, // 操作除了string、Buffer、null之外的其他類型的數據需要把這個模式打開
highWaterMark: 16384, // 水位限制,1024 \* 16,默認16kb,超過這個限制則會停止調用\_read()讀數據到buffer中
buffer: BufferList { head: null, tail: null, length: 0 }, // Buffer鏈表,用于保存數據
length: 0, // 整個可讀流數據的大小,如果是objectMode則與buffer.length相等
pipes: [], // 保存監聽了該可讀流的所有管道隊列
flowing: null, // 可獨流的狀態 null、false、true
ended: false, // 所有數據消費完畢
endEmitted: false, // 結束事件收否已發送
reading: false, // 是否正在讀取數據
constructed: true, // 流在構造好之前或者失敗之前,不能被銷毀
sync: true, // 是否同步觸發'readable'/'data'事件,或是等到下一個tick
needReadable: false, // 是否需要發送readable事件
emittedReadable: false, // readable事件發送完畢
readableListening: false, // 是否有readable監聽事件
resumeScheduled: false, // 是否調用過resume方法
errorEmitted: false, // 錯誤事件已發送
emitClose: true, // 流銷毀時,是否發送close事件
autoDestroy: true, // 自動銷毀,在'end'事件觸發后被調用
destroyed: false, // 流是否已經被銷毀
errored: null, // 標識流是否報錯
closed: false, // 流是否已經關閉
closeEmitted: false, // close事件是否已發送
defaultEncoding: 'utf8', // 默認字符編碼格式
awaitDrainWriters: null, // 指向監聽了'drain'事件的writer引用,類型為null、Writable、Set<Writable>
multiAwaitDrain: false, // 是否有多個writer等待drain事件
readingMore: false, // 是否可以讀取更多數據
dataEmitted: false, // 數據已發送
decoder: null, // 解碼器
encoding: null, // 編碼器
[Symbol(kPaused)]: null
},
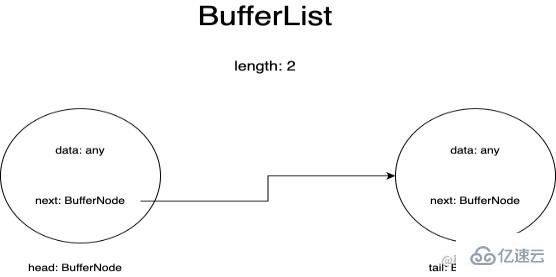
2.2. 內部數據存儲實現(BufferList)
BufferList是用于流保存內部數據的容器,它被設計為了鏈表的形式,一共有三個屬性head、tail和length。
BufferList中的每一個節點我把它表示為了BufferNode,里面的Data的類型取決于objectMode。
這種數據結構獲取頭部的數據的速度快于Array.prototype.shift()。
2.2.1. 數據存儲類型
如果objectMode === true:
那么data則可以為任意類型,push的是什么數據則存儲的就是什么數據
objectMode=true
const Stream = require('stream');
const readableStream = new Stream.Readable({
objectMode: true,
read() {},
});
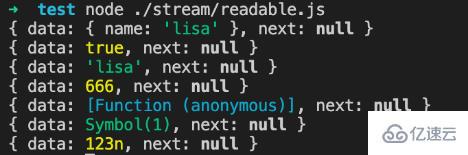
readableStream.push({ name: 'lisa'});
console.log(readableStream._readableState.buffer.tail);
readableStream.push(true);
console.log(readableStream._readableState.buffer.tail);
readableStream.push('lisa');
console.log(readableStream._readableState.buffer.tail);
readableStream.push(666);
console.log(readableStream._readableState.buffer.tail);
readableStream.push(() => {});
console.log(readableStream._readableState.buffer.tail);
readableStream.push(Symbol(1));
console.log(readableStream._readableState.buffer.tail);
readableStream.push(BigInt(123));
console.log(readableStream._readableState.buffer.tail);
運行結果:
如果objectMode === false:
那么data只能為string或者Buffer或者Uint8Array
objectMode=false
const Stream = require('stream');
const readableStream = new Stream.Readable({
objectMode: false,
read() {},
});
readableStream.push({ name: 'lisa'});
運行結果:

