溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python函數定義與使用的示例分析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
什么是函數? — > 函數是具有某種特定功能的代碼塊,可以重復使用(在前面數據類型相關章節,其實已經出現了很多 Python 內置函數了)。它使得我們的程序更加模塊化,不需要編寫大量重復的代碼。
函數可以提前保存起來,并給它起一個獨一無二的名字,只要知道它的名字就能使用這段代碼。函數還可以接收數據,并根據數據的不同做出不同的操作,最后再把處理結果反饋給我們。
由此我們得知:
將一件事情的步驟封裝在一起并得到最終結果的步驟,就是函數的過程。
函數名代表了該函數要做的事情。
函數體是實現函數功能的流程。
在實際工作中,我們把實現一個函數也叫做 “實現一個方法或者實現一個功能”
函數可以幫助我們重復使用功能,通過函數名我們也可以知道函數的作用。
內置函數:在前面數據類型相關章節,其實已經出現了很多 Python 內置函數了。如 input、id、type、max、min、int、str等 ,這些都是 Python 的內置函數。也就是 Python 已經為我們定義好的函數,我們直接拿來使用即可。
自定義函數:由于每個業務的不同,需求也各不相同。Python無法提供給我們所有我們想要的功能,這時候我們就需要去開發,實現我們自己想要的功能。這部分函數,我們叫它 自定義函數 。
無論是內置函數,還是自定義函數,他們的書寫方法都是一樣的。
def 關鍵字的功能:實現 Python 函數的創建。
def 關鍵字定義函數:定義函數,也就是創建一個函數,可以理解為創建一個具有某些用途的工具。定義函數需要用 def 關鍵字實現,具體的語法格式如下:
def 函數名(參數列表): todo something # 實現特定功能的多行代碼 [return [返回值]] # 用 [] 括起來的為可選擇部分,即可以使用,也可以省略。 # >>> 各部分參數的含義如下: # >>> 函數名:其實就是一個符合 Python 語法的標識符,但不建議使用 a、b、c 這類簡單的標識符作為函數名,函數名最好能夠體現出該函數的功能(如user_info, user_mobile)。 # >>> 參數列表:設置該函數可以接收多少個參數,多個參數之間用逗號( , )分隔。 # >>> [return [返回值] ]:整體作為函數的可選參參數,用于設置該函數的返回值。也就是說,一個函數,可以用返回值,也可以沒有返回值,是否需要根據實際情況而定。
注意,在創建函數時,即使函數不需要參數,也必須保留一對空的 “()” ,否則 Python 解釋器將提示“invaild syntax”錯誤。另外,如果想定義一個沒有任何功能的空函數,可以使用 pass 語句作為占位符。
示例如下:
def user_name():
print('這是一個 \'user_name\'函數 ')
user_name()
# >>> 執行結果如下
# >>> 這是一個 'user_name'函數return 的意思就是返回的意思,它是將函數的結果返回的關鍵字,所以函數的返回值也是通過 return 來實現的。
需要注意的是,return 只能在函數體內使用; return 支持返回所有的數據類型,當一個函數返回之后,我們可以給這個返回值賦予一個新的變量來使用。
由此我們總結出:
return 是將函數結果返回的關鍵字
return 只能在函數體內使用
return 支持返回所有的數據類型
有返回值的函數,可以直接賦值給一個變量
return 的用法,示例如下:
def add(a,b): c = a + b return c #函數賦值給變量 result = add(a=1,b=1) print(result) #函數返回值作為其他函數的實際參數 print(add(3,4))
需要注意的是,return 語句在同一函數中可以出現多次,但只要有一個得到執行,就會直接結束函數的執行。
現在我們利用 return 關鍵字 ,嘗試自定義一個 capitalize 函數。示例如下:
def capitalize(data):
index = 0
temp = ''
for item in data:
if index == 0:
temp = item.upper()
else:
temp += item
index += 1
return temp
result = capitalize('hello , Jack')
print(result)
# >>> 執行結果如下
# >>> Hello , Jack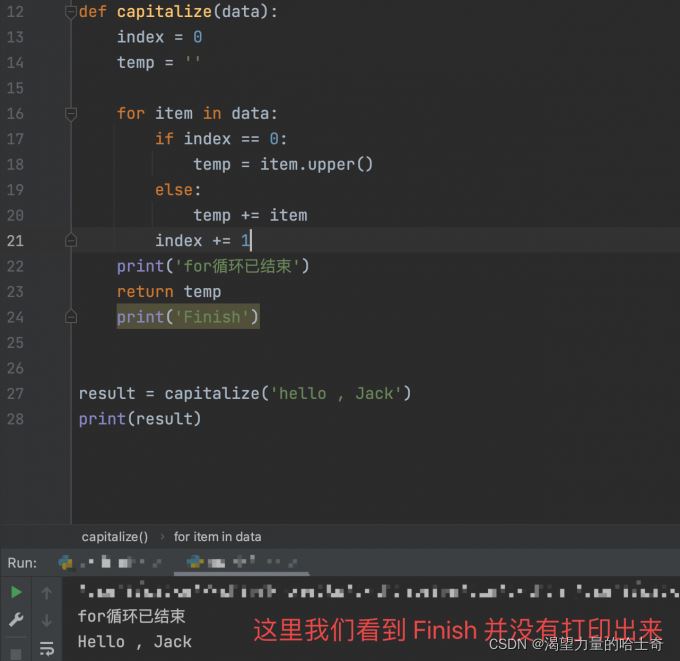
再一次注意到,只要有一個得到執行,就會直接結束函數的執行。
print 只是單純的將對象打印輸出,并不支持賦值語句。
return 是對函數執行結果的返回,且支持賦值語句;但是我們可以將含有 renturn 值的函數放在 print 里進行打印。
