溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“基于pytorch怎么實現Resnet對本地數據集操作”,內容詳細,步驟清晰,細節處理妥當,希望這篇“基于pytorch怎么實現Resnet對本地數據集操作”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
mian.py文件是該項目的總文件,也是訓練網絡模型的運行文件,文本的介紹流程是隨著該文件一 一對代碼進行介紹。
main.py代碼如下所示:
from dataset import data_dataloader #電腦本地寫的讀取數據的函數 from torch import nn #導入pytorch的nn模塊 from torch import optim #導入pytorch的optim模塊 from network import Res_net #電腦本地寫的網絡框架的函數 from train import train #電腦本地寫的訓練函數 def main(): # 以下是通過Data_dataloader函數輸入為:數據的路徑,數據模式,數據大小,batch的大小,有幾線并用 (把dataset和Dataloader功能合在了一起) train_loader = data_dataloader(data_path='./data', mode='train', size=64, batch_size=24, num_workers=4) val_loader = data_dataloader(data_path='./data', mode='val', size=64, batch_size=24, num_workers=2) test_loader = data_dataloader(data_path='./data', mode='test', size=64, batch_size=24, num_workers=2) # 以下是超參數的定義 lr = 1e-4 #學習率 epochs = 10 #訓練輪次 model = Res_net(2) # resnet網絡 optimizer = optim.Adam(model.parameters(), lr=lr) # 優化器 loss_function = nn.CrossEntropyLoss() # 損失函數 # 訓練以及驗證測試函數 train(model=model, optimizer=optimizer, loss_function=loss_function, train_data=train_loader, val_data=val_loader,test_data= test_loader, epochs=epochs) if __name__ == '__main__': main()
main.py流程圖如圖1所示:
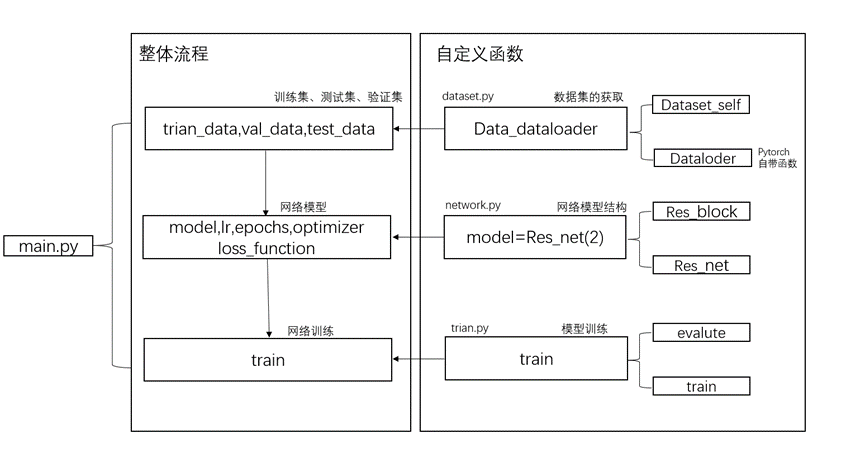
圖 1 main.py 代碼流程圖
main.py()前五行分別是導入相應的模塊,其中dataset,network以及train是本地編寫的文件。在mian()函數中的前幾行代碼中,我們使用dataset.py文件中的Data_dataloader函數導入訓練集、驗證集和測試集。Dataset文件是導入我們自己的本地數據庫,其功能是得到所有的數據,將其變成pytorch能夠識別的tensor數據,然后得到圖片。
dataset.py文件代碼如下所示:
import torch
import os,glob
import random
import csv
from torch.utils.data import Dataset
from PIL import Image
from torchvision import transforms
from torch.utils.data import DataLoader
# 第一部分:通過三個步驟得到輸出的tensor類型的數據
class Dataset_self(Dataset): #如果是nn.moduel 則是編寫網絡模型框架,這里需要繼承的是dataset的數據,所以括號中的是Dataset