2.2.2. 數據存儲結構
我們在控制臺通過node命令行創建一個可讀流,來觀察buffer中數據的變化:

當然在push數據之前我們需要實現他的_read方法,或者在構造函數的參數中實現read方法:
const Stream = require('stream');
const readableStream = new Stream.Readable();
RS._read = function(size) {}
或者
const Stream = require('stream');
const readableStream = new Stream.Readable({
read(size) {}
});
經過readableStream.push('abc')操作之后,當前的buffer為:

可以看到目前的數據存儲了,頭尾存儲的數據都是字符串'abc'的ascii碼,類型為Buffer類型,length表示當前保存的數據的條數而非數據內容的大小。
2.2.3. 相關API
打印一下BufferList的所有方法可以得到:
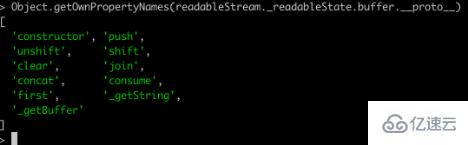
除了join是將BufferList序列化為字符串之外,其他都是對數據的存取操作。
這里就不一一講解所有的方法了,重點講一下其中的consume 、_getString和_getBuffer。
2.2.3.1. consume
源碼地址:BufferList.consume
https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L80
comsume
// Consumes a specified amount of bytes or characters from the buffered data.
consume(n, hasStrings) {
const data = this.head.data;
if (n < data.length) {
// `slice` is the same for buffers and strings.
const slice = data.slice(0, n);
this.head.data = data.slice(n);
return slice;
}
if (n === data.length) {
// First chunk is a perfect match.
return this.shift();
}
// Result spans more than one buffer.
return hasStrings ? this.\_getString(n) : this.\_getBuffer(n);
}
代碼一共有三個判斷條件:
如果所消耗的數據的字節長度小于鏈表頭節點存儲數據的長度,則將頭節點的數據取前n字節,并把當前頭節點的數據設置為切片之后的數據
如果所消耗的數據恰好等于鏈表頭節點所存儲的數據的長度,則直接返回當前頭節點的數據
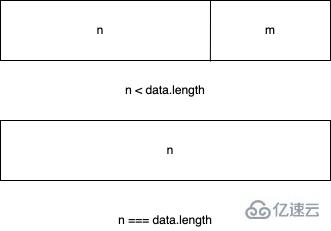
如果所消耗的數據的長度大于鏈表頭節點的長度,那么會根據傳入的第二個參數進行最后一次判斷,判斷當前的BufferList底層存儲的是string還是Buffer
2.2.3.2. _getBuffer
源碼地址:BufferList._getBuffer
https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L137
comsume
// Consumes a specified amount of bytes from the buffered data.
_getBuffer(n) {
const ret = Buffer.allocUnsafe(n);
const retLen = n;
let p = this.head;
let c = 0;
do {
const buf = p.data;
if (n > buf.length) {
TypedArrayPrototypeSet(ret, buf, retLen - n);
n -= buf.length;
} else {
if (n === buf.length) {
TypedArrayPrototypeSet(ret, buf, retLen - n);
++c;
if (p.next)
this.head = p.next;
else
this.head = this.tail = null;
} else {
TypedArrayPrototypeSet(ret,
new Uint8Array(buf.buffer, buf.byteOffset, n),
retLen - n);
this.head = p;
p.data = buf.slice(n);
}
break;
}
++c;
} while ((p = p.next) !== null);
this.length -= c;
return ret;
}
總的來說就是循環對鏈表中的節點進行操作,新建一個Buffer數組用于存儲返回的數據。
首先從鏈表的頭節點開始取數據,不斷的復制到新建的Buffer中,直到某一個節點的數據大于等于要取的長度減去已經取得的長度。
或者說讀到鏈表的最后一個節點后,都還沒有達到要取的長度,那么就返回這個新建的Buffer。
2.2.3.3. _getString
源碼地址:BufferList._getString
https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/buffer_list.js#L106
comsume
// Consumes a specified amount of characters from the buffered data.
