溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下python數據處理實例分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
我們現在拿到了一個十分龐大的數據集。是json文件,里面存儲了將近十萬個數據,現在要對其中的數據進行清洗處理。
import json import jieba
我們需要用json模塊來處理json文件,和使用jieba庫來分析詞性,這樣可以實現我們的需求。
停用詞表.txt,把停用詞表存入stopwords,原因是:我們的目標分析json里有一些標點符號。
stopwords = [line.strip() for line in open("停用詞表.txt",encoding="utf-8").readlines()]基本如圖所示:

a+str(b)+c這是文件名稱,a+b+c=./json/poet.song.0.json b遞增,實現動態取值
with open(a+str(b)+c,'r',encoding='utf8')as fp:
因為有將近500個json文件。每個文件里有好幾千組數據,我現在盡力的優化代碼,現在提取一次,把需要的數據存入文件里面差不多需要五分鐘。
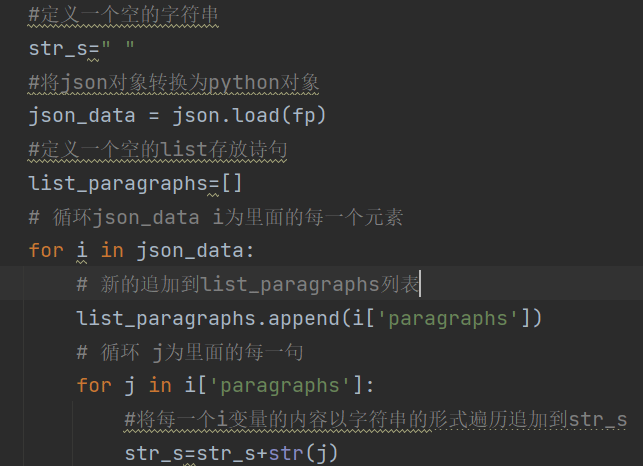
定義一個空的字符串,將json對象轉換為python對象。定義一個空的list存放詩句。
循環json_data i為里面的每一個元素。
新的追加到list_paragraphs列表
循環 j為里面的每一句。
代碼如圖所示:
使用jieba庫,分析str內容的詞性【注意是名稱,動詞。。。。】排行輸出都是倆個字是巧合,沒有字數限制
words = jieba.lcut(str_s)
現在words為分析完畢的詞性列表,遍歷。
排除特殊符號
for word in words: if word not in stopwords: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1
出現頻率加一。
使用lambda函數,sort快速排序,遍歷輸出頻率前50的詞性。
items.sort(key=lambda x:x[1], reverse=True)
之后賦值word, count。
word, count = items[i]
print ("{:<10}{:>7}".format(word, count))
f=open('towa.txt',"a",encoding='gb18030')
f.writelines("題目:"+textxxx)
f.writelines(word_ping)
以上就是“python數據處理實例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





