溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何爬取動漫圖片,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討方法吧!
話不多說,直接上完整代碼
import requests as r
import re
import os
import time
file_name = "動漫截圖"
if not os.path.exists(file_name):
os.mkdir(file_name)
for p in range(1,34):
print("--------------------正在爬取第{}頁內容------------------".format(p))
url = 'https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers = {"user-agent"
: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
resp = r.get(url, headers=headers)
html = resp.text
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)
#print(images)
#print(names)
dic = dict(zip(images, names))
for image in images:
time.sleep(1)
print(image, dic[image])
name = dic[image]
#name = image.split('/')[-1]
i = r.get(image, headers=headers).content
try:
with open(file_name + '/' + name + '.jpg' , 'wb') as f:
f.write(i)
except FileNotFoundError:
continue先導入要使用的庫
import requests as r import re import os import time
然后去分析要去爬的網址: 動漫截圖網
下圖是網址的內容: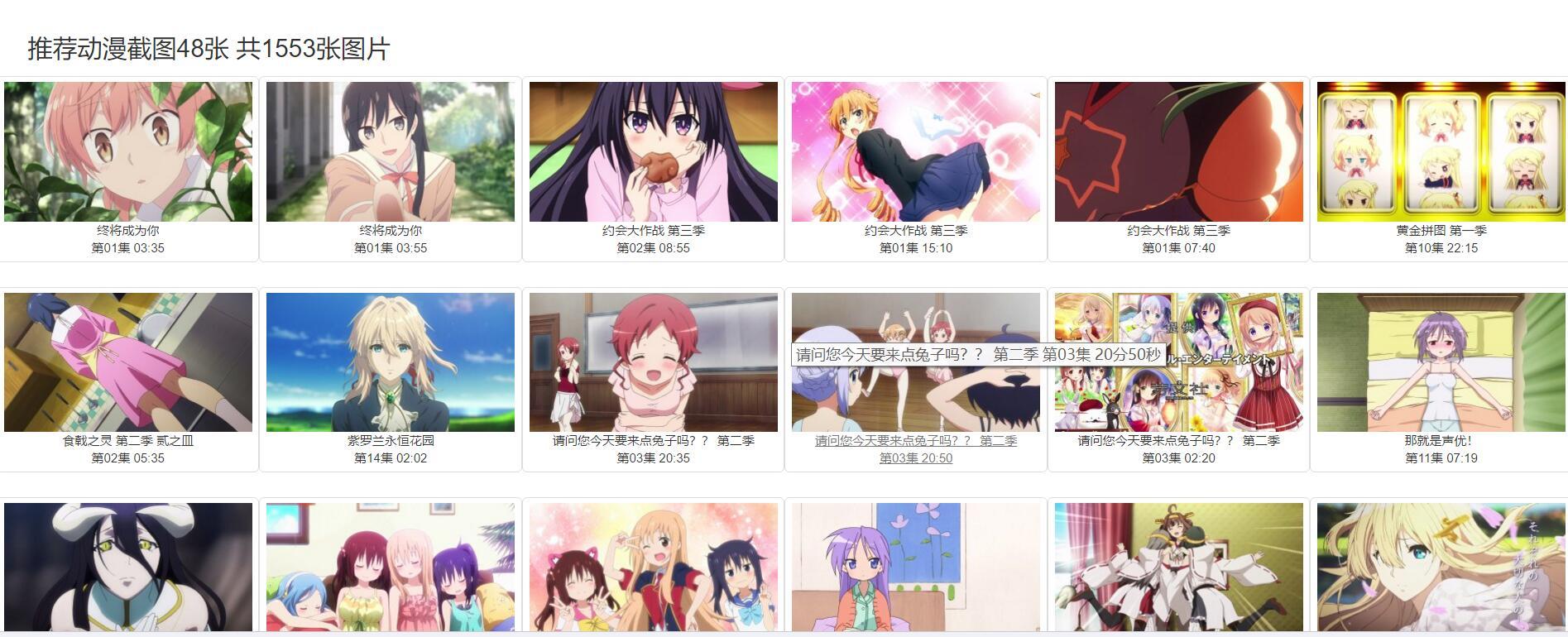
好了 url已經確定
下面去尋找headers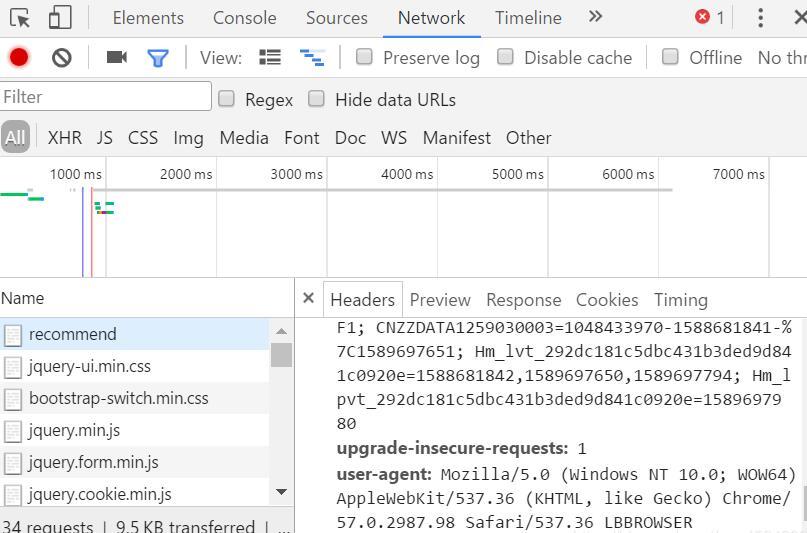
找到下面是代碼展示
url = 'https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers = {"user-agent"
: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"
}然后檢索要爬的圖片內容

從上圖就可以找到圖片的位置:data-origina=后面的內容
以及圖片的名字:title=后面的內容
然后用正則表達式re來檢索就行了
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)最后將其保存就好了
i = r.get(image, headers=headers).content with open(file_name + '/' + name + '.jpg' , 'wb') as f: f.write(i)
然后將page后面的數字改動就可以跳到相應的頁面
換頁的問題也就解決了
or p in range(1,34):
url = 'https://www.acgimage.com/shot/recommend?page={}'.format(p)以及將爬到的圖片放到自己建立的文件zh
使用了os庫
file_name = "動漫截圖" if not os.path.exists(file_name): os.mkdir(file_name)
看完了這篇文章,相信你對如何爬取動漫圖片有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





