溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“C++如何實現xml解析器”,在日常操作中,相信很多人在C++如何實現xml解析器問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”C++如何實現xml解析器”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
<?xml version="1.0"?> <!--這是注釋--> <workflow> <work name="1" switch="on"> <plugin name="echoplugin.so" switch="on" /> </work> </workflow>
我們來簡單觀察下上面的xml文件,xml格式和html格式十分類似,一般用于存儲需要屬性的配置或者需要多個嵌套關系的配置。
xml一般使用于項目的配置文件,相比于其他的ini格式或者yaml格式,它的優勢在于可以將一個標簽擁有多個屬性,比如上述xml文件格式是用于配置工作流的,其中有name屬性和switch屬性,且再work標簽中又嵌套了plugin標簽,相比較其他配置文件格式是要靈活很多的。
具體的應用場景有很多,比如使用過Java中Mybatis的同學應該清楚,Mybatis的配置文件就是xml格式,而且也可以通過xml格式進行sql語句的編寫,同樣Java的maven項目的配置文件也是采用的xml文件進行配置。
而我為什么要寫一個xml解析器呢?很明顯,我今后要寫的C++項目需要用到。
同樣回到之前的那段代碼,實際上已經把xml文件格式的不同情況都列出來了。
從整體上看,所有的xml標簽分為:
xml聲明(包含版本、編碼等信息)
注釋
xml元素:1.單標簽元素。 2.成對標簽元素。
其中xml聲明和注釋都是非必須的。 而xml元素,至少需要一個成對標簽元素,而且在最外層有且只能有一個,它作為根元素。
從xml元素來看,分為:
名稱
屬性
內容
子節點
根據之前的例子,很明顯,名稱是必須要有的而且是唯一的,其他內容則是可選。 根據元素的結束形式,我們把他們分為單標簽和雙標簽元素。
完整代碼倉庫:xml-parser
代碼如下:
namespace xml
{
using std::vector;
using std::map;
using std::string_view;
using std::string;
class Element
{
public:
using children_t = vector<Element>;
using attrs_t = map<string, string>;
using iterator = vector<Element>::iterator;
using const_iterator = vector<Element>::const_iterator;
string &Name()
{
return m_name;
}
string &Text()
{
return m_text;
}
//迭代器方便遍歷子節點
iterator begin()
{
return m_children.begin();
}
[[nodiscard]] const_iterator begin() const
{
return m_children.begin();
}
iterator end()
{
return m_children.end();
}
[[nodiscard]] const_iterator end() const
{
return m_children.end();
}
void push_back(Element const &element)//方便子節點的存入
{
m_children.push_back(element);
}
string &operator[](string const &key) //方便key-value的存取
{
return m_attrs[key];
}
string to_string()
{
return _to_string();
}
private:
string _to_string();
private:
string m_name;
string m_text;
children_t m_children;
attrs_t m_attrs;
};
}上述代碼,我們主要看成員變量。
我們用string類型表示元素的name和text
用vector嵌套表示孩子節點
用map表示key-value對的屬性
其余的方法要么是Getter/Setter,要么是方便操作孩子節點和屬性。 當然還有一個to_string()方法這個待會講。
關于整體結構我們分解為下面的情形:
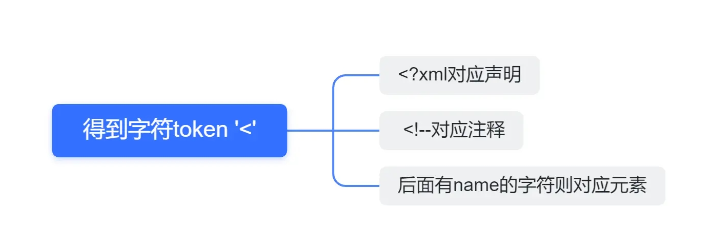
代碼如下:
Element xml::Parser::Parse()
{
while (true)
{
char t = _get_next_token();
if (t != '<')
{
THROW_ERROR("invalid format", m_str.substr(m_idx, detail_len));
}
//解析版本號
if (m_idx + 4 < m_str.size() && m_str.compare(m_idx, 5, "<?xml") == 0)
{
if (!_parse_version())
{
THROW_ERROR("version parse error", m_str.substr(m_idx, detail_len));
}
continue;
}
//解析注釋
if (m_idx + 3 < m_str.size() && m_str.compare(m_idx, 4, "<!--") == 0)
{
if (!_parse_comment())
{
THROW_ERROR("comment parse error", m_str.substr(m_idx, detail_len));
}
continue;
}
//解析element
