溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python數據合并的concat函數與merge函數怎么用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python數據合并的concat函數與merge函數怎么用文章都會有所收獲,下面我們一起來看看吧。
1.concat()函數可以沿著一條軸將多個對象進行堆疊,其使用方式類似數據庫中的數據表合并
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=None, copy=True)
2.參數含義如下:
| 參數 | 作用 |
|---|---|
| axis | 表示連接的軸向,可以為0或者1,默認為0 |
| join | 表示連接的方式,inner表示內連接,outer表示外連接,默認使用外連接 |
| ignore_index | 接收布爾值,默認為False。如果設置為True,則表示清除現有索引并重置索引值 |
| keys | 接收序列,表示添加最外層索引 |
| levels | 用于構建MultiIndex的特定級別(唯一值) |
| names | 設置了keys和level參數后,用于創建分層級別的名稱 |
| verify_integerity | 檢查新的連接軸是否包含重復項。接收布爾值,當設置為True時,如果有重復的軸將會拋出錯誤,默認為False |
3.根據軸方向的不同,可以將堆疊分成橫向堆疊與縱向堆疊,默認采用的是縱向堆疊方式
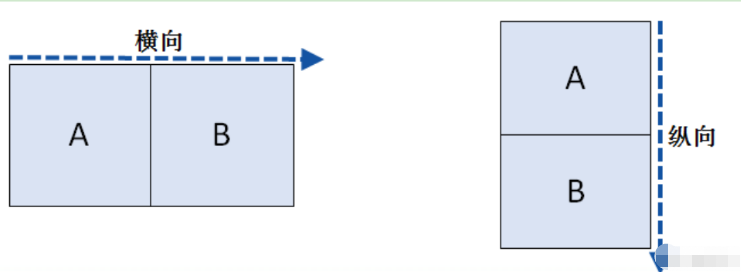
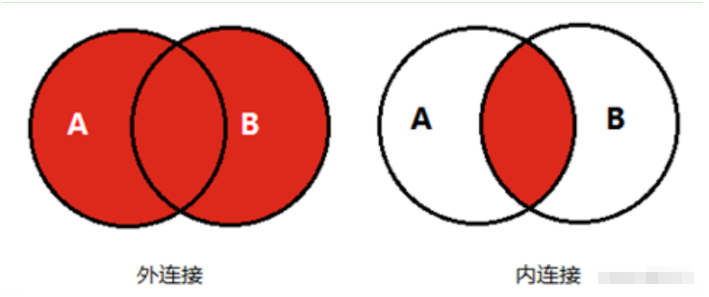
4.在堆疊數據時,默認采用的是外連接(join參數設為outer)的方式進行合并,當然也可以通過join=inner設置為內連接的方式。
import pandas as pd
df1=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df1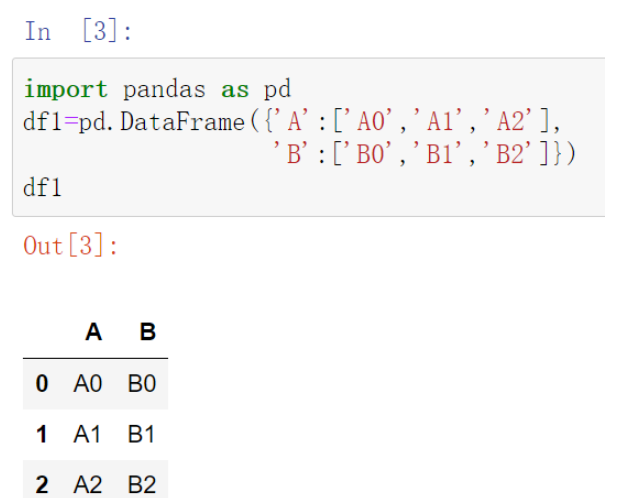

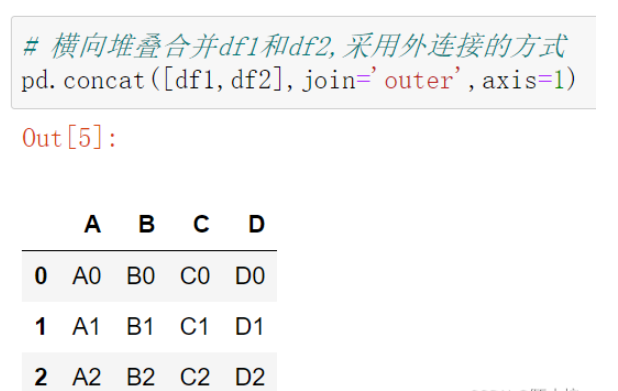
橫向堆疊合并df1和df2,采用外連接的方式
pd.concat([df1,df2],join='outer',axis=1)
import pandas as pd
first=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2'],
'C':['C0','C1','C2']})
first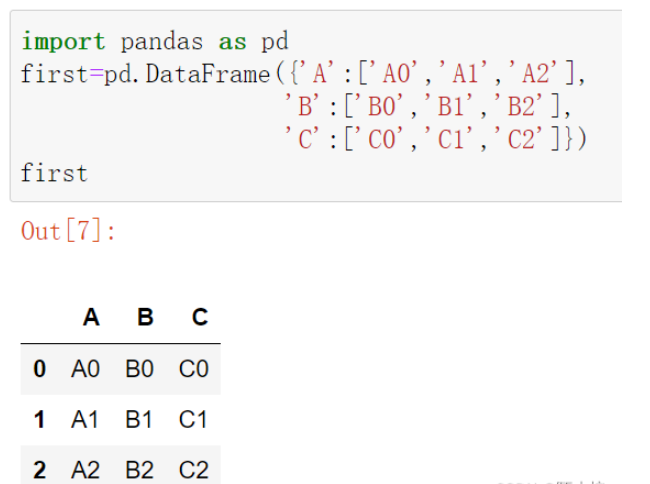
second=pd.DataFrame({'B':['B3','B4','B5'],
'C':['C3','C4','C5'],
'D':['D3','D4','D5']})
second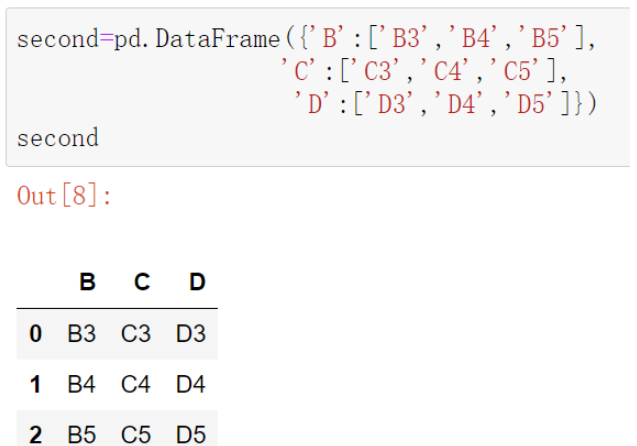
