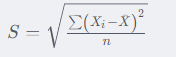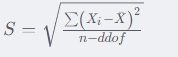溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Pandas中Series的屬性,方法,常用操作使用實例分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
包的引入:
import numpy as np import pandas as pd
s = pd.Series() print(s) print(type(s))

需要傳入一個列表序列
l = [1, 2, 3, 4]
s = pd.Series(l)
print(s)
print('-'*20)
print(type(s))
需要傳入一個元組序列
t = (1, 2, 3)
s = pd.Series(t)
print(s)
print('-'*20)
print(type(s))
需要傳入一個字典
m = {'zs': 12, 'ls': 23, 'ww': 22}
s = pd.Series(m)
print(s)
print('-'*20)
print(type(s))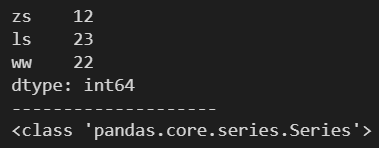
需要傳入一個 ndarray
ndarr = np.array([1, 2, 3])
s = pd.Series(ndarr)
print(s)
print('-'*20)
print(type(s))
index:用于設置 Series 對象的索引
age = [12, 23, 22, 34]
name = ['zs', 'ls', 'ww', 'zl']
s = pd.Series(age, index=name)
print(s)
print('-'*20)
print(type(s))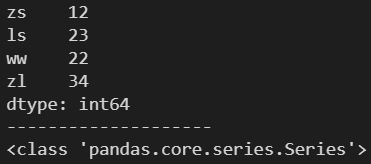
num = 999
s = pd.Series(num, index=[1, 2, 3, 4])
print(s)
print('-'*20)
print(type(s))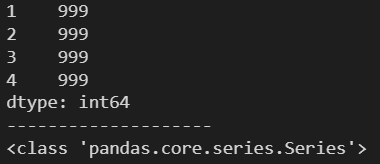
ndarr = np.arange(0, 10, 2)
s = pd.Series(5, index=ndarr)
print(s)
print('-'*20)
print(type(s))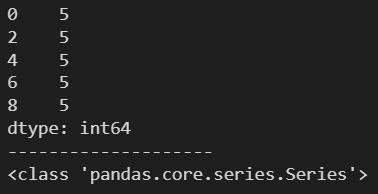
l = [11, 22, 33, 44]
s = pd.Series(l)
print(s)
print('-'*20)
ndarr = s.values
print(ndarr)
print('-'*20)
print(type(ndarr))
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
idx = s.index
print(idx)
print('-'*20)
print(type(idx))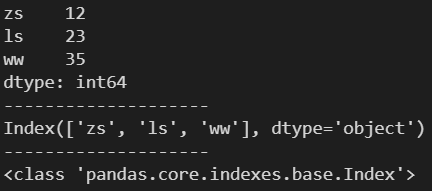
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.dtype)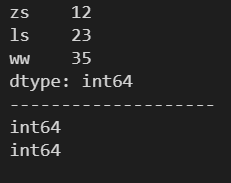
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.size)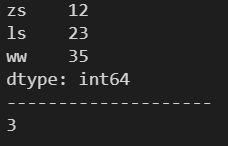
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.ndim)
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.ndim)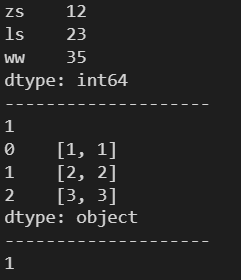
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.shape)
print()
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.shape)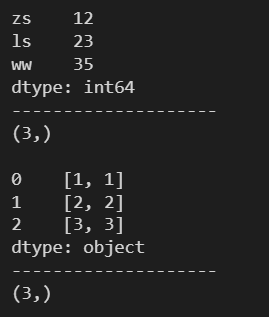
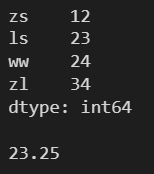
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.mean())
l1 = [12, 23, 24, 34] s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s1) print() print(s1.max()) print(s1.min()) print() l2 = ['ac', 'ca', 'cd', 'ab'] s2 = pd.Series(l2) print(s2) print() print(s2.max()) print(s2.min())