必傳參數:平時最常用的,必傳確定數量的參數
默認參數:在調用函數時可以傳也可以不傳,如果不傳將使用默認值
不確定參數:可變長度參數(也叫可變參數)
關鍵字參數:長度可變,但是需要以 key-value 形式傳參
什么是必傳參數? —> 在定義函數的時候,沒有默認值且必須在函數執行的時候傳遞進去的參數;且順序與參數順序相同,這就是必傳參數。
函數中定義的參數沒有默認值,在調用函數的時候,如果不傳入參數,則會報錯。
在定義函數的時候,參數后邊沒有等號與默認值。
錯誤的函數傳參方式:def add(a=1, b=1)
錯誤示例如下:
def add(a, b): return a + b result = add() print(result) # >>> 執行結果如下 # >>> TypeError: add() missing 2 required positional arguments: 'a' and 'b'
正確的示例如下:
def add(a, b): return a + b result = add(1, 2) print(result) # >>> 執行結果如下 # >>> 3 # >>> add 函數有兩個參數,第一個參數是 a,第二個參數是 b # >>> 傳入的兩個整數按照位置順序依次賦給函數的參數 a 和 b,參數 a 和參數 b 被稱為位置參數
傳遞的參數個數必須等于參數列表的數量
根據函數定義的參數位置來傳遞參數,要求傳遞的參數與函數定義的參數兩者一一對應
如果 “傳遞的參數個數” 不等于 “函數定義的參數個數”,運行時會報錯
錯誤傳參數量示例如下:
def add(a, b): return a + b sum = add(1, 2, 3) # >>> 執行結果如下 # >>> sum = add(1, 2, 3) # >>> TypeError: add() takes 2 positional arguments but 3 were given
在定義函數的時候,定義的參數含有默認值,通過賦值語句給參數一個默認的值。
使用默認參數,可以簡化函數的調用,尤其是在函數需要被頻繁調用的情況下
如果默認參數在調用函數的時候被給予了新的值,函數將優先使用新傳入的值進行工作
示例如下:
def add(a, b, c=3): return a + b + c result = add(1, 2) # 1 對應的 a ;2 對應的 b ; 沒有傳入 C 的值,使用 C 的默認值 3。 print(result) # >>> 執行結果如下 # >>> 6 def add(a, b, c=3): return a + b + c result = add(1, 2, 7) # 1 對應的 a ;2 對應的 b ; 傳入 C 的值為 7,未使用 C 的默認值 3。 print(result) # >>> 執行結果如下 # >>> 10
這種參數沒有固定的參數名和數量(不知道要傳的參數名具體是什么)
不確定參數格式如下:
def add(*args, **kwargs): pass # *args :將無參數的值合并成元組 # **kwargs :將有參數與默認值的賦值語句合并成字典
*args 代表:將無參數的值合并成元組
**kwargs 代表:將有參數與默認值的賦值語句合并成字典
從定義與概念上似乎難以理解,現在我們通過示例來看一下:
def test_args(*args, **kwargs):
print(args, type(args))
print(kwargs, type(kwargs))
test_args(1, 2, 3, name='Neo', age=18)
# >>> 執行結果如下
# >>> (1, 2, 3) <class 'tuple'>
# >>> {'name': 'Neo', 'age': 18} <class 'dict'>
# >>> args 將輸入的參數轉成了一個元組
# >>> kwargs 將輸入的賦值語句轉成了一個字典
# >>> 在使用的時候,我們還可以根據元組與字典的特性,對這些參數進行使用;示例如下:
def test_args(*args, **kwargs):
if len(args) >= 1:
print(args[2])
if 'name' in kwargs:
print(kwargs['name'])
test_args(1, 2, 3, name='Neo', age=18)
# >>> 執行結果如下
# >>> 3 根據元組特性,打印輸出 args 索引為 2 的值
# >>> Neo 根據字典特性,打印輸出 kwargs 的 key 為 name 的 value
def test_args(*args, **kwargs):
if len(args) >= 1:
print(args[2])
else:
print('當前 args 的長度小于1')
if 'name' in kwargs:
