溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么使用Node.js開發一個簡單圖片爬取功能”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“怎么使用Node.js開發一個簡單圖片爬取功能”文章能幫助大家解決問題。

node-crawler 是一個輕量級的 node.js 爬蟲工具,兼顧了高效與便利性,支持分布式爬蟲系統,支持硬編碼,支持http前級代理。而且,它完全是由 nodejs 寫成,天生支持非阻塞異步IO,為爬蟲的流水線作業機制提供了極大便利。同時支持對 DOM 的快速選擇(可以使用 jQuery 語法),對于抓取網頁的特定部分的任務可以說是殺手級功能,無需再手寫正則表達式,提高爬蟲開發效率。
我們先新建一個項目,在里面創建index.js作為入口文件。
然后進行爬蟲庫 node-crawler 的安裝。
# PNPM pnpm add crawler # NPM npm i -S crawler # Yarn yarn add crawler
然后用過 require 引入進去。
// index.js
const Crawler = require("crawler");// index.js
let crawler = new Crawler({
timeout:10000,
jQuery:true,
})
function getImages(uri) {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) throw err;
}
})
}從現在我們將開始寫一個拿到html頁面的圖片的方法,crawler 實例化后,在其隊列中主要是為了寫入鏈接和回調方法。在每個請求處理完畢后將調這個回調函數。
這里還要說明一下, Crawler 使用了 request 庫,所以 Crawler 可供配置的參數列表是 request 庫的參數的超集,即 request 庫中所有的配置在 Crawler 中均適用。
剛才或許你也看到了 jQuery 這個參數,你猜的沒錯,它可以使用 jQuery 的語法去捕獲 DOM 元素的。
// index.js
let data = []
function getImages(uri) {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) throw err;
let $ = res.$;
try {
let $imgs = $("img");
Object.keys($imgs).forEach(index => {
let img = $imgs[index];
const { type, name, attribs = {} } = img;
let src = attribs.src || "";
if (type === "tag" && src && !data.includes(src)) {
let fileSrc = src.startsWith('http') ? src : `https:${src}`
let fileName = src.split("/")[src.split("/").length-1]
downloadFile(fileSrc, fileName) // 下載圖片的方法
data.push(src)
}
});
} catch (e) {
console.error(e);
done()
}
done();
}
})
}可以看到剛才通過 $ 來完成對請求中 img 標簽的捕獲。然后我們下面的邏輯去處理補全圖片的鏈接和剝離出名字為了后面可以保存取名用。這里還定義了一個數組,它的目的是保存已經捕獲到的圖片地址,如果下次捕獲發現同一個圖片地址,那么就不再重復處理下載了。
以下是掘金首頁html用 $("img") 捕獲到的信息打印:
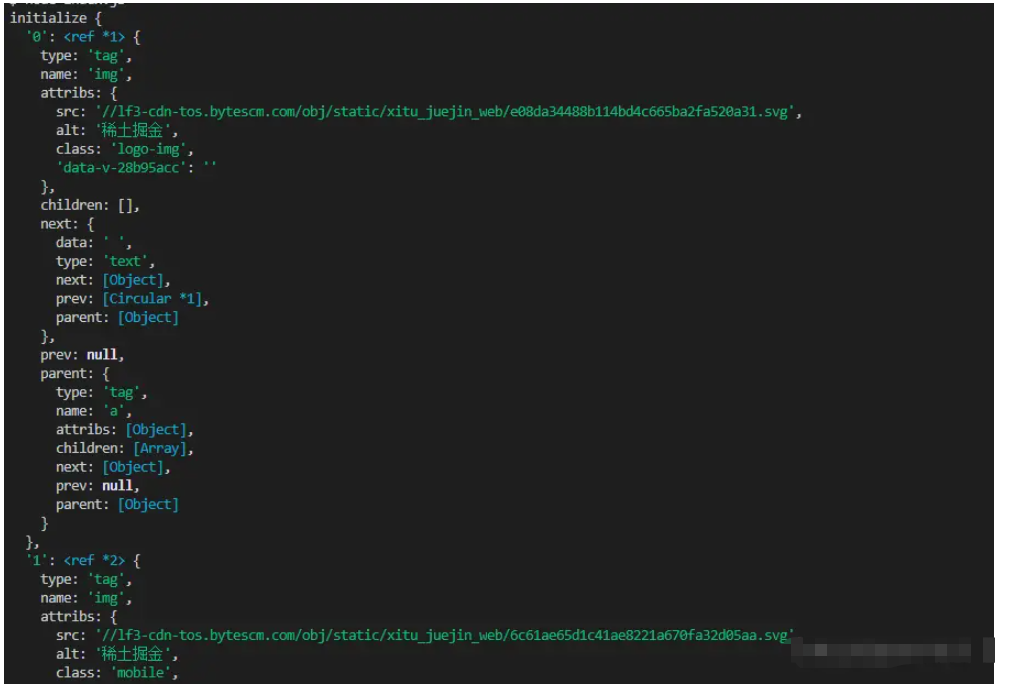
下載圖片
下載之前我們還要安裝一個 nodejs 包—— axios ,是的你沒看錯,axios 不僅提供給前端,它也可以給后端去使用。但是因為下載圖片要把它處理成數據流,所以把 responseType 設置成 stream 。然后才可以用 pipe 方法保存數據流文件。
const { default: axios } = require("axios");
const fs = require('fs');
async function downloadFile(uri, name) {
let dir = "./imgs"
if (!fs.existsSync(dir)) {
await fs.mkdirSync(dir)
}
let filePath = `${dir}/${name}`
let res = await axios({
url: uri,
responseType: 'stream'
})
let ws = fs.createWriteStream(filePath)
res.data.pipe(ws)
res.data.on("close",()=>{
ws.close();
})
}因為可能圖片很多,所以要統一放在一個文件夾下,就要判斷有沒有這個文件夾如果沒有就創建一個。然后通過 createWriteStream 方法來把獲取到的數據流以文件的形式保存到文件夾里面。
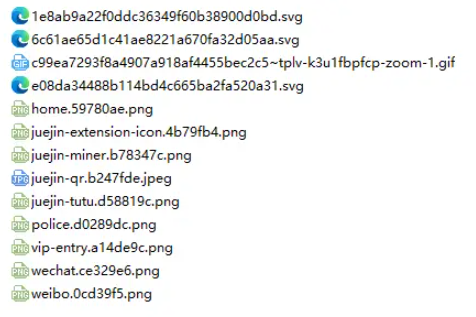
然后我們可以嘗試一下,比如我們捕獲用一下掘金首頁html下的圖片:
// index.js
getImages("https://juejin.cn/")執行后發現就可以發現已經捕獲到靜態html里面的所有圖片了。
node index.js
關于“怎么使用Node.js開發一個簡單圖片爬取功能”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