_getString(n) {
let ret = '';
let p = this.head;
let c = 0;
do {
const str = p.data;
if (n > str.length) {
ret += str;
n -= str.length;
} else {
if (n === str.length) {
ret += str;
++c;
if (p.next)
this.head = p.next;
else
this.head = this.tail = null;
} else {
ret += StringPrototypeSlice(str, 0, n);
this.head = p;
p.data = StringPrototypeSlice(str, n);
}
break;
}
++c;
} while ((p = p.next) !== null);
this.length -= c;
return ret;
}
對于操作字符串來說和操作Buffer是一樣的,也是循環從鏈表的頭部開始讀數據,只是進行數據的拷貝存儲方面有些差異,還有就是_getString操作返回的數據類型是string類型。
2.3. 為什么可讀流是EventEmitter的實例?
對于這個問題而言,首先要了解什么是發布訂閱模式,發布訂閱模式在大多數API中都有重要的應用,無論是Promise還是Redux,基于發布訂閱模式實現的高級API隨處可見。
它的優點在于能將事件的相關回調函數存儲到隊列中,然后在將來的某個時刻通知到對方去處理數據,從而做到關注點分離,生產者只管生產數據和通知消費者,而消費者則只管處理對應的事件及其對應的數據,而Node.js流模式剛好符合這一特點。
那么Node.js流是怎樣實現基于EventEmitter創建實例的呢?
這部分源碼在這兒:stream/legacy
https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/legacy.js#L10
legacy
function Stream(opts) {
EE.call(this, opts);
}
ObjectSetPrototypeOf(Stream.prototype, EE.prototype);
ObjectSetPrototypeOf(Stream, EE);
然后在可讀流的源碼中有這么幾行代碼:
這部分源碼在這兒:readable
https://github.com/nodejs/node/blob/d5e94fa7121c9d424588f0e1a388f8c72c784622/lib/internal/streams/readable.js#L77
legacy
ObjectSetPrototypeOf(Readable.prototype, Stream.prototype);
ObjectSetPrototypeOf(Readable, Stream);
首先將Stream的原型對象繼承自EventEmitter,這樣Stream的所有實例都可以訪問到EventEmitter上的方法。
同時通過ObjectSetPrototypeOf(Stream, EE)將EventEmitter上的靜態方法也繼承過來,并在Stream的構造函數中,借用構造函數EE來實現所有EventEmitter中的屬性的繼承,然后在可讀流里,用同樣的的方法實現對Stream類的原型繼承和靜態屬性繼承,從而得到:
Readable.prototype.__proto__ === Stream.prototype;
Stream.prototype.__proto__ === EE.prototype
因此:
Readable.prototype.__proto__.__proto__ === EE.prototype
所以捋著可讀流的原型鏈可以找到EventEmitter的原型,實現對EventEmitter的繼承
2.4. 相關API的實現
這里會按照源碼文檔中API的出現順序來展示,且僅解讀其中的核心API實現。
注:此處僅解讀Node.js可讀流源碼中所聲明的函數,不包含外部引入的函數定義,同時為了減少篇幅,不會將所有代碼都拷貝下來。
Readable.prototype
Stream {
destroy: [Function: destroy],
_undestroy: [Function: undestroy],
_destroy: [Function (anonymous)],
push: [Function (anonymous)],
unshift: [Function (anonymous)],
isPaused: [Function (anonymous)],
setEncoding: [Function (anonymous)],
read: [Function (anonymous)],
_read: [Function (anonymous)],
pipe: [Function (anonymous)],
unpipe: [Function (anonymous)],
on: [Function (anonymous)],
addListener: [Function (anonymous)],
removeListener: [Function (anonymous)],
off: [Function (anonymous)],
removeAllListeners: [Function (anonymous)],
resume: [Function (anonymous)],
pause: [Function (anonymous)],
wrap: [Function (anonymous)],
iterator: [Function (anonymous)],