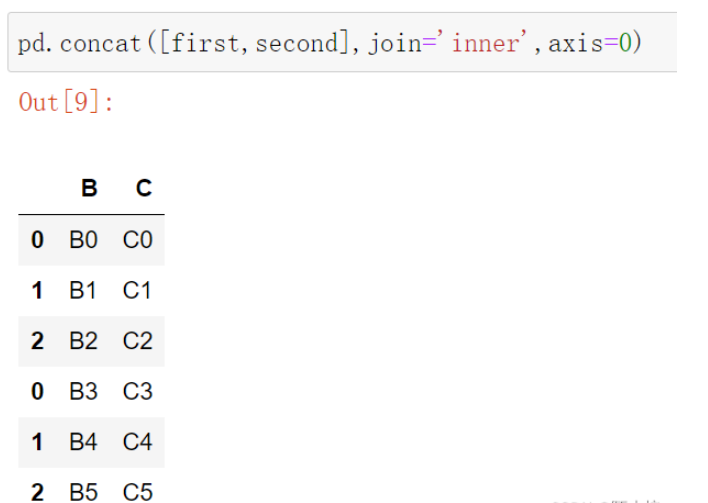
3.當使用concat()函數合并時,若是將axis參數的值設為0,且join參數的值設為inner,則代表著使用縱向堆疊與內連接的方式進行合并
pd.concat([first,second],join='inner',axis=0)
1)主鍵合并數據
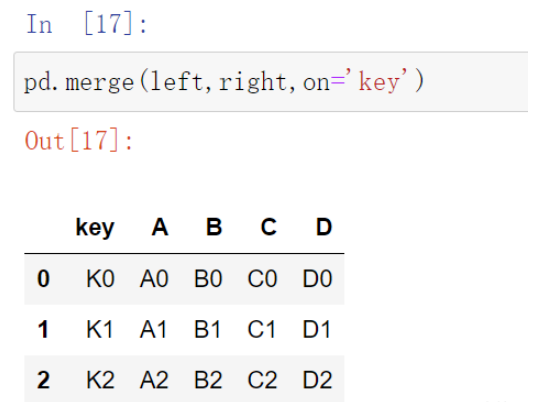
在使用merge()函數進行合并時,默認會使用重疊的列索引做為合并鍵,并采用內連接方式合并數據,即取行索引重疊的部分。
import pandas as pd
left=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
left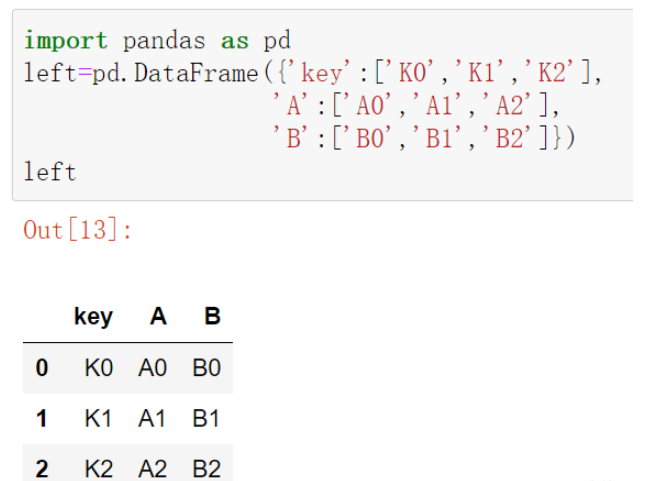
right=pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
right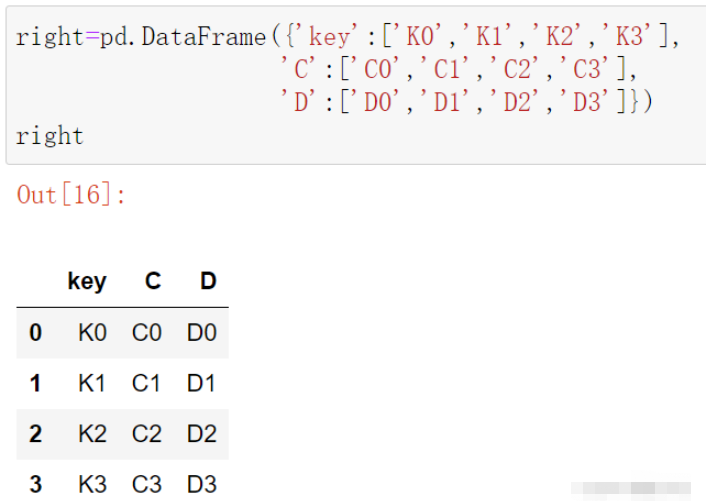
pd.merge(left,right,on='key')
2)merge()函數還支持對含有多個重疊列的DataFrame對象進行合并。
import pandas as pd
data1=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data1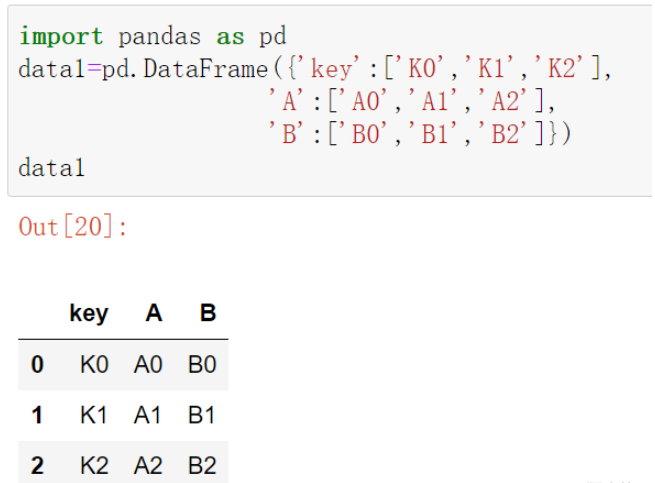