#第一步:初始化
def __init__(self,root,mode,resize,): #root是文件根目錄,mode是選擇什么樣的數據集,resize是圖像重新調整大小
super(Dataset_self, self).__init__()
self.resize = resize
self.root = root
self.name_label = {} #創建一個字典來保存每個文件的標簽
#首先得到標簽相對于的字典(標簽和名稱一一對應)
for name in sorted(os.listdir(os.path.join(root))): #排序并且用列表的形式打開文件夾
if not os.path.isdir(os.path.join(root,name)): #不是文件夾就不需要讀取
continue
self.name_label[name] = len(self.name_label.keys()) #每個文件的名字為name_Label字典中有多少對鍵值對的個數
#print(self.name_label)
self.image,self.label = self.make_csv('images.csv') #編寫一共函數來讀取圖片和標簽的路徑
#在得到image和label的基礎上對圖片數據進行一共劃分 (注意:如果需要交叉驗證就不需要驗證集,只劃分為訓練集和測試集)
if mode == 'train':
self.image ,self.label= self.image[:int(0.6*len(self.image))],self.label[:int(0.6*len(self.label))]
if mode == 'val':
self.image ,self.label= self.image[int(0.6*len(self.image)):int(0.8*len(self.image))],self.label[int(0.6*len(self.label)):int(0.8*len(self.label))]
if mode == 'test':
self.image ,self.label= self.image[int(0.8*len(self.image)):],self.label[int(0.8*len(self.label)):]
# 獲得圖片和標簽的函數
def make_csv(self,filename):
if not os.path.exists(os.path.join(self.root,filename)): #如果不存在匯總的目錄就新建一個
images = []
for image in self.name_label.keys(): # 讓image到name_label中的每個文件中去讀取圖片
images += glob.glob(os.path.join(self.root,image,'*jpg')) #加* 貪婪搜索關于jpg的所有文件
#print('長度為:{},第二張圖片為:{}'.format(len(images),images[1]))
random.shuffle(images) #把images列表中的數據洗牌
# images[0]: ./data\ants\382971067_0bfd33afe0.jpg
with open(os.path.join(self.root,filename),mode='w',newline='') as f : #創建文件
writer = csv.writer(f)
for image in images:
name = image.split(os.sep)[-2] #得到與圖片相對應的標簽
label = self.name_label[name]
writer.writerow([image,label]) #寫入文件 第一行:./data\ants\382971067_0bfd33afe0.jpg,0
images,labels = [],[]
with open(os.path.join(self.root,filename)) as f: #讀取文件