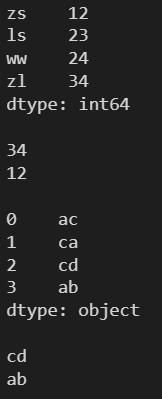
l1 = [12, 23, 24, 34] s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s1) print() # argmax() -- 最大值的數字索引 # idxmax() -- 最大值的標簽索引 # 兩個都不支持字符串類型的數據 print(s1.max(), s1.argmax(), s1.idxmax()) print(s1.min(), s1.argmin(), s1.idxmin())
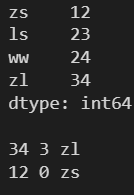
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.median())
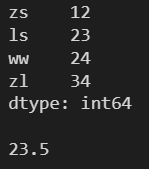
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.value_counts())

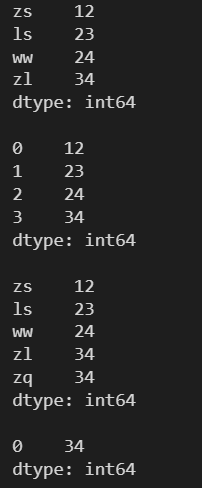
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.mode()) print() l = [12, 23, 24, 34, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl', 'zq']) print(s) print() print(s.mode())
四分位數:把數值從小到大排列并分成四等分,處于三個分割點位置的數值就是四分位數。
需要傳入一個列表,列表中的元素為要獲取的數的對應位置
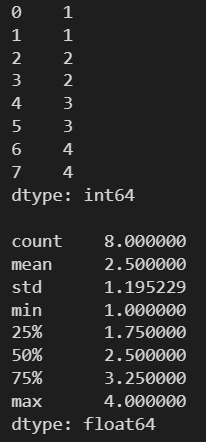
l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() print(s.quantile([0, .25, .50, .75, 1]))
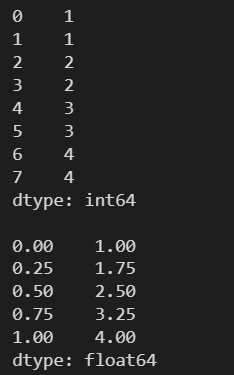
總體標準差是反映研究總體內個體之間差異程度的一種統計指標。
總體標準差計算公式:
由于總體標準差計算出來會偏小,所以采用 ( n − d d o f ) (n-ddof) (n−ddof)的方式適當擴大標準差,即樣本標準差。
樣本標準差計算公式:
l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() # 總體標準差 print(s.std()) print() print(s.std(ddof=1)) print() # 樣本標準差 print(s.std(ddof=2))
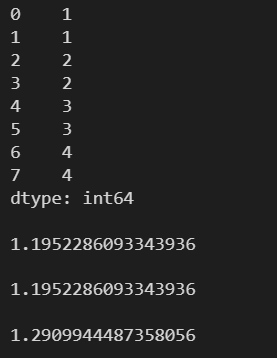
l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() print(s.describe())
ascending:True為升序(默認),False為降序 3.10.1 升序
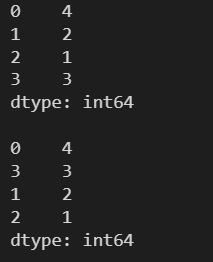
l = [4, 2, 1, 3] s = pd.Series(l) print(s) print() s = s.sort_values() print(s)
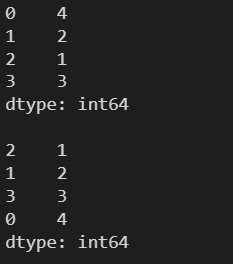
l = [4, 2, 1, 3] s = pd.Series(l) print(s) print() s = s.sort_values(ascending=False) print(s)
ascending:True為升序(默認),False為降序
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s = s.sort_index() print(s)
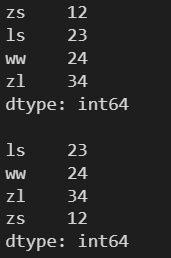
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s = s.sort_index() print(s)
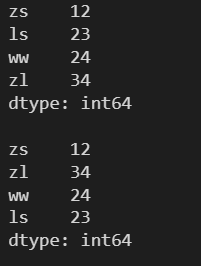
需要傳入一個函數參數
# x 為當前遍歷到的元素 def func(x): if (x%2==0): return x+1 else: return x l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 調用 apply 方法,會將 Series 中的每個元素帶入 func 函數中進行處理 s = s.apply(func) print(s)
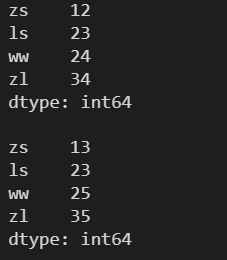
對象的前 x 個元素 需要傳入一個數 x ,表示查看前 x 個元素,默認為前5個