data2=pd.DataFrame({'key':['K0','K5','K2','K4'],
'B':['B0','B1','B2','B5'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
data2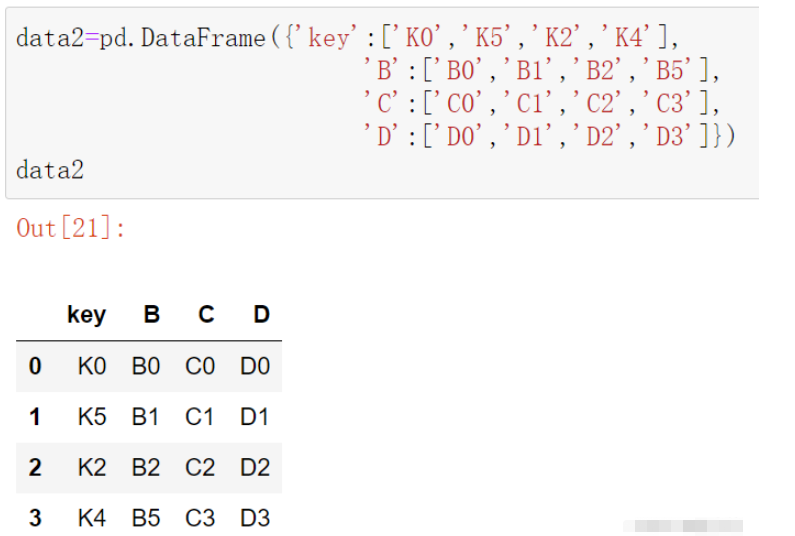
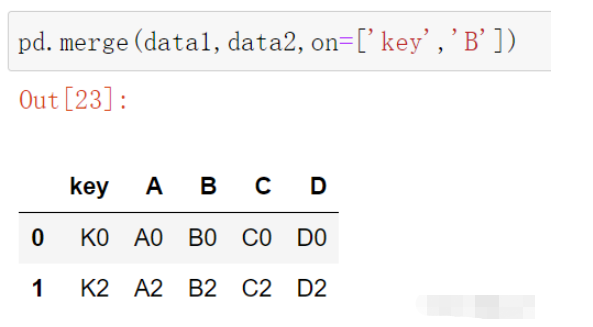
pd.merge(data1,data2,on=['key','B'])
join()方法能夠通過索引或指定列來連接多個DataFrame對象
join(other,on = None,how =‘left’,lsuffix =‘’,rsuffix =‘’,sort = False )
| 參數 | 作用 |
|---|---|
| on | 名稱,用于連接列名 |
| how | ?可以從{‘‘left’’ ,‘‘right’’, ‘‘outer’’, ‘‘inner’’}中任選一個,默認使用左連接的方式。 |
| sort | 根據連接鍵對合并的數據進行排序,默認為False |
import pandas as pd
data3=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data3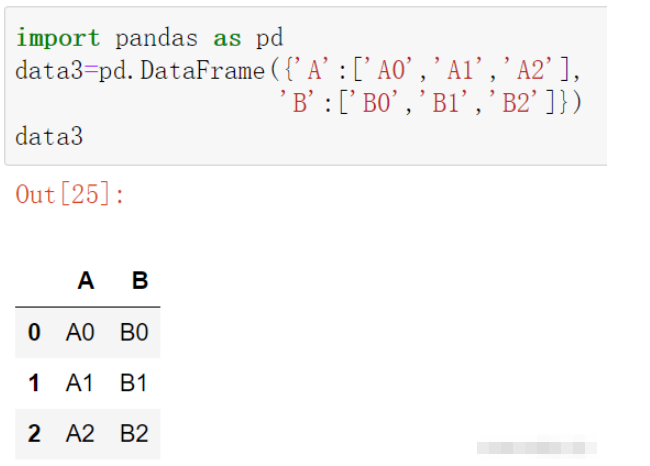