reader = csv.reader(f)
for row in reader:
image, label = row
label = int(label)
images.append(image)
labels.append(label)
assert len(images) == len(labels) #類似if語句,只有兩者長度一致才繼續執行,否則報錯
return images,labels #返回所有!!是所有的圖片和標簽(此處的圖片不是圖片數據本身,而是它的文件目錄)
#第二步:得到圖片數據的長度(標簽數據長度與圖片一致)
def __len__(self):
return len(self.image)
#第三步:讀取圖片和標簽,并輸出
def __getitem__(self, item): # 單張返回張量的圖像與標簽
image,label = self.image[item],self.label[item] #得到單張圖片和相應的標簽(此處都是image都是文件目錄)
image = Image.open(image).convert('RGB') #得到圖片數據
#使用transform對圖片進行處理以及變成tensor類型數據
transf = transforms.Compose([transforms.Resize((int(self.resize),int(self.resize))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(), #先變成tensor類型數據,然后在進行下面的標準化
])
image = transf(image)
label = torch.tensor(label) #把圖片標簽也變成tensor類型
return image,label
#第二部分:使用pytorch自帶的DataLoader函數批量得到圖片數據
def data_dataloader(data_path,mode,size,batch_size,num_workers): #用一個函數加載上訴的數據,data_path、mode和size分別是以上定義的Dataset_self()中的參數,batch_size是一次性輸出多少張圖像,num_worker是同時處理幾張圖像
dataset = Dataset_self(data_path,mode,size)
dataloader = DataLoader(dataset,batch_size,num_workers) #使用pytorch中的dataloader函數得到數據
return dataloader
#測試
def main():
test = Dataset_self('./data','train',64)
if __name__ == '__main__':
main()dataset.py流程圖2所示:
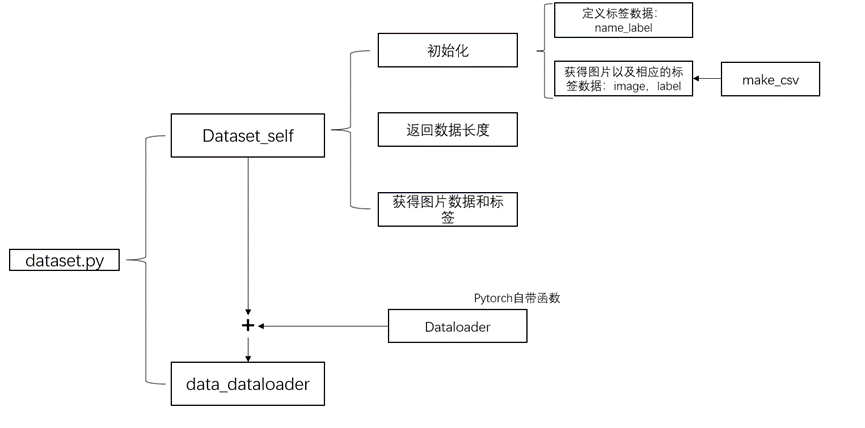
圖2 dataset.py流程圖
如以上代碼所示,使用pytorch加載自定義的數據集時,需要定義一個dataset的對象,然后定義一個dataloaber的對象,最后對dataloaber反復得到訓練數據和標簽。所以本文件主要分為兩個部分:自定義的dataset部分和使用pytorch中dataloaber來得到訓練數據的部分。
代碼首先是導入必要的python庫,然后編寫第一部分。第一部分主要是通過三個步驟來得到單張輸出的tensor類型圖片和標簽。
三個步驟分別是:初始化、獲得數據的長度以及讀取數據和標簽。其中初始化是為了得到一個文件,文件中保存所有圖片相對應的目錄以及其標簽,再將得到的文件讀出分為訓練集、驗證集和測試集。具體實現如上述代碼所示,首先在初始化的函數中定義變量resize、root和name_label,方便與后面的函數調用:

圖3 Dataset_self中參數的初始化
然后,我們編寫代碼讀取根目錄,得到分類名字及其相對應的標簽:

圖4 標簽的獲得
代碼中,首先使用os庫來把根目錄內的文件變成列表被讀取出來,然后把根目錄內所有文件名保存在name_label字典中,在分別依照存儲進字典的個數來給標簽數值化。(第一個讀取進字典的標簽就是0,第二個是1,其余文件以此類推)