[Symbol(nodejs.rejection)]: [Function (anonymous)],
[Symbol(Symbol.asyncIterator)]: [Function (anonymous)]
}
2.4.1. push
readable.push
Readable.prototype.push = function(chunk, encoding) {
return readableAddChunk(this, chunk, encoding, false);
};
push方法的主要作用就是將數據塊通過觸發'data'事件傳遞給下游管道,或者將數據存儲到自身的緩沖區中。
以下代碼為相關偽代碼,僅展示主流程:
readable.push
function readableAddChunk(stream, chunk, encoding, addToFront) {
const state = stream.\_readableState;
if (chunk === null) { // push null 流結束信號,之后不能再寫入數據
state.reading = false;
onEofChunk(stream, state);
} else if (!state.objectMode) { // 如果不是對象模式
if (typeof chunk === 'string') {
chunk = Buffer.from(chunk);
} else if (chunk instanceof Buffer) { //如果是Buffer
// 處理一下編碼
} else if (Stream.\_isUint8Array(chunk)) {
chunk = Stream.\_uint8ArrayToBuffer(chunk);
} else if (chunk != null) {
err = new ERR\_INVALID\_ARG\_TYPE('chunk', ['string', 'Buffer', 'Uint8Array'], chunk);
}
}
if (state.objectMode || (chunk && chunk.length > 0)) { // 是對象模式或者chunk是Buffer
// 這里省略幾種數據的插入方式的判斷
addChunk(stream, state, chunk, true);
}
}
function addChunk(stream, state, chunk, addToFront) {
if (state.flowing && state.length === 0 && !state.sync &&
stream.listenerCount('data') > 0) { // 如果處于流動模式,有監聽data的訂閱者
stream.emit('data', chunk);
} else { // 否則保存數據到緩沖區中
state.length += state.objectMode ? 1 : chunk.length;
if (addToFront) {
state.buffer.unshift(chunk);
} else {
state.buffer.push(chunk);
}
}
maybeReadMore(stream, state); // 嘗試多讀一點數據
}
push操作主要分為對objectMode的判斷,不同的類型對傳入的數據會做不同的操作:
objectMode === false: 將數據(chunk)轉換成Buffer
objectMode === true: 將數據原封不動的傳遞給下游
其中addChunk的第一個判斷主要是處理Readable處于流動模式、有data監聽器、并且緩沖區數據為空時的情況。
這時主要將數據passthrough透傳給訂閱了data事件的其他程序,否則就將數據保存到緩沖區里面。
2.4.2. read
除去對邊界條件的判斷、流狀態的判斷,這個方法主要有兩個操作
調用用戶實現的_read方法,對執行結果進行處理
從緩沖區buffer中讀取數據,并觸發'data'事件
readable.read
// 如果read的長度大于hwm,則會重新計算hwm
if (n > state.highWaterMark) {
state.highWaterMark = computeNewHighWaterMark(n);
}
// 調用用戶實現的\_read方法
try {
const result = this.\_read(state.highWaterMark);
if (result != null) {
const then = result.then;
if (typeof then === 'function') {
then.call(
result,
nop,
function(err) {
errorOrDestroy(this, err);
});
}
}
} catch (err) {
errorOrDestroy(this, err);
}
如果說用戶實現的_read方法返回的是一個promise,則調用這個promise的then方法,將成功和失敗的回調傳入,便于處理異常情況。
read方法從緩沖區里讀區數據的核心代碼如下:
readable.read
function fromList(n, state) {
// nothing buffered.
if (state.length === 0)
return null;
let ret;
if (state.objectMode)
ret = state.buffer.shift();
else if (!n || n >= state.length) { // 處理n為空或者大于緩沖區的長度的情況
// Read it all, truncate the list.