print(kwargs['name'])
else:
print('當前 kwargs 沒有 key為 name 的元素')
test_args(1, 2, 3, name1='Neo', age=18)
# >>> 執行結果如下
# >>> 3 根據元組特性,打印輸出 args 索引為 2 的值3
# >>> 當前 kwargs 沒有 key為 name 的元素(傳入的 kwargs 為 name1='Neo', age=18;沒有 name)def add(a, b=1, *args, **kwargs)
參數的定義從左到右依次是 a - 必傳參數 、b - 默認參數 、可變的 *args 參數 、可變的 **kwargs 參數
函數的參數傳遞非常有靈活性
必傳參數與默認參數的傳參也非常具有多樣化
示例如下:
def add(a, b=2): print(a + b) # 我們來看一下該函數可以通過哪些方式傳遞參數來執行 add(1, 2) # 執行結果為 : 3 add(1) # 執行結果為 : 3 add(a=1, b=2) # 執行結果為 : 3 add(a=1) # 執行結果為 : 3 add(b=2, a=1) # 執行結果為 : 3 add(b=2) # 執行結果為 : TypeError: add() missing 1 required positional argument: 'a' 。 # (因為 a 是必傳參數,這里只傳入 b 的參數是不行的)
def test(a, b, *args): print(a, b, args) int_tuple = (1, 2) test(1, 2, *int_tuple) # >>> 執行結果如下 # >>> 1 2 (1, 2) # *********************************************************** def test(a, b, *args): print(a, b, args) int_tuple = (1, 2) test(a=1, b=2, *int_tuple) # >>> 執行結果如下 # >>> TypeError: test() got multiple values for argument 'a' # >>> 提示我們參數重復,這是因為 必傳參數、默認參數、可變參數在一起時。如果需要賦值進行傳參,需要將可變參數放在第一位,然后才是 必傳參數、默認參數。(這是一個特例) # ************************************************************ def test(*args, a, b): print(a, b, args) int_tuple = (1, 2) test(a=1, b=2, *int_tuple) # >>> 執行結果如下 # >>> 1 2 (1, 2) # >>> 這種改變 必傳參數、默認參數、可變參數 的方式,一般我們是不推薦使用的
def test(a, b=1, **kwargs):
print(a, b, kwargs)
test(1, 2, name='Neo')
test(a=1, b=2, name='Jack')
test(name='Jack', age=18, a=1, b=2)
# >>> 執行結果如下
# >>> 1 2 {'name': 'Neo'}
# >>> 1 2 {'name': 'Jack'}
# >>> 1 2 {'name': 'Jack', 'age': 18}注意:如果傳參的順序發生變化,一定要使用賦值語句進行傳參。
需求:定義一個 login 函數,向函數內傳入形參 username,password,當 username 值為 admin 且password值為字符串 123456 時,返回“登錄成功”;否則返回“請重新登錄”
def login(username, password):
# 定義一個登錄函數,傳入 username, password 必填參數
if username == "admin" and password == "123456":
# 使用if語句,判斷用戶名和密碼為“admin”和“123456”
print("登錄成功") # 返回登錄成功
else:
# 使用else子句處理用戶名和密碼非“admin”和“123456”的情況
print("請重新登錄") # 返回請重新登錄
# 調用函數,向函數內傳入'admin','123456'和'test','123456'兩組數據測試結果
login(username="admin", password="123456") # 打印函數測試結果
login(username="test", password="123456") # 打印函數測試結果前文我們學習了函數的定義方法與使用方法,在定義參數的時候我們并不知道參數對應的數據類型是什么。都是通過函數體內根據業務調用場景去判斷的,如果傳入的類型與也無償性不符,就會產生報錯。現在我們學習一種方法,可以在定義函數的時候,將參數類型與參數一同定義,方便我們知道每一個參數需要傳入的數據類型。