得到標簽字典后,我們編寫一個函數來獲得所有圖片的目錄,便于下面步驟的圖片讀取:

圖5 圖片和標簽的讀取
編寫make_csv函數,來得到image和label(image是每張圖片的目錄,label是相對應的標簽)。
make_csv函數中,首先判斷是否以及存在我們需要的文件,如果存在則直接讀取,如果不存在就先生成一個存儲所有圖片目錄和標簽的文件。
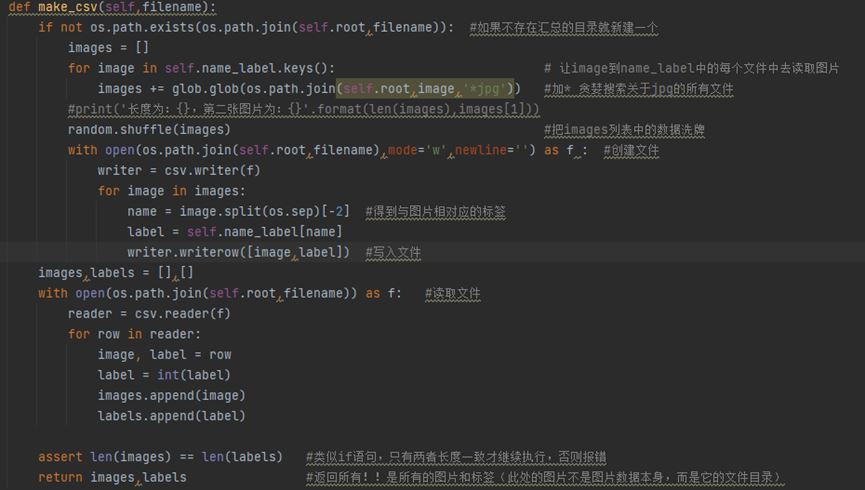
圖6 make_csv函數
當文件不存在時(第一行語句的判斷),我們編寫文件的思路是先編寫一個列表來保存所有的圖片目錄,然后再創建文件使用csv庫把列表數據寫入文件中。所以在判斷語句下面,我們得到一個空的images列表,然后遍歷name_label中的keys,對于name_label來說,它是一個key是文件名,value是標簽(數值)的字典,因為是用os庫把文件讀取成為字典的,所以遍歷字典內的key時,是讀取的是相對應的文件。所以上圖第四行代碼中是分別讀取文件中的圖片,然后使用glob庫分別把所有jpg文件存儲到images列表里面。在列表中images[0]是:./data\ants\382971067_0bfd33afe0.jpg
在得到圖片目錄列表后,首先將列表內的數據隨機排列,然后創造一個文件,在列表images中的目錄得到標簽名稱,用name_label得到標簽名稱相對應的數值,最后寫入文件中。文件第一行是:./data\ants\382971067_0bfd33afe0.jpg,0(圖片相對目錄和相對于的標簽)
得到文件后,因為我們需要的是每張圖片的目錄而不是文件(主要是為了后面反復調試,所以得到一個文件做中轉站),所以我們需要用兩個列表來得到圖片目錄和相對應的標簽值,最后分別把文件中的數據寫入列表中,得到圖片和標簽列表。
至此,我們就能通過函數make_csv來得到image和label。得到這兩個列表后,我們對其進行切割,因為列表里面是保存的所以數據,所以我們需要分割為訓練集、驗證集和測試集。代碼很簡單,(如果需要交叉驗證則只需要劃分出訓練集和測試集即可)如下圖所示:

圖7 數據集的劃分
以上是第一步初始化的過程,第二步讀取圖像長度:

圖8 讀取圖像長度
很簡單,一個len()函數就搞定,其主要功能是知道一共有多少數據。
第三步:讀取數據和標簽,讀取數據是一張一張來讀取的,所以首先從image和label列表中得到單個數據,因為image列表中保存的是圖片的目錄,所以先讀取RGB格式的圖片,然后使用transform對圖片進行相應的處理(尺寸,圖片變化,變成tensor類型等),最后也將label變成tensor類型然后把圖片數據和標簽數據返回即可,代碼如下圖所示:
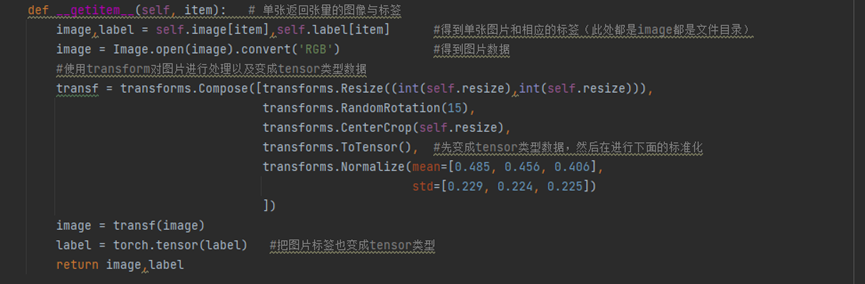
圖8 讀取圖像和標簽
第一部分是讀取圖片和圖片相對應的標簽,流程是三步:初始化、得到數據長度和讀取單張數據,對于pytorch的dataset處理都是基于這三步。其中算法邏輯并不復雜,主要是需要使用的語句有點多,需要仔細思考其中的邏輯。
第二部分相對于第一部分要簡單很多,甚至可以把這部分放到main()函數中運行。其主要內容是通過第一部分得到的dataset_self來得到數據,然后使用pytorch自帶的dataloader得到放入模型中訓練的數據集,代碼如下圖所示:

圖9 數據集的獲取
Dataset部分其功能簡單概括就是將本地數據集中的圖片和標簽變成tensor類型數據讀取為需要使用的數據集。
main.py()中,我們定義了一些超參數等,分別有學習率,訓練輪次,訓練模型,優化器以及損失函數。對于訓練模型,本文使用的是本地編寫的一個小型的Resnet模型。其代碼如下所示:
import torch
from torch import nn
# 先寫好resnet的block塊
class Res_block(nn.Module):
def __init__(self,in_num,out_num,stride):
super(Res_block, self).__init__()
