溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么用Python與AI分析時間序列數據”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么用Python與AI分析時間序列數據”吧!
時間序列數據表示一系列特定時間內的數據間隔.如果我們想在機器學習中構建序列預測,那么我們必須處理順序數據和時間.系列數據是順序數據的摘要.數據排序是序列數據的一個重要特征.
序列分析或時間序列分析是基于先前觀察到的,在給定輸入序列中預測下一個.預測可以是下一個可能出現的任何事情:符號,數字,次日天氣,下一個語音等.序列分析在股票市場分析,天氣預報和產品推薦等應用中非常方便.
示例
請考慮以下示例來了解序列預測.這里A,B,C,D是給定值,您必須使用序列預測模型預測值E.

用于時間序列數據分析使用Python,我們需要安裝以下軟件包 :
Pandas是一個開源的BSD許可庫,提供高性能,易于使用的數據結構和Python數據分析工具.您可以使用以下命令安裝Pandas :
pip install pandas
如果您使用的是Anaconda并希望使用conda包管理器進行安裝,那么您可以使用以下命令 :
conda install -c anaconda pandas
這是一個開源的BSD -licensed庫,由簡單的算法和模型組成,用于學習Python中的隱馬爾可夫模型(HMM).你可以在以下命令的幫助下安裝它 :
pip install hmmlearn
如果您使用的是Anaconda并希望使用conda包管理器進行安裝,那么您可以使用以下命令 :
conda install -c omnia hmmlearn
這是一個結構化學習,預測庫.在PyStruct中實現的學習算法具有諸如條件隨機場(CRF),最大邊緣馬爾可夫隨機網絡(M3N)或結構支持向量機之類的名稱.你可以借助以下命令安裝它 :
pip install pystruct
它用于基于Python編程語言的凸優化.它也是一個免費的軟件包.您可以使用以下命令和減號安裝它;
pip install cvxopt
如果您使用的是Anaconda并希望使用conda軟件包管理器進行安裝,那么您可以使用以下命令 :
conda install -c anaconda cvdoxt
如果您必須使用時間序列數據,Pandas是一個非常有用的工具.在Pandas的幫助下,您可以執行以下 :
使用創建一系列日期pd.date_rangepackage
使用pd.Series包索引帶有日期的pandas
使用ts.resample包進行重新采樣
更改頻率
以下示例顯示您使用以下方式處理和切片時間序列數據大熊貓.請注意,這里我們使用的是每月北極濤動數據,可以從 monthly.ao.index.b50.current.ascii ,可以轉換為文本格式供我們使用.
對于處理時間序列數據,您必須執行以下步驟 :
第一步涉及導入以下包 :
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下來,定義一個函數,它將從輸入文件中讀取數據,如下面給出的代碼所示 :
def read_data(input_file): input_data = np.loadtxt(input_file, delimiter = None)
現在,將此數據轉換為時間序列.為此,請創建我們時間序列的日期范圍.在這個例子中,我們保留一個月的數據頻率.我們的文件的數據從1950年1月開始.
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')在這一步中,我們在Pandas系列的幫助下創建時間序列數據,如下圖所示 :
output = pd.Series(input_data[:, index], index = dates) return output if __name__=='__main__':
輸入輸入文件的路徑,如下所示 :
input_file = "/Users/admin/AO.txt"
現在,將列轉換為時間序列格式,如下所示 :
timeseries = read_data(input_file)
最后,使用顯示和減去的命令繪制和可視化數據;
plt.figure() timeseries.plot() plt.show()
您將觀察到如下圖所示的圖形 :