我們來看一個例子:
def person(name:str, age:int=18): print(name, age)
必傳參數:參數名 + 冒號 + 數據類型函數 ,為聲明必傳參數的數據類型
默認參數:參數名 + 冒號 + 數據類型函數 + 等號 + 默認值,為聲明默認參數的數據類型
需要注意的是,對函數的定義數據類型在 python 3.7 之后的版本才有這個功能
雖然我們給函數參數定義了數據類型,但是在函數執行的時候仍然不會對參數類型進行校驗,依然是通過函數體內根據業務調用場景去判斷的。這個定義方法只是單純的肉眼上的查看。
示例如下:
def add(a: int, b: int = 3):
print(a + b)
add(1, 2)
add('Hello', 'World')
# >>> 執行結果如下:
# >>> 3
# >>> HelloWorld
def add(a: int, b: int = 3, *args:int, **kwargs:str):
print(a, b, args, kwargs)
add(1, 2, 3, '4', name='Neo')
# >>> 執行結果如下:
# >>> 1 2 (3, '4') {'name': 'Neo'}我們發現執行的函數并沒有報錯,add(‘Hello’, ‘World’) 也通過累加的方式拼接在了一起
所以說,雖然我們定義了 int 類型,但是并沒有做校驗,只是單純的通過肉眼告知我們參數是 int 類型,后續我們進入python高級進階階段可以自己編寫代碼進行校驗。
全局變量:在當前 py 文件都生效的變量
在 python 腳本最上層代碼塊的變量
全局變量可以在函數內被讀取使用
局部變量:在函數內部,類內部,lamda.的變量,它的作用域僅在函數、類、lamda 里面
在函數體內定義的變量
局部變量無法在自身函數以外使用
示例如下:
# coding:utf-8 name = 'Neo' age = 18 def test01(): print(name) def test02(): print(age) def test03(): print(name, age) test01() test02() test03() # >>> 執行結果如下: # >>> Neo # >>> 18 # >>> Neo 18 # >>> 這里我們可以看到聲明的 全局變量 在多個函數體內都可以被使用
示例如下:
# coding:utf-8
name = 'Neo'
age = 18
def test01():
name = 'Jack'
age = 17
print('這是函數體內的局部變量', name, age)
test01()
print('這是函數體外的全局變量', name, age)
# >>> 執行結果如下:
# >>> 這是函數體內的局部變量 Jack 17
# >>> 這是函數體外的全局變量 Neo 18
# >>> 這里我們既聲明聲明了全局變量,同時還在函數體內變更了變量的值使其成為了局部變量。
# >>> 同時,根據打印輸出的結果我們可以看出局部變量僅僅作用于函數體內。全局變量 在 函數體內真的就不能被修改么?當然是可以的,借助關鍵字 global 就可以實現。
global 關鍵字的功能:將全局變量可以在函數體內進行修改
global 關鍵字的用法:示例如下
# coding:utf-8
name = 'Neo'
def test():
global name
name = 'Jack'
print('函數體內 \'name\' 的值為:', name)
print('函數體外 \'name\' 的值為:', name)
# >>> 執行結果如下:
# >>> 函數體內 'name' 的值為: Jack
# >>> 函數體外 'name' 的值為: Jack注意:日常開發工作中,不建議使用 global 對 全局變量進行修改
再來看一個案例:
test_dict = {'name': 'Neo', 'age': '18'}
def test():
test_dict['sex'] = 'man'
test_dict.pop('age')
print('函數體內 \'test_dict\' 的值為:', test_dict)
test()
print('函數體外 \'test_dict\' 的值為:', test_dict)
# >>> 執行結果如下:
# >>> 函數體內 'test_dict' 的值為: {'name': 'Neo', 'sex': 'man'}
# >>> 函數體外 'test_dict' 的值為: {'name': 'Neo', 'sex': 'man'}前面我們是通過 global 關鍵字修改了函數體內的變量的值,為什么在這里沒有使用 global 關鍵字,在函數體內修改了 test_dict 的值卻影響到了函數體外的變量值呢?