self.cov1 = nn.Conv2d(in_num,out_num,(3,3),stride=stride,padding=1) #(3,3) padding=1 則圖像大小不變,stride為幾圖像就縮小幾倍,能極大減少參數
self.bn1 = nn.BatchNorm2d(out_num)
self.cov2 = nn.Conv2d(out_num,out_num,(3,3),padding=1)
self.bn2 = nn.BatchNorm2d(out_num)
self.extra = nn.Sequential(
nn.Conv2d(in_num,out_num,(1,1),stride=stride),
nn.BatchNorm2d(out_num)
) #使得輸入前后的圖像數據大小是一致的
self.relu = nn.ReLU()
def forward(self,x):
out = self.relu(self.bn1(self.cov1(x)))
out = self.relu(self.bn2(self.cov2(out)))
out = self.extra(x) + out
return out
class Res_net(nn.Module):
def __init__(self,num_class):
super(Res_net, self).__init__()
self.init = nn.Sequential(
nn.Conv2d(3,16,(3,3)),
nn.BatchNorm2d(16)
) #預處理
self.bn1 = Res_block(16,32,2)
self.bn2 = Res_block(32,64,2)
self.bn3 = Res_block(64,128,2)
self.bn4 = Res_block(128,256,2)
self.fl = nn.Flatten()
self.linear1 = nn.Linear(8192,10)
self.linear2 = nn.Linear(10,num_class)
out = self.relu(self.init(x))
#print('inint:',out.shape)
out = self.bn1(out)
#print('bn1:', out.shape)
out = self.bn2(out)
#print('bn2:', out.shape)
out = self.bn3(out)
#print('bn3:', out.shape)
out = self.fl(out)
#print('flatten:', out.shape)
out = self.relu(self.linear1(out))
#print('linear1:', out.shape)
out = self.relu(self.linear2(out))
#print('linear2:', out.shape)
#測試
def main():
x = torch.randn(2,3,64,64)
net = Res_net(2)
out = net(x)
print(out.shape)
if __name__ == '__main__':
main()network.py流程圖如圖10所示:
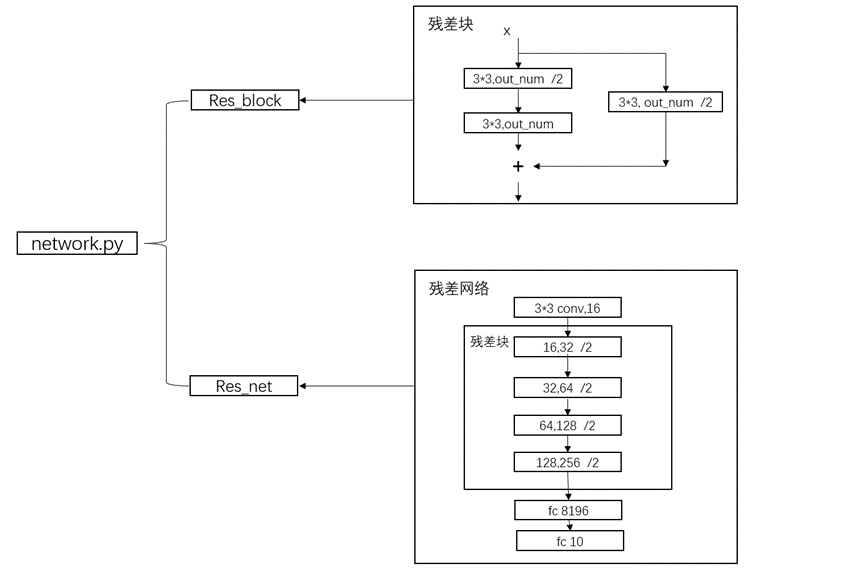
圖10 network.py流程圖
Resnet模型網絡主要是兩部分,首先編寫resnet中的每個殘差塊,然后編寫整個網絡。在開始介紹代碼之前,首先用我的理解來介紹一下Resnet,也就是殘差網絡的思想與邏輯(具體可以搜索其他資料查看)。殘差網絡其主要的目的是能夠訓練一個深層次的網絡,希望是隨著網絡的加深,效果越來越好。但是因為網絡加深,很有可能一些參數會得不到訓練(一次次的迭代,使得梯度消失),所有Resnet網絡巧妙的運用了一個殘差塊來解決因為網絡模型太深而導致其梯度消失的問題,如圖11所示:
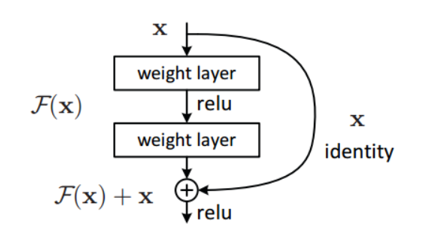
圖11 殘差塊
