溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“如何利用Python實現模擬登錄知乎”,內容詳細,步驟清晰,細節處理妥當,希望這篇“如何利用Python實現模擬登錄知乎”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
在抓包的時候,開始使用的是Chrome開發工具中的Network,結果沒有抓到,后來使用Fiddler成功抓取數據。下面逐步來細化上述過程。
模擬知乎登錄前,先看看本次案例使用的環境及其工具:
Windows 7 + Python 2.75
Chrome + Fiddler: 用來監控客戶端與服務器的通訊情況,以及查找相關參數的位置。
使用Google瀏覽器結合Fiddler來監控客戶端與服務端的通訊過程;
根據監控結果,構造請求服務器過程中傳遞的參數;
使用Python模擬參數傳遞過程。
客戶端與服務端通信過程的幾個關鍵點:
登錄時的url地址。
登錄時提交的參數【params】,獲取方式主要有兩種:第一、分析頁面源代碼,找到表單標簽及屬性。適應比較簡單的頁面。第二、使用抓包工具,查看提交的url和參數,通常使用的是Chrome的開發者工具中的Network, Fiddler等。
登錄后跳轉的url。
首先看看這個登錄頁面,也就是我們登錄時的url地址。
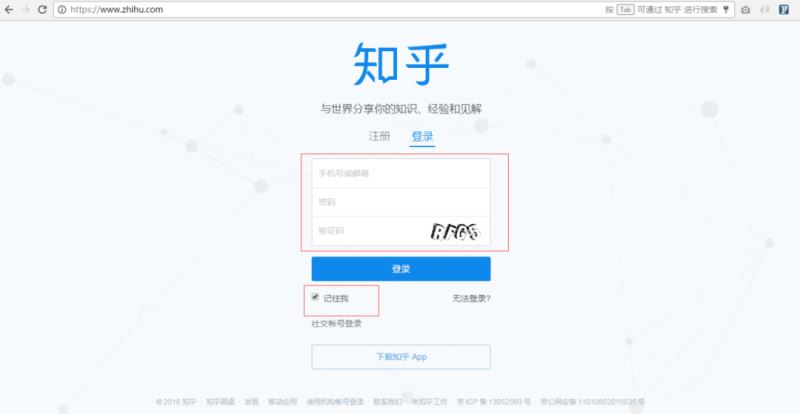
看到這個頁面,我們也可以大概猜測下請求服務器時傳遞了幾個字段,很明顯有:用戶名、密碼、驗證碼以及“記住我”這幾個值。那么實際上有哪些呢?下面來分分析下。
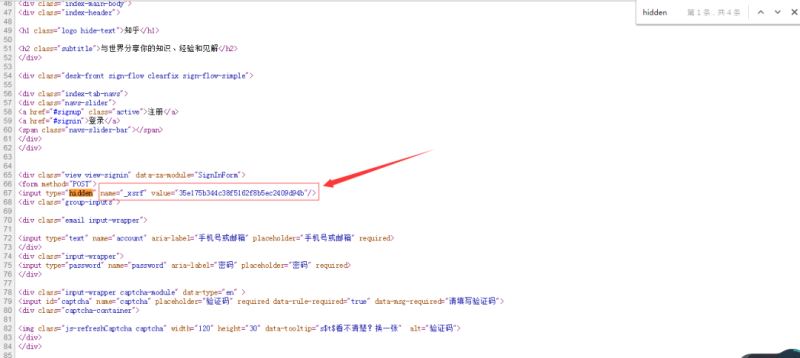
首先查看一下HTML源碼,Google里可以使用CTRL+U查看,然后使用CTRL+F輸入input看看有哪些字段值,詳情如下:
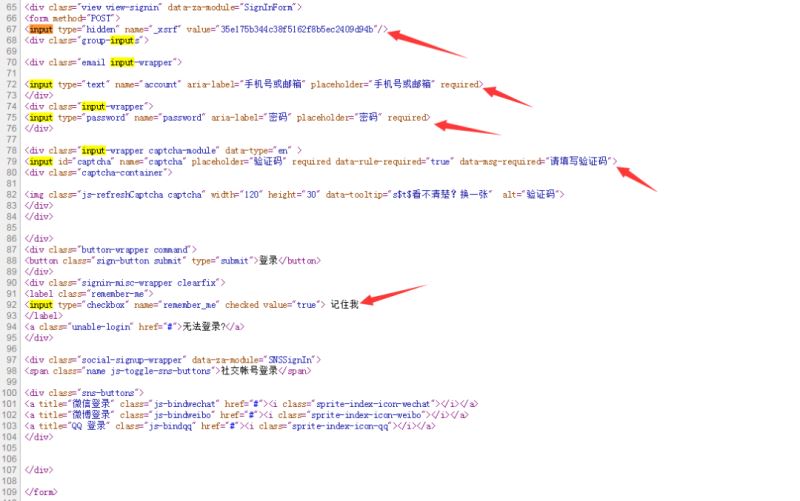
通過源碼,我們可以看到,在請求服務器的過程中還攜帶了一個隱藏字段”_xsrf”。那么現在的問題是:這些參數在傳遞時是以什么名字傳遞的呢?這就需要借用其他工具抓包進行分析了。筆者是Windows系統,這里使用的是Fiddler(當然,你也可以使用其他的)。
抓包過程比較繁瑣,因為抓到的東西比較多,很難快速的找到需要的信息。關于fiddler,很容易使用,有過不會,可以去百度搜一下。為了防止其他信息干擾,我們先將fiddler中的記錄清除,然后輸入用戶名(筆者使用的是郵箱登錄)、密碼等信息登錄,相應的在fiddler中會有如下結果:
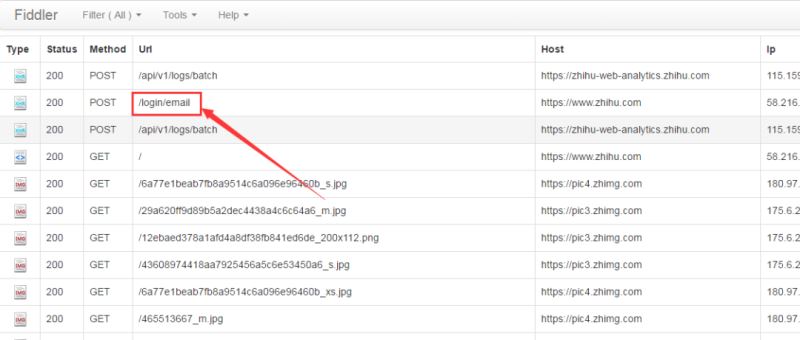
備注:如果是使用手機登錄,則對應fiddler中的url是“/login/phone_num”。
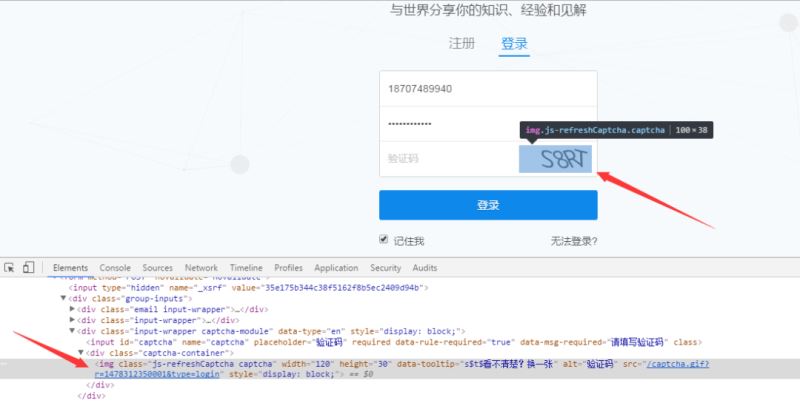
為了查看詳細的請求參數,我們左鍵單機“/login/email”,可以看到下列信息:
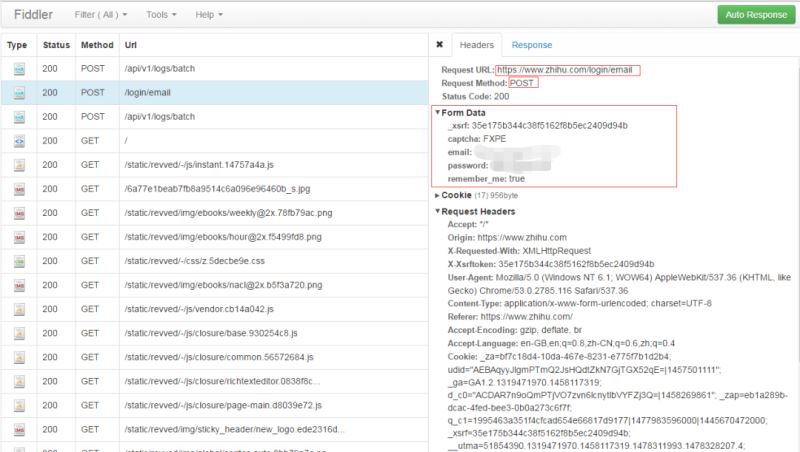
請求方式為POST,請求的url為https://www.zhihu.com/login/email。而從From Data可以看出,相應的字段名稱如下:
_xsrf
captcha
password
remember
對于這五個字段,代碼中email、password以及captcha都是手動輸入的,remember初始化為true。剩下的_xsrf則可以根據登錄頁面的源文件,取input為_xsrf的value值即可。
對于驗證碼,則需要通過額外的請求,該鏈接可以通過定點查看源碼看出:
鏈接為https://www.zhihu.com/captcha.gif?type=login,這里省略了ts(經測試,可省略掉)。現在,可以使用代碼進行模擬登錄。
溫馨提示:如果使用的是手機號碼進行登錄,則請求的url為https://www.zhihu.com/login/phone_num,同時email字段名稱將變成“phone_num”。
在編寫代碼實現知乎登錄的過程中,筆者將一些功能封裝成了一個簡單的類WSpider,以便復用,文件名稱為WSpider.py。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 14:01:17 2016
@author: liudiwei
"""
import urllib
import urllib2
import cookielib
import logging
class WSpider(object):
def __init__(self):
#init params
self.url_path = None