if (m_idx + 1 < m_str.size() && (isalpha(m_str[m_idx + 1]) || m_str[m_idx + 1] == '_'))
{
return _parse_element();
}
//出現未定義情況直接拋出異常
THROW_ERROR("error format", m_str.substr(m_idx, detail_len));
}
}上述代碼我們用while循環進行嵌套的原因在于注釋可能有多個。
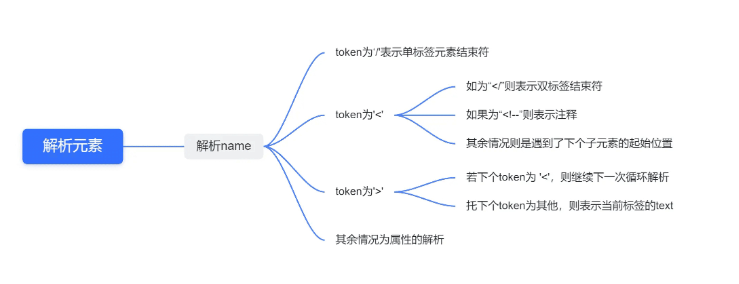
對應代碼:
Element xml::Parser::_parse_element()
{
Element element;
auto pre_pos = ++m_idx; //過掉<
//判斷name首字符合法性
if (!(m_idx < m_str.size() && (std::isalpha(m_str[m_idx]) || m_str[m_idx] == '_')))
{
THROW_ERROR("error occur in parse name", m_str.substr(m_idx, detail_len));
}
//解析name
while (m_idx < m_str.size() && (isalpha(m_str[m_idx]) || m_str[m_idx] == ':' ||
m_str[m_idx] == '-' || m_str[m_idx] == '_' || m_str[m_idx] == '.'))
{
m_idx++;
}
if (m_idx >= m_str.size())
THROW_ERROR("error occur in parse name", m_str.substr(m_idx, detail_len));
element.Name() = m_str.substr(pre_pos, m_idx - pre_pos);
//正式解析內部
while (m_idx < m_str.size())
{
char token = _get_next_token();
if (token == '/') //1.單元素,直接解析后結束
{
if (m_str[m_idx + 1] == '>')
{
m_idx += 2;
return element;
} else
{
THROW_ERROR("parse single_element failed", m_str.substr(m_idx, detail_len));
}
}
if (token == '<')//2.對應三種情況:結束符、注釋、下個子節點
{
//結束符
if (m_str[m_idx + 1] == '/')
{
if (m_str.compare(m_idx + 2, element.Name().size(), element.Name()) != 0)
{
THROW_ERROR("parse end tag error", m_str.substr(m_idx, detail_len));
}
m_idx += 2 + element.Name().size();
char x = _get_next_token();
if (x != '>')
{
THROW_ERROR("parse end tag error", m_str.substr(m_idx, detail_len));
}
m_idx++; //千萬注意把 '>' 過掉,防止下次解析被識別為初始的tag結束,實際上這個element已經解析完成
return element;
}
//是注釋的情況
if (m_idx + 3 < m_str.size() && m_str.compare(m_idx, 4, "<!--") == 0)
{
if (!_parse_comment())
{
THROW_ERROR("parse comment error", m_str.substr(m_idx, detail_len));
}
continue;
}
//其余情況可能是注釋或子元素,直接調用parse進行解析得到即可
element.push_back(Parse());
continue;
}
if (token == '>') //3.對應兩種情況:該標簽的text內容,下個標簽的開始或者注釋(直接continue跳到到下次循環即可
{
m_idx++;
//判斷下個token是否為text,如果不是則continue
char x = _get_next_token();
if (x == '<')//不可能是結束符,因為xml元素不能為空body,如果直接出現這種情況也有可能是中間夾雜了注釋
{
continue;
}
//解析text再解析child
auto pos = m_str.find('<', m_idx);
if (pos == string::npos)
THROW_ERROR("parse text error", m_str.substr(m_idx, detail_len));
element.Text() = m_str.substr(m_idx, pos - m_idx);
m_idx = pos;
//注意:有可能直接碰上結束符,所以需要continue,讓element里的邏輯來進行判斷
continue;
}
//4.其余情況都為屬性的解析
auto key = _parse_attr_key();
auto x = _get_next_token();
if (x != '=')
{
THROW_ERROR("parse attrs error", m_str.substr(m_idx, detail_len));
}
m_idx++;
auto value = _parse_attr_value();
element[key] = value;
}
THROW_ERROR("parse element error", m_str.substr(m_idx, detail_len));
}無論是C++開發,還是各種其他語言的造輪子,在這個造輪子的過程中,不可能是一帆風順的,需要不斷的debug,然后再測試,然后再debug。。。實際上這類格式的解析,單純的進行程序的調試效率是非常低下的!