簡單來說就是在x通過兩個層后,在和x本身相加,如此在反向傳播的過程中,f(x)+x求帶就變成如此就在回傳給x上面的隱藏層的時候就不會發生梯度消失(至少有個1)。如果在x輸入殘差塊前有n層,那么就算殘差快內的隱藏層因為梯度消失的問題而沒有訓練好,但是至少x輸入之前的n層是訓練好了的,這樣只要殘差快中的隱藏層能訓練好一部分,神經網絡的準確度就很有可能在原來基礎上增加。(還是得好好研究,這里Resnet的解釋可能并沒有那么準確)
基于上述殘差塊的圖片,我們先定義好殘差塊,代碼如下圖12所示:
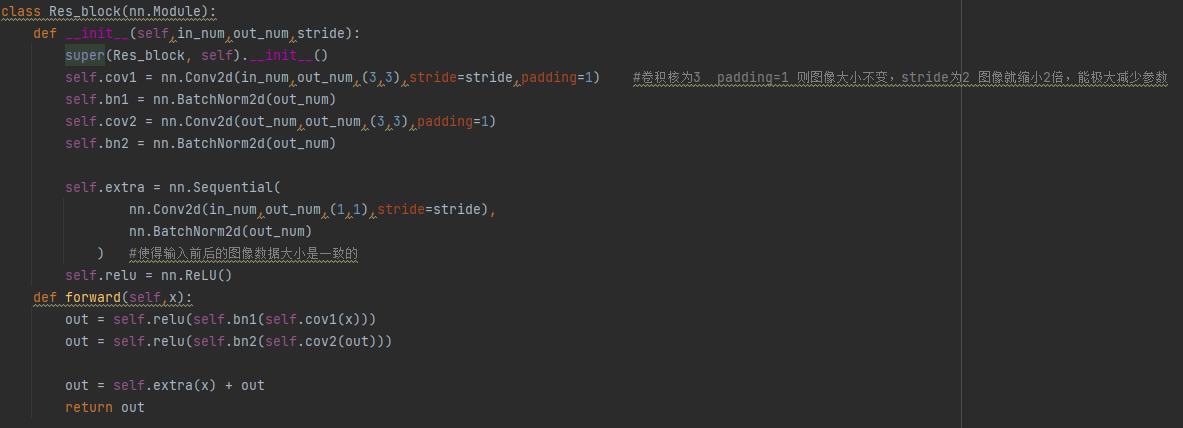
圖12 殘差塊的定義
其流程圖如圖13:
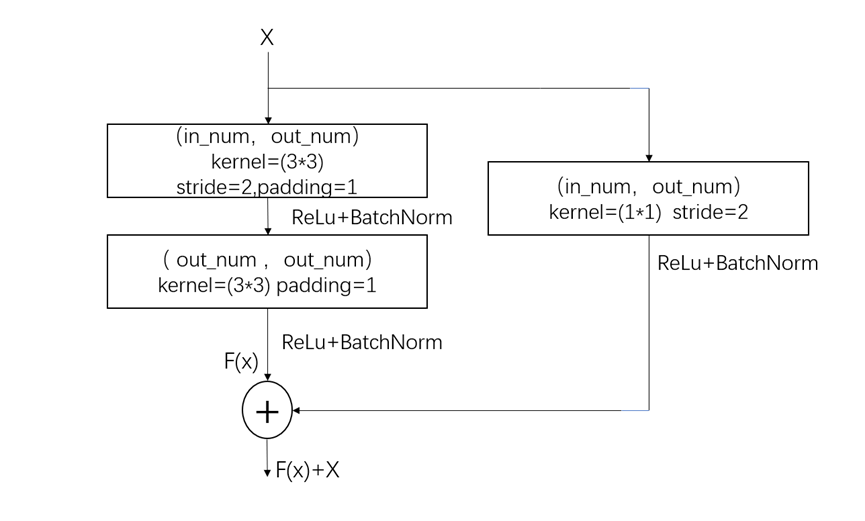
圖13 殘差塊定義流程圖
當殘差塊寫好后,就可以編寫一個簡單的Resnet網絡,代碼如圖14所示:
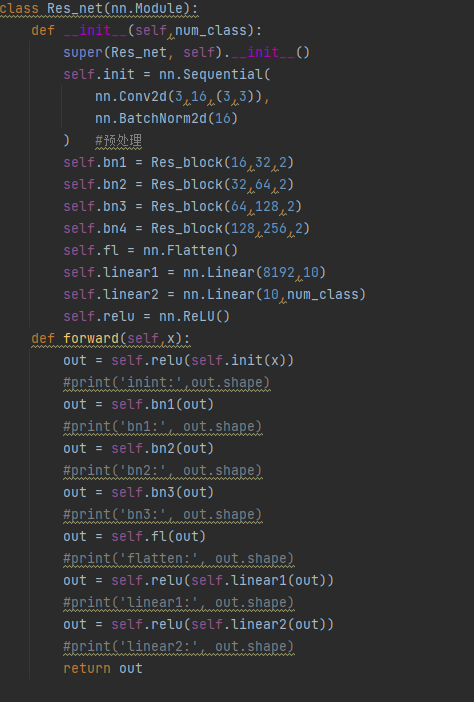
圖14 簡單Resnet網絡模型
上述代碼中,首先通過一層正常的卷積層后,再通過3個殘差塊,最后通過兩層線性層,代碼十分比較簡單。在定義好殘差塊之后,調用pytorch本身自帶的函數即可完成。唯一需要注意的地方是參數的設置,該網絡一般來說都是維度在慢慢增加,圖像的尺寸慢慢減少。
train.py是整個模型的訓練過程,本文將其打包成為一個函數,然后在mian.py中調用,因為基本上網絡的訓練過程都大同小異,一般都是用訓練集訓練,在驗證集上得到最好的輪次,最后保存網絡參數并且在測試集上檢測,所以這里直接將訓練過程和驗證過程打包成為函數,便于以后項目的直接調用。
train.py代碼如下所示:
import torch
from torch import optim
from torch.utils.data import DataLoader
from dataset import Dataset_self
from network import Res_net
from torch import nn
from matplotlib import pyplot as plt
import numpy as np
def evaluate(model,loader): #計算每次訓練后的準確率
correct = 0
total = len(loader.dataset)
for x,y in loader:
logits = model(x)
pred = logits.argmax(dim=1) #得到logits中分類值(要么是[1,0]要么是[0,1]表示分成兩個類別)
correct += torch.eq(pred,y).sum().float().item() #用logits和標簽label想比較得到分類正確的個數
return correct/total
#把訓練的過程定義為一個函數
def train(model,optimizer,loss_function,train_data,val_data,test_data,epochs): #輸入:網絡架構,優化器,損失函數,訓練集,驗證集,測試集,輪次
best_acc,best_epoch =0,0 #輸出驗證集中準確率最高的輪次和準確率
train_list,val_List = [],[] # 創建列表保存每一次的acc,用來最后的畫圖
for epoch in range(epochs):
print('============第{}輪============'.format(epoch + 1))
for steps,(x,y) in enumerate(train_data): # for x,y in train_data
logits = model(x) #數據放入網絡中
loss = loss_function(logits,y) #得到損失值
optimizer.zero_grad() #優化器先清零,不然會疊加上次的數值
loss.backward() #后向傳播
optimizer.step()
train_acc =evaluate(model,train_data)
train_list.append(train_acc)
print('train_acc',train_acc)
#if epoch % 1 == 2: #這里可以設置每兩次訓練驗證一次