self.post_data = None
self.header = None
self.domain = None
self.operate = None
#init cookie
self.cookiejar = cookielib.LWPCookieJar()
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookiejar))
urllib2.install_opener(self.opener)
def setRequestData(self, url_path=None, post_data=None, header=None):
self.url_path = url_path
self.post_data = post_data
self.header = header
def getHtmlText(self, is_cookie=False):
if self.post_data == None and self.header == None:
request = urllib2.Request(self.url_path)
else:
request = urllib2.Request(self.url_path, urllib.urlencode(self.post_data), self.header)
response = urllib2.urlopen(request)
if is_cookie:
self.operate = self.opener.open(request)
resText = response.read()
return resText
"""
Save captcha to local
"""
def saveCaptcha(self, captcha_url, outpath, save_mode='wb'):
picture = self.opener.open(captcha_url).read() #用openr訪問驗證碼地址,獲取cookie
local = open(outpath, save_mode)
local.write(picture)
local.close()
def getHtml(self, url):
page = urllib.urlopen(url)
html = page.read()
return html
"""
功能:將文本內容輸出至本地
@params
content:文本內容
out_path: 輸出路徑
"""
def output(self, content, out_path, save_mode="w"):
fw = open(out_path, save_mode)
fw.write(content)
fw.close()
"""#EXAMPLE
logger = createLogger('mylogger', 'temp/logger.log')
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
"""
def createLogger(self, logger_name, log_file):
# 創建一個logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
# 創建一個handler,用于寫入日志文件
fh = logging.FileHandler(log_file)
# 再創建一個handler,用于輸出到控制臺
ch = logging.StreamHandler()
# 定義handler的輸出格式formatter
formatter = logging.Formatter('%(asctime)s | %(name)s | %(levelname)s | %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 給logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
return logger關于模擬登錄知乎的源碼,保存在zhiHuLogin.py文件,內容如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 17:07:17 2016
@author: liudiwei
"""
import urllib
from WSpider import WSpider
from bs4 import BeautifulSoup as BS
import getpass
import json
import WLogger as WLog
"""
2016.11.03 由于驗證碼問題暫時無法正常登陸