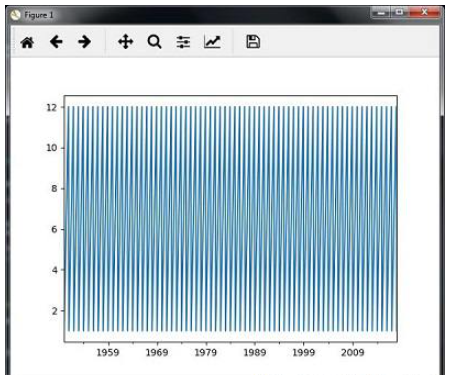
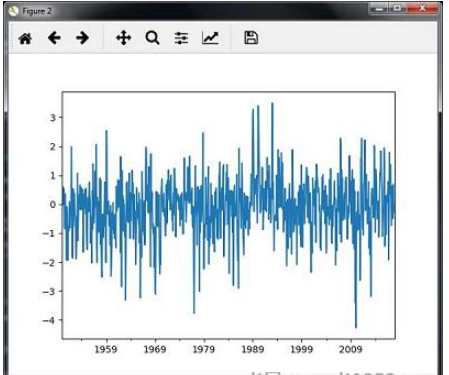
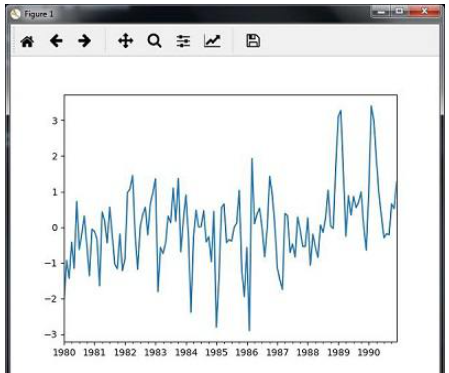
切片只涉及檢索時間序列數據的某些部分.作為示例的一部分,我們僅從1980年到1990年對數據進行切片.觀察執行此任務的以下代碼 :
timeseries['1980':'1990'].plot() <matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00> plt.show()
當您運行切片時間序列數據的代碼時,您可以將以下圖表視為圖中顯示的是 :
如果需要得出一些重要結論,則必須從給定數據中提取一些統計數據.平均值,方差,相關性,最大值和最小值是一些此類統計數據.如果要從給定的時間序列數據中提取此類統計數據,可以使用以下代碼;
您可以使用mean()函數,用于查找均值,如此處所示 :
timeseries.mean()
然后,您將針對所討論的示例觀察到的輸出是 :
-0.11143128165238671
您可以使用max()功能查找最大值,如下所示 :
timeseries.max()
然后,您將針對所討論的示例觀察到的輸出是 :
3.4952999999999999
您可以使用min()函數查找最小值,如下所示 :
timeseries.min()
然后,您將針對所討論的示例觀察到的輸出是 :
-4.2656999999999998
如果您想一次計算所有統計數據,可以使用describe()函數,如下所示 :
timeseries.describe()
然后,您將針對所討論的示例觀察到的輸出是 :
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64
您可以將數據重新采樣到不同的時間頻率.執行重新采樣的兩個參數是 :
時間段
方法
您可以使用以下代碼使用mean()重新采樣數據方法,這是默認方法 :
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()然后,您可以觀察以下圖表作為重采樣的輸出使用mean() :
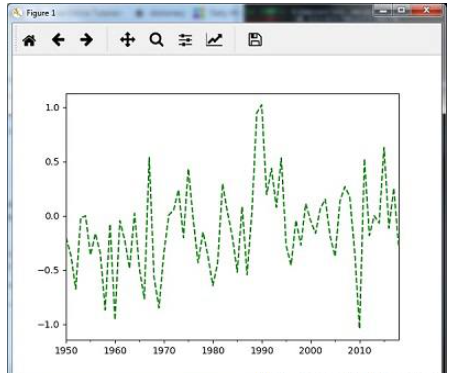
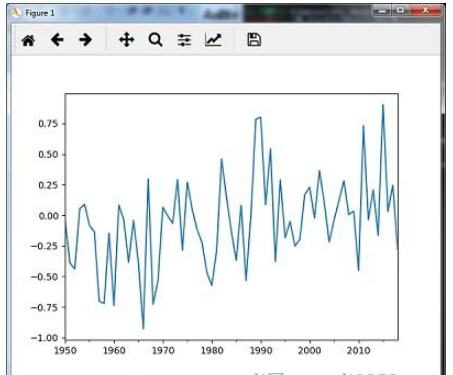
您可以使用以下代碼使用median()方法重新取樣數據 :
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()然后,您可以觀察下圖作為重新采樣的輸出,其中位數為() :
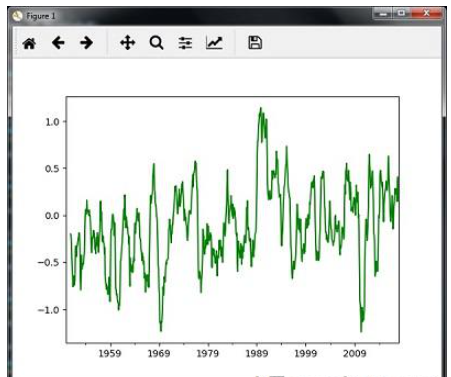
您可以使用以下代碼計算滾動(移動)均值和減去;
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g') plt.show()
然后,您可以觀察下圖作為滾動的輸出(移動)mean :
HMM是一種統計模型,廣泛用于具有延續性和可擴展性的數據,如時間序列股票市場分析,健康檢查和語音反饋gnition.本節詳細介紹了使用隱馬爾可夫模型(HMM)分析順序數據.
HMM是一個隨機模型這是建立在馬爾可夫鏈概念的基礎上的,該假設未來統計數據的概率僅取決于當前的過程狀態而不是之前的任何狀態.例如,當擲硬幣時,我們不能說第五次拋擲的結果將是一個頭.這是因為硬幣沒有任何記憶,下一個結果不依賴于之前的結果.
數學上,HMM由以下變量和減號組成;
它是HMM中存在的一組隱藏或潛在狀態.它由S表示.
它是HMM中存在的一組可能的輸出符號.它由O表示.
它是從一個狀態轉換到另一個狀態的概率狀態.它由A表示.
它是在特定狀態下發射/觀察符號的概率.它用B表示.
它是從系統的各種狀態開始于特定狀態的概率.它由Π表示.
因此,HMM可以定義為λ=(S,O,A,B,π),
其中,
S = {s1,s2,...,sN}是一組N個可能的狀態,
O = {o1,o2,...,oM}是一組M個可能的觀察符號,
A是N
感謝各位的閱讀,以上就是“怎么用Python與AI分析時間序列數據”的內容了,經過本文的學習后,相信大家對怎么用Python與AI分析時間序列數據這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