val_acc = evaluate(model,val_data)
print('val_acc=',val_acc)
val_List.append((val_acc))
if val_acc > best_acc: #判斷每次在驗證集上的準確率是否為最大
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(),'best.mdl') #保存驗證集上最大的準確率
print('===========================分割線===========================')
print('best acc:',best_acc,'best_epoch:',best_epoch)
#在測試集上檢測訓練好后模型的準確率
model.load_state_dict((torch.load('best.mdl')))
print('detect the test data!')
test_acc = evaluate(model,test_data)
print('test_acc:',test_acc)
train_list_file = np.array(train_list)
np.save('train_list.npy',train_list_file)
val_list_file = np.array(val_List)
np.save('val_list.npy',val_list_file)
#畫圖
x_label = range(1,len(val_List)+1)
plt.plot(x_label,train_list,'bo',label='train acc')
plt.plot(x_label,val_List,'b',label='validation acc')
plt.title('train and validation accuracy')
plt.xlabel('epochs')
plt.legend()
plt.show()
#測試
def main():
train_dataset = Dataset_self('./data', 'train', 64)
vali_dataset = Dataset_self('./data', 'val', 64)
test_dataset = Dataset_self('./data', 'test', 64)
train_loaber = DataLoader(train_dataset, 24, num_workers=4)
val_loaber = DataLoader(vali_dataset, 24, num_workers=2)
test_loaber = DataLoader(test_dataset, 24, num_workers=2)
lr = 1e-4
epochs = 5
model = Res_net(2)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
train(model,optimizer,criteon,train_loaber,val_loaber,test_loaber,epochs)
if __name__ == '__main__':
main()train.py流程圖如圖15所示:
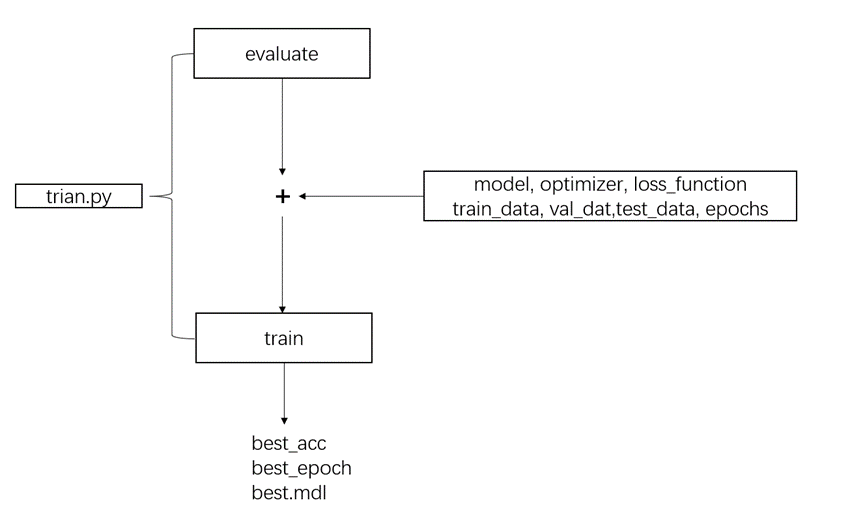
圖15 train.py流程圖
上述代碼中,第一個函數的定義是為了得到一次訓練(或者驗證或者測試)后的準確率,也就是跑完一次所有訓練集后,模型的準確率是多少。其代碼內容并不復雜,先得到經過模型logits中的分類標簽(是[1,0]還是[0,1],表示分成兩類)pred,然后用logits與標簽進行比較,從而得到一個batch_size中分類正確的個數,然后累加起來,得到一次訓練中網絡對數據集分類正確的個數(correct),最后讓其除以數據集的個數從而得到準確率并且返回其數值。
對于第二個函數,train的函數的定義,其主要內容是在訓練集上訓練,每一輪次訓練好之后放在驗證集上驗證(可以是每兩次或者三次),執行完所有輪次后,保存在驗證集上最好的一次的網絡參數與輪次,最后加載保存的網絡參數對測試集進行檢測。