2016.11.04 成功登錄,期間出現下列問題
驗證碼錯誤返回:{ "r": 1, "errcode": 1991829, "data": {"captcha":"驗證碼錯誤"}, "msg": "驗證碼錯誤" }
驗證碼過期:{ "r": 1, "errcode": 1991829, "data": {"captcha":"驗證碼回話無效 :(","name":"ERR_VERIFY_CAPTCHA_SESSION_INVALID"}, "msg": "驗證碼回話無效 :(" }
登錄:{"r":0, "msg": "登錄成功"}
"""
def zhiHuLogin():
spy = WSpider()
logger = spy.createLogger('mylogger', 'temp/logger.log')
homepage = r"https://www.zhihu.com/"
html = spy.opener.open(homepage).read()
soup = BS(html, "html.parser")
_xsrf = soup.find("input", {'type':'hidden'}).get("value")
#根據email和手機登陸得到的參數名不一樣,email登陸傳遞的參數是‘email',手機登陸傳遞的是‘phone_num'
username = raw_input("Please input username: ")
password = getpass.getpass("Please input your password: ")
account_name = None
if "@" in username:
account_name = 'email'
else:
account_name = 'phone_num'
#保存驗證碼
logger.info("save captcha to local machine.")
captchaURL = r"https://www.zhihu.com/captcha.gif?type=login" #驗證碼url
spy.saveCaptcha(captcha_url=captchaURL, outpath="temp/captcha.jpg") #temp目錄需手動創建
#請求的參數列表
post_data = {
'_xsrf': _xsrf,
account_name: username,
'password': password,
'remember_me': 'true',
'captcha':raw_input("Please input captcha: ")
}
#請求的頭內容
header ={
'Accept':'*/*' ,
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest',
'Referer':'https://www.zhihu.com/',
'Accept-Language':'en-GB,en;q=0.8,zh-CN;q=0.6,zh;q=0.4',
'Accept-Encoding':'gzip, deflate, br',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Host':'www.zhihu.com'
}
url = r"https://www.zhihu.com/login/" + account_name
spy.setRequestData(url, post_data, header)
resText = spy.getHtmlText()
jsonText = json.loads(resText)
if jsonText["r"] == 0:
logger.info("Login success!")
else:
logger.error("Login Failed!")
logger.error("Error info ---> " + jsonText["msg"])
text = spy.opener.open(homepage).read() #重新打開主頁,查看源碼可知此時已經處于登錄狀態
spy.output(text, "out/home.html") #out目錄需手動創建
if __name__ == '__main__':
zhiHuLogin()關于源碼的分析,可以參考代碼中的注解。
在控制臺中運行python zhiHuLogin.py,然后按提示輸入相應的內容,最后可得到以下不同的結果(舉了三個實例):



讀到這里,這篇“如何利用Python實現模擬登錄知乎”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