特別是你用的語言還是C++,那么如果出現意外宕機行為,debug幾乎是不可能簡單的找出原因的,所以為了方便調試,或者是意外宕機行為,我們還是多做一些錯誤、異常處理的工作比較好。
比如上述的代碼中,我們大量的用到了 THROW_ERROR 這個宏,實際上這個宏輸出的內容是有便于調試和快速定位的。 具體代碼如下:
//用于返回較為詳細的錯誤信息,方便錯誤追蹤
#define THROW_ERROR(error_info, error_detail) \
do{ \
string info = "parse error in "; \
string file_pos = __FILE__; \
file_pos.append(":"); \
file_pos.append(std::to_string(__LINE__));\
info += file_pos; \
info += ", "; \
info += (error_info); \
info += "\ndetail:"; \
info += (error_detail);\
throw std::logic_error(info); \
}while(false)如果發生錯誤,這個異常攜帶的信息如下:

打印出了兩個非常關鍵的信息:
內部的C++代碼解析拋出異常的位置
解析發生錯誤的字符串
按理來說這些信息應該是用日志來進行記錄的,但是由于這個項目比較小型,直接用日常信息當日志來方便調試也未嘗不可????
眾所周知在C++中,一個類有八個默認函數:
默認構造函數
默認拷貝構造函數
默認析構函數
默認重載賦值運算符函數
默認重載取址運算符函數
默認重載取址運算符const函數
默認移動構造函數(C++11)
默認重載移動賦值操作符函數(C++11)
我們一般情況需要注意的構造函數和賦值函數函數需要的是以下三類:
拷貝構造。
移動構造。
析構函數。
以下面的代碼為例來說明默認的行為:
class Data{
...
}
class test{
pvivate:
Data m_data;
}默認情況的模擬
class Data{
...
}
class test{
public:
//拷貝構造
test(test const&src) = default;//等價于下面的代碼
//test(test const& src):m_data(src.m_data){}
//移動構造
test(test &&src) = default;//等價于下面代碼
//tset(test&& src):m_data(std::move(src.m_data)){}
pvivate:
Data m_data;
}從上述情況可以看出,如果一個類的數據成員中含有原始指針數據,那么拷貝構造和移動構造都需要自定義,如果成員中全都用的標準庫里的東西,那么我們就用默認的就行,因為標準庫的所有成員都自己實現了拷貝和移動構造!比如我們目前的Element就全都用默認的就好。
需要特別注意的點
顯式定義了某個構造函數或者賦值函數,那么相應的另一個構造或者賦值就會被刪除默認,需要再次顯式定義了。 舉個例子:比如我顯式定義了移動構造(關于顯式定義,手動創建算顯式,手動寫default也算顯示),那么就會造成所有的默認拷貝(拷貝構造和拷貝賦值)被刪除。相反顯式定義了移動賦值也是類似的,默認的拷貝行為被刪除。拷貝的對于顯式的默認行為處理也是一模一樣。
如果想要使用默認的構造/賦值函數,那么對應的成員也都必須支持。 例如以下代碼:
class Data{
...
}
class test{
pvivate:
Data m_data;
}由于test類沒有寫任何構造函數,那么這8個默認構造函數按理來說都是有的,但如果Data類中的拷貝構造由于某些顯式定義情況而被刪除了,那么test類就不再支持拷貝構造(對我們造成的影響就是:沒法再直接通過等號初始化)。
最后,通過上述規則我們發現,如果想要通過默認的構造函數偷懶,那么首先你的成員得支持對應的構造函數,還有就是不要畫蛇添足:比如本來我什么都不用寫,它自動生成8大默認函數,然后你手寫了一個拷貝構造=default,好了,你的默認函數從此少了兩個,又得你一個個手動去補了!
故如果成員變量對移動和拷貝行為都是支持的,那么你就千萬不要再畫蛇添足了,除非你需要自定義某些特殊行為(比如打日志什么的)。如果你的成員變量中含有原始指針,那么一定需要手動寫好移動和拷貝行為。如果成員變量對拷貝和移動行為部分支持,那么根據你的使用情況來進行選擇是否需要手動補充這些行為!
到此,關于“C++如何實現xml解析器”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