train函數內部首先定義驗證集中最好的準確率和最好的輪次,然后創建兩個列表來保存每一次的訓練集和驗證集的準確率(用來畫圖查看),然后就是進行epochs次訓練。

圖16 trian函數內參數的定義
訓練中,如果直接是用x,y來獲得數據的圖片和標簽則可以使用標注里面的代碼,而使用enumerate函數,其主要是為了給每次得到的數據(x,y)標上一個索引,這個索引是steps,從0開始(這里沒有使用到steps參數)。在每次執行中,圖片數據x會被放入網絡模型model中被處理,然后使用定義的loss_function函數得到預測和正確標簽之間的損失值。優化器先清零(不然會有數值疊加),然后讓損失值loss執行反向傳播操作(鏈式求導),最后優化器執行優化功能,如此便實現了模型的一次訓練與參數更新。
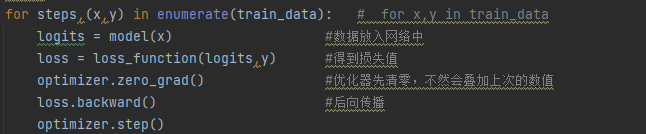
圖17 模型的訓練步驟
而后面的代碼,每訓練一次網絡模型,就把驗證集放入網絡模型中,測試網絡模型訓練得怎么樣,然后保存下epochs次數中最好準確率的網絡模型參數與輪次。最后加載保存下的網絡模型參數,在測試集上檢測準確率如何。
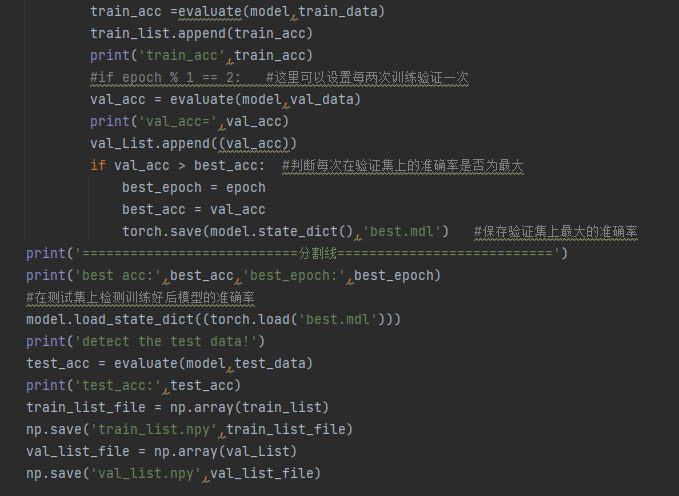
圖18 模型參數的保存與測試
最后幾句代碼是將保存下來的準確率做圖,有一點需要注意,因為這里是每次訓練后都在驗證集上檢測過,所以坐標軸的長度就用訓練集準確率的長度來表示兩個不同數據的長度。
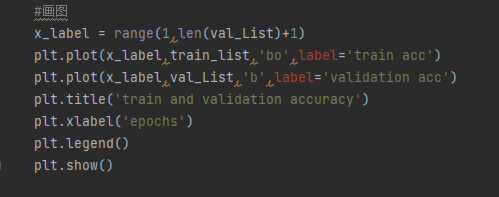
圖19 做圖
本文項目是使用Resnet模型來識別螞蟻和蜜蜂,其一共有三百九十六張的數據,訓練集只有兩百多張(數據集很小),運行十輪后,分別對訓練集和測試集在每一輪的準確率如圖所示:
圖20 train and validation accuracy
測試集的準確率如圖所示:

圖21 測試集準確率
最后得到的效果不理想,很大可能是數據集太少導致導致模型泛化能力變弱(模型把訓練集都記下來了),對于這樣的問題可以嘗試通過交叉驗證(效果可能有一定程度的提升)或者增加數據集的方法來增強模型的泛化能力。對精度的提升,會在后續的文章中進行討論。
在得到模型參數后,我隨便在網上找了兩張螞蟻的圖片放進模型檢測看效果如何:
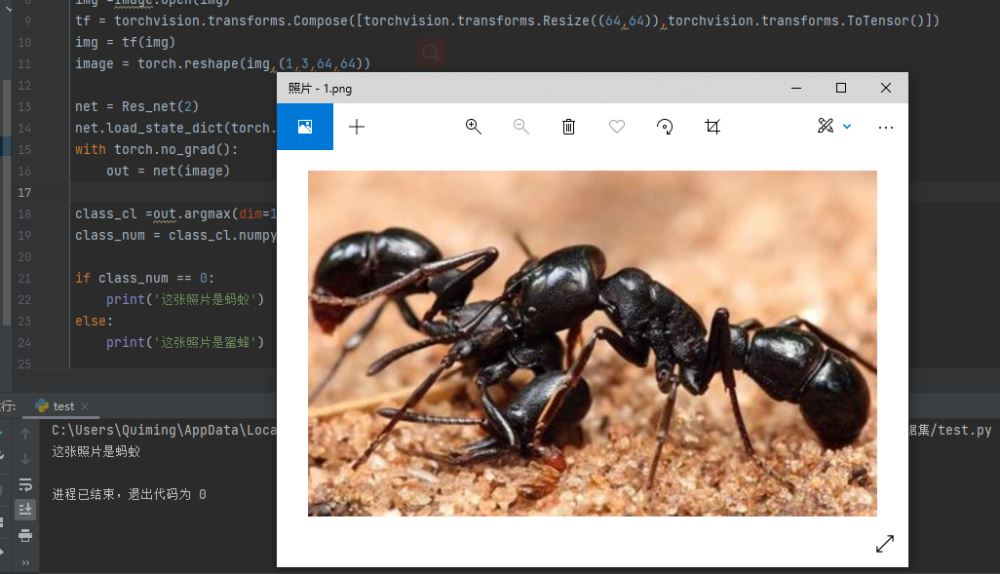
圖22 第一次測試
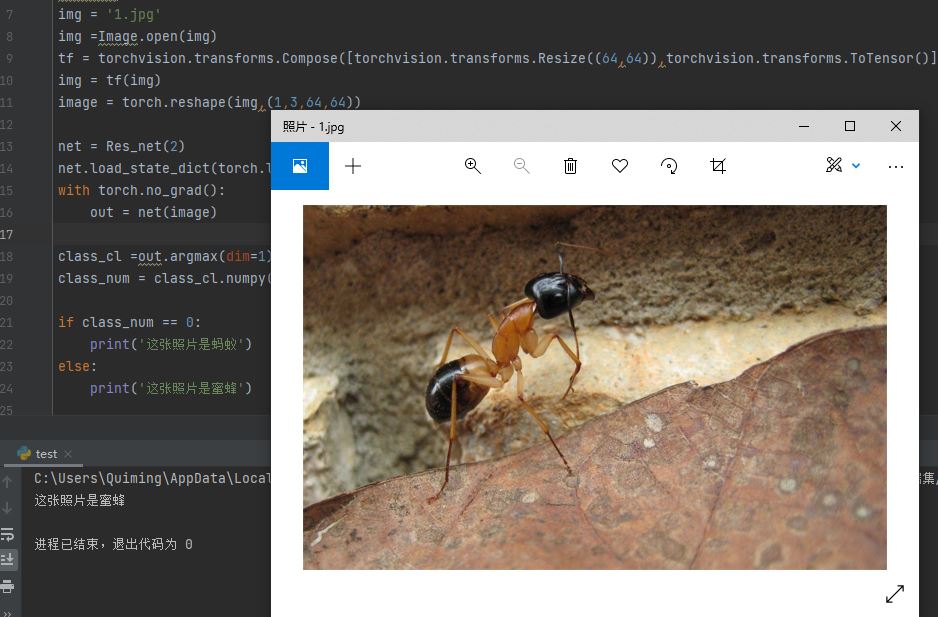
圖23 第二次測試
第一次測試識別出來了是螞蟻,但是第二次就失敗了,有可能是模型沒有看到過黑色的蜜蜂所以把黑色的都當成了螞蟻吧,總之改模型還有很多需要改進的地方。
附上單張檢測的代碼:
from network import Res_net
import torch
from PIL import Image
import torchvision
#導入圖片
img = '1.jpg'
img =Image.open(img)
tf = torchvision.transforms.Compose([torchvision.transforms.Resize((64,64)),torchvision.transforms.ToTensor()])
img = tf(img)
image = torch.reshape(img,(1,3,64,64))
#加載模型
net = Res_net(2)
net.load_state_dict(torch.load('best.mdl'))
with torch.no_grad():
out = net(image)
#確定分類
class_cl =out.argmax(dim=1)
class_num = class_cl.numpy()
if class_num == 0:
print('這張照片是螞蟻')
else:
print('這張照片是蜜蜂')讀到這里,這篇“基于pytorch怎么實現Resnet對本地數據集操作”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