if (state.decoder) // 有解碼器,則將結果序列化為字符串
ret = state.buffer.join('');
else if (state.buffer.length === 1) // 只有一個數據,返回頭節點數據
ret = state.buffer.first();
else // 將所有數據存儲到一個Buffer中
ret = state.buffer.concat(state.length);
state.buffer.clear(); // 清空緩沖區
} else {
// 處理讀取長度小于緩沖區的情況
ret = state.buffer.consume(n, state.decoder);
}
return ret;
}
2.4.3. _read
用戶初始化Readable stream時必須實現的方法,可以在這個方法里調用push方法,從而持續的觸發read方法,當我們push null時可以停止流的寫入操作。
示例代碼:
readable._read
const Stream = require('stream');
const readableStream = new Stream.Readable({
read(hwm) {
this.push(String.fromCharCode(this.currentCharCode++));
if (this.currentCharCode > 122) {
this.push(null);
}
},
});
readableStream.currentCharCode = 97;
readableStream.pipe(process.stdout);
// abcdefghijklmnopqrstuvwxyz%
2.4.4. pipe(重要)
將一個或多個writable流綁定到當前的Readable流上,并且將Readable流切換到流動模式。
這個方法里面有很多的事件監聽句柄,這里不會一一介紹:
readable.pipe
Readable.prototype.pipe = function(dest, pipeOpts) {
const src = this;
const state = this.\_readableState;
state.pipes.push(dest); // 收集Writable流
src.on('data', ondata);
function ondata(chunk) {
const ret = dest.write(chunk);
if (ret === false) {
pause();
}
}
// Tell the dest that it's being piped to.
dest.emit('pipe', src);
// 啟動流,如果流處于暫停模式
if (dest.writableNeedDrain === true) {
if (state.flowing) {
pause();
}
} else if (!state.flowing) {
src.resume();
}
return dest;
}
pipe操作和Linux的管道操作符'|'非常相似,將左側輸出變為右側輸入,這個方法會將可寫流收集起來進行維護,并且當可讀流觸發'data'事件。
有數據流出時,就會觸發可寫流的寫入事件,從而做到數據傳遞,實現像管道一樣的操作。并且會自動將處于暫停模式的可讀流變為流動模式。
2.4.5. resume
使流從'暫停'模式切換到'流動'模式,如果設置了'readable'事件監聽,那么這個方法其實是沒有效果的
readable.resume
Readable.prototype.resume = function() {
const state = this._readableState;
if (!state.flowing) {
state.flowing = !state.readableListening; // 是否處于流動模式取決于是否設置了'readable'監聽句柄
resume(this, state);
}
};
function resume(stream, state) {
if (!state.resumeScheduled) { // 開關,使resume_方法僅在同一個Tick中調用一次
state.resumeScheduled = true;
process.nextTick(resume_, stream, state);
}
}
function resume_(stream, state) {
if (!state.reading) {
stream.read(0);
}
state.resumeScheduled = false;
stream.emit('resume');
flow(stream);
}
function flow(stream) { // 當流處于流模式該方法會不斷的從buffer中讀取數據,直到緩沖區為空
const state = stream._readableState;
while (state.flowing && stream.read() !== null);
// 因為這里會調用read方法,設置了'readable'事件監聽器的stream,也有可能會調用read方法,
//從而導致數據不連貫(不影響data,僅影響在'readable'事件回調中調用read方法讀取數據)
}
2.4.6. pause
將流從流動模式轉變為暫停模式,停止觸發'data'事件,將所有的數據保存到緩沖區
readable.pause
Readable.prototype.pause = function() {
if (this._readableState.flowing !== false) {
debug('pause');
this._readableState.flowing = false;
this.emit('pause');
}
return this;
};
2.5. 使用方法與工作機制
使用方法在BufferList部分已經講過了,創建一個Readable實例,并實現其_read()方法,或者在構造函數的第一個對象參數中實現read方法。
2.5.1. 工作機制

這里只畫了大致的流程,以及Readable流的模式轉換觸發條件。
其中:
needReadable(true): 暫停模式并且buffer數據<=hwm、綁定了readable事件監聽函數、read數據時緩沖區沒有數據或者返回數據為空
push: 如果處于流動模式,緩沖區里沒有數據會觸發'data'事件;否則將數據保存到緩沖區根據needReadable狀態觸發'readable'事件
read: 讀length=0長度的數據時,buffer中的數據已經到達hwm或者溢出需要觸發'readable'事件;從buffer中讀取數據并觸發'data'事件
resume: 有'readable'監聽,該方法不起作用;否則將流由暫停模式轉變為流動模式,并清空緩沖區里的數據
readable觸發條件:綁定了'readable'事件并且緩沖區里有數據、push數據時緩沖區有數據,并且needReadable === true、讀length=0長度的數據時,buffer中的數據已經到達hwm或者溢出。
關于“Node中的可讀流是什么”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Node中的可讀流是什么”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