data4=pd.DataFrame({'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']},
index=['a','b','c'])
data3.join(data4,how='outer') # 外連接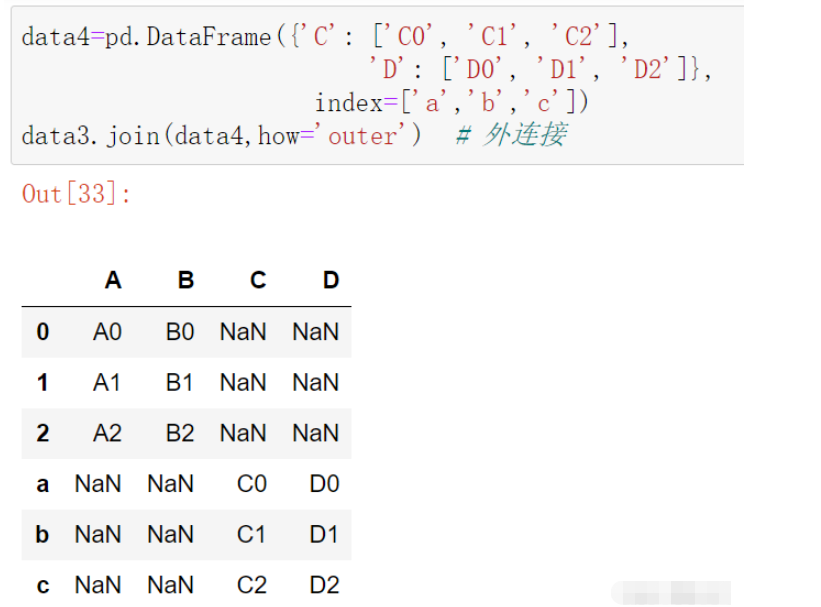
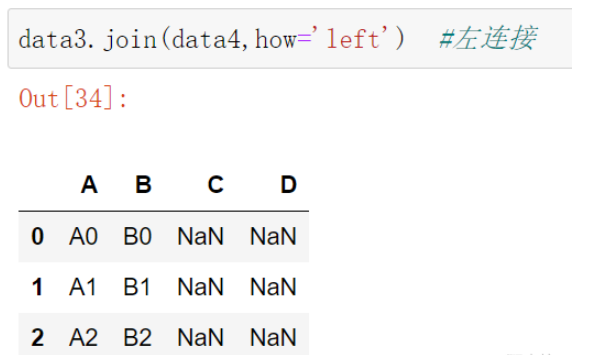
data3.join(data4,how='left') #左連接
data3.join(data4,how='right') #右連接

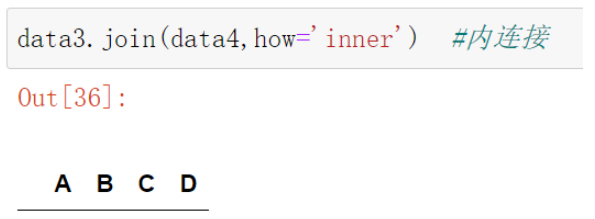
data3.join(data4,how='inner') #內連接
import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'key': ['K0', 'K1', 'K2']})
left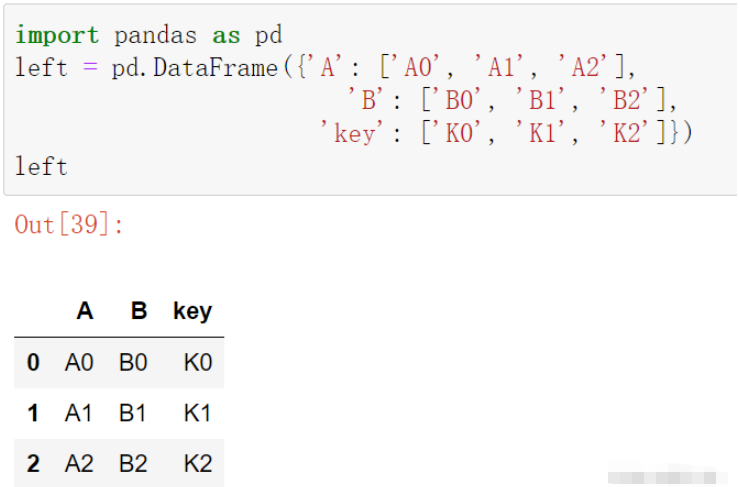
right = pd.DataFrame({'C': ['C0', 'C1','C2'],
'D': ['D0', 'D1','D2']},
index=['K0', 'K1','K2'])
right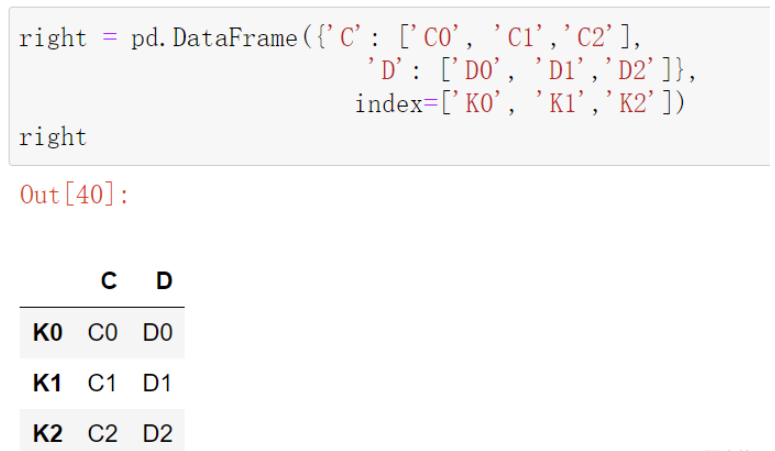
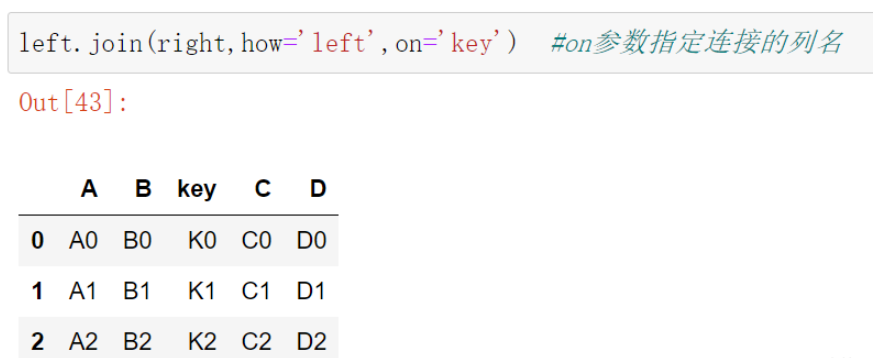
on參數指定連接的列名
