溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么用Python分析購物數據”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么用Python分析購物數據”吧!
其實就今天的數據來講,我們主要做的是探索性分析;首先梳理已有的字段,有標題(提取出品類)、價格、銷量、店鋪名、發貨地。下面來做一下詳細的維度拆分以及可視化圖形選擇:
品類:
品類銷量的 TOP 10 有哪些?(表格或者橫向條形圖)
熱門(出現次數最多)品類展示;(詞云)
價格:年貨的價格區間分布情況;(圓環圖,觀察占比)
銷量、店鋪名:
店鋪銷量最高的 TOP 10 有哪些?(條形圖)
結合品類做聯動,比如點堅果,對應展示銷量排名的店鋪;(聯動,利用三方工具)
發貨地:銷量最高的城市有哪些?(地圖)
爬取主要利用 selenium 模擬點擊瀏覽器,前提是已經安裝 selenium 和瀏覽器驅動,這里我是用的 Google 瀏覽器,找到對應的版本號后并下載對應的版本驅動,一定要對應瀏覽器的版本號。
pip install selenium
安裝成功后,運行如下代碼,輸入關鍵字"年貨",進行掃碼就可以了,等著程序慢慢采集。
# coding=utf8
import re
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
import csv
# 搜索商品,獲取商品頁碼
def search_product(key_word):
# 定位輸入框
browser.find_element_by_id("q").send_keys(key_word)
# 定義點擊按鈕,并點擊
browser.find_element_by_class_name('btn-search').click()
# 最大化窗口:為了方便我們掃碼
browser.maximize_window()
# 等待15秒,給足時間我們掃碼
time.sleep(15)
# 定位這個“頁碼”,獲取“共100頁這個文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# 需要注意的是:findall()返回的是一個列表,雖然此時只有一個元素它也是一個列表。
page = re.findall("(\d+)", page_info)[0]
return page
# 獲取數據
def get_data():
# 通過頁面分析發現:所有的信息都在items節點下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 參數信息
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 價格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人數
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 旗艦店
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 發貨地
address = item.find_element_by_xpath('.//div[@class="location"]').text
# print(pro_desc, pro_price, buy_num, shop, address)
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("*" * 100)
print("正在爬取第{}頁".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num * 44))
browser.implicitly_wait(25)
get_data()
page_num += 1
print("數據爬取完畢!")
if __name__ == '__main__':
key_word = input("請輸入你要搜索的商品:")
option = Options()
browser = webdriver.Chrome(chrome_options=option,
executable_path=r"C:\Users\cherich\AppData\Local\Google\Chrome\Application\chromedriver.exe")
main()采集結果如下:

數據準備完成,中間從標題里提取類別過程比較耗時,建議大家直接用整理好的數據。
大概思路是對標題進行分詞,命名實體識別,標記出名詞,找出類別名稱,比如堅果、茶葉等。
這里的文件清洗幾乎用 Excel 搞定,數據集小,用 Excel 效率很高,比如這里做了一個價格區間。到現在數據清洗已經完成(可以用三方工具做可視化了),如果大家愛折騰,可以接著往下看用 Python 如何進行分析。
1、讀取文件
import pandas as pd
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
from wordcloud import WordCloud
from ast import literal_eval
import matplotlib.pyplot as plt
datas = pd.read_csv('./年貨.csv',encoding='gbk')
datas2、可視化:詞云圖
li = []
for each in datas['關鍵詞'].values:
new_list = str(each).split(',')
li.extend(new_list)
def func_pd(words):
count_result = pd.Series(words).value_counts()
return count_result.to_dict()
frequencies = func_pd(li)
frequencies.pop('其他')
plt.figure(figsize = (10,4),dpi=80)
wordcloud = WordCloud(font_path="STSONG.TTF",background_color='white', width=700,height=350).fit_words(frequencies)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
圖表說明:我們可以看到詞云圖,熱門(出現次數最多)品類字體最大,依次是:堅果、茶葉、糕點等。
3、可視化:繪制圓環圖
# plt.pie(x,lables,autopct,shadow,startangle,colors,explode)
food_type = datas.groupby('價格區間').size()
plt.figure(figsize=(8,4),dpi=80)
explodes= [0,0,0,0,0.2,0.1]
size = 0.3
plt.pie(food_type, radius=1,labels=food_type.index, autopct='%.2f%%', colors=['#F4A460','#D2691E','#CDCD00','#FFD700','#EEE5DE'],
wedgeprops=dict(width=size, edgecolor='w'))
plt.title('年貨價格區間占比情況',fontsize=18)
plt.legend(food_type.index,bbox_to_anchor=(1.5, 1.0))
plt.show()圖表說明:圓環圖和餅圖類似,代表部分相對于整體的占比情況,可以看到0 ~ 200元的年貨大概33%左右,100 ~ 200元也是33%。說明大部分的年貨的價格趨于200以內。
4、可視化:繪制條形圖
data = datas.groupby(by='店鋪名')['銷量'].sum().sort_values(ascending=False).head(10)
plt.figure(figsize = (10,4),dpi=80)
plt.ylabel('銷量')
plt.title('年貨銷量前十名店鋪',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.bar(data.index,data.values, color=colors)
plt.xticks(rotation=45)
plt.show()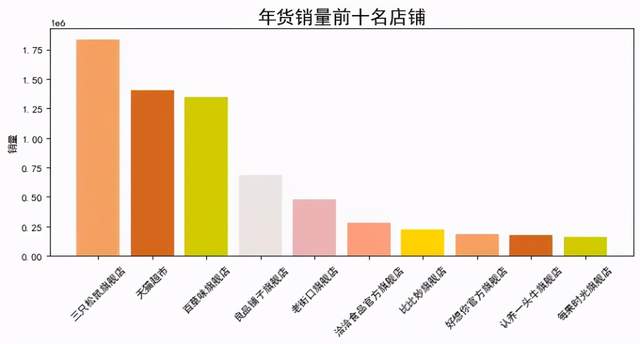
圖表說明:以上是店鋪按銷量排名情況,可以看到第一名是三只松鼠旗艦店,看來過年大家都喜歡吃干貨。
5、可視化:繪制橫向條形圖
foods = datas.groupby(by='類別')['銷量'].sum().sort_values(ascending=False).head(10)
foods.sort_values(ascending=True,inplace=True)
plt.figure(figsize = (10,4),dpi=80)
plt.xlabel('銷量')
plt.title('年貨推薦購買排行榜',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#CD96CD','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.barh(foods.index,foods.values, color=colors,height=1)
plt.show()圖表說明:根據類別銷量排名,排名第一是堅果,驗證了上面的假設,大家喜歡吃堅果。
到此,相信大家對“怎么用Python分析購物數據”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