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # head(x) 查看 Series 對象的前 x 個元素 print(s.head(2))
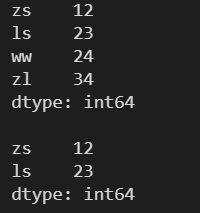
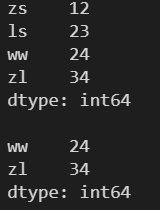
需要傳入一個數 x ,表示查看后 x 個元素,默認為后5個
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # tail(x) 查看 Series 對象的后 x 個元素 print(s.tail(2))
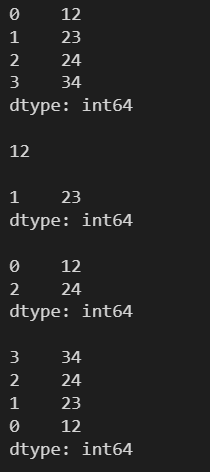
l = [12, 23, 24, 34] s = pd.Series(l) print(s) print() print(s[0]) print() print(s[1:-2]) print() print(s[::2]) print() print(s[::-1])
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s[0]) print() print(s[1:-2]) print() print(s[::2]) print() print(s[::-1])
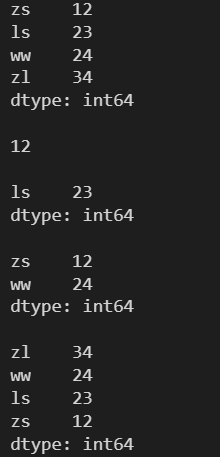
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s['zs']) print() # 自定義標簽索引進行切片包含開始與結束位置 print(s['ls':'zl']) print() print(s['zs':'zl':2]) print() # 注意切邊范圍的方向與步長的方向 print(s['zl':'zs':-1])
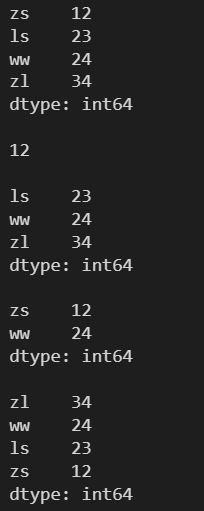
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() idx = (s%2==0) print(idx) print() # 索引掩碼(也是一個數組) # 索引掩碼個數與原數組的個數一致,數組每個元素都與索引掩碼中的元素一一對應 # 數組每個元素都對應著索引掩碼中的一個True或False # 只有索引掩碼中為True所對應元素組中的元素才會被選中 print(s[idx])
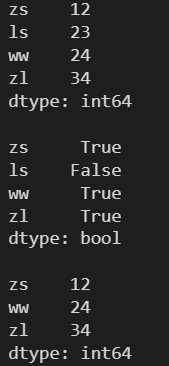
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 選出指定索引對應的元素 print(s[['zs', 'ww']]) print() print(s[[1, 2]])

傳入要刪除元素的標簽索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s.pop('ww')
print(s)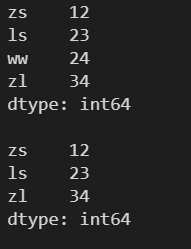
傳入要刪除元素的標簽索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# drop() 會返回一個刪除元素后的新數組,不會對原數組進行修改
s = s.drop('zs')
print(s)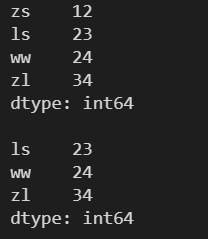
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s['zs'] = 22 print(s)
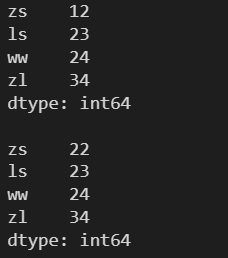
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s[1] = 22 print(s)
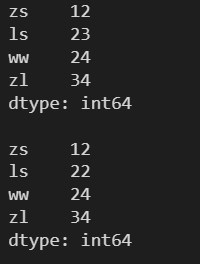
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s['ll'] = 22 print(s)
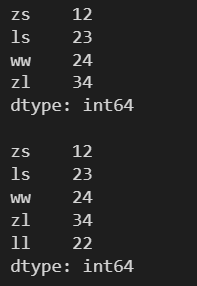
需要傳入一個要添加到原 Series 對象的 Series 對象
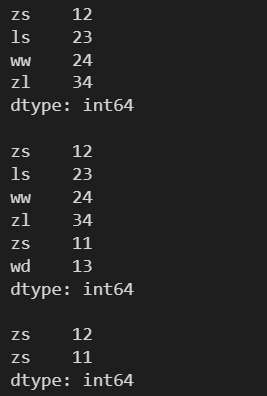
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 可以添加已經存在的索引及其值 s2 = pd.Series([11, 13], index=['zs', 'wd']) # append() 不會對原數組進行修改 s = s.append(s2) print(s) print() print(s['zs'])
以上就是“Pandas中Series的屬性,方法,常用操作使用實例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。