left.join(right,how='left',on='key') #on參數指定連接的列名
當DataFrame對象中出現了缺失數據,而我們希望使用其他DataFrame對象中的數據填充缺失數據,則可以通過combine_first()方法為缺失數據填充。
import pandas as pd
import numpy as np
from numpy import NAN
left = pd.DataFrame({'A': [np.nan, 'A1', 'A2', 'A3'],
'B': [np.nan, 'B1', np.nan, 'B3'],
'key': ['K0', 'K1', 'K2', 'K3']})
left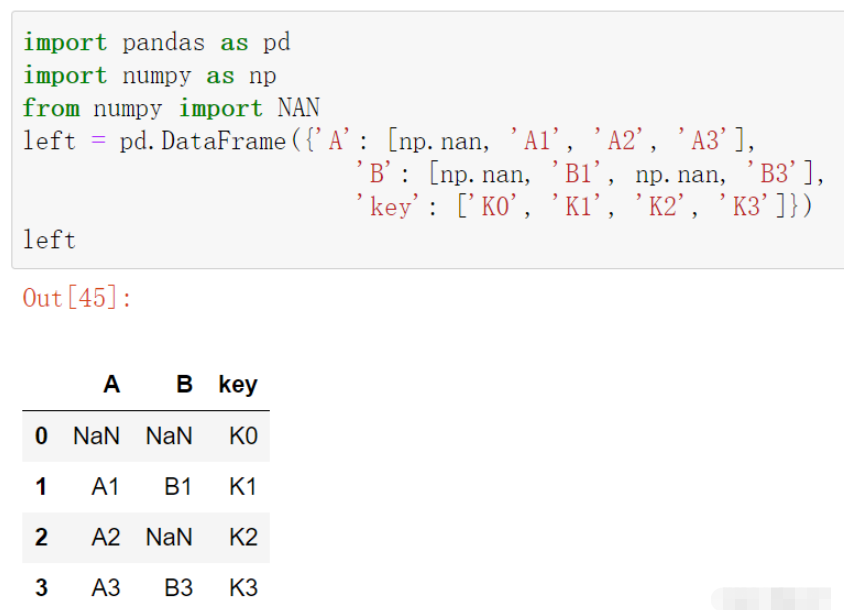
right = pd.DataFrame({'A': ['C0', 'C1','C2'],
'B': ['D0', 'D1','D2']},
index=[1,0,2])
right
用right的數據填充left缺失的部分
left.combine_first(right) # 用right的數據填充left缺失的部分

關于“Python數據合并的concat函數與merge函數怎么用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python數據合并的concat函數與merge函數怎么用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