其實,通過 global 關鍵字修改的全局變量僅支持數字、字符串、空類型、布爾類型,如果在局部變量想要使用全局變量的字典、列表類型,是不需要通過 global 關鍵字指引的。
什么是遞歸函數? —> 通俗的來說,一個函數不停的將自己反復執行,這就是遞歸函數。(通常是由于函數對自己的執行結果不滿意,才需要這樣反復的執行。)
示例如下:
def test(a): print(a) return test(a) # 通過返回值,直接執行自身的函數 test(1) # >>> 執行結果如下: # >>> 1 # >>> 1.... 會一直執行下去,有可能會造成死機,不要嘗試。
count = 0
def test():
global count
count += 1
if count != 5:
print('\'count\'的條件不滿足,需要重新執行。當前\'count\'的值為%s' % count)
return test()
else:
print('當前\'count\'的值為%s' % count)
test()
# >>> 執行結果如下:
# >>> 'count'的條件不滿足,需要重新執行。當前'count'的值為1
# >>> 'count'的條件不滿足,需要重新執行。當前'count'的值為2
# >>> 'count'的條件不滿足,需要重新執行。當前'count'的值為3
# >>> 'count'的條件不滿足,需要重新執行。當前'count'的值為4
# >>> 當前'count'的值為5首先我們要知道 遞歸函數 會造成的影響,遞歸函數 是不停的重復調用自身函數行程一個無限循環,就會造成內存溢出的情況,我們的電腦可能就要死機了。
遞歸函數雖然方便了我們用一段短小精悍的代碼便描述了一個復雜的算法(處理過程),但一定要謹慎使用。(使用循環來處理,不失為一個穩妥的方案。)
所以我們要盡量的避免使用 遞歸函數 ,如果真的要使用遞歸,一定要給予退出遞歸的方案。
lambda 函數的功能:定義一個輕量化的函數;所謂輕量化就是即用即刪除,很適合需要完成一項功能,但是此功能只在此一處使用。也就是說不會重復使用的函數,并且業務簡單的場景,我們就可以通過 lambda 來定義函數
lambda 函數的用法示例如下
# 定義匿名函數的兩種方法 # 方法1:無參數的匿名函數 test = lambda: value # lambda + 冒號 + value 值 , 賦值給一個變量 test() # 變量名 + 小括號 ,至此 lambda 匿名函數就定義完了。(value實際上是具有 return 效果的) # 方法2:有參數的匿名函數 test = lambda value,value:value*value # lambda + 兩個參數 + 冒號 + 兩個value簡單的處理 , 賦值給一個變量 test(3, 5)
# 無參數的匿名函數 test = lambda:1 result = test() print(result) # >>> 執行結果如下: # >>> 1 # ********************* # 有參數的匿名函數 test = lambda a, b: a+b result = test(1, 3) print(result) # >>> 執行結果如下: # >>> 4 # ********************* test = lambda a, b: a>b result = test(1, 3) print(result) # >>> 執行結果如下: # >>> False
再來看一個示例,加深對 lambda 匿名函數的理解
users = [{'name': 'Neo'}, {'name': 'Jack'}, {'name': 'Lily'}]
users.sort(key=lambda user_sort: user_sort['name'])
print(users)
# >>> 執行結果如下:
# >>> [{'name': 'Jack'}, {'name': 'Lily'}, {'name': 'Neo'}]
# >>> 我們看到 {'name': 'Jack'} 被排到了最前面,通過 lambda 將列表中的每個成員作為參數傳入,
# >>> 并將元素中指定 key 為 name 的 value 作為了排序對象進行排序。關于 lambda 的簡單使用,就介紹到這里。后續高級語法進階章節會對 lambda 匿名函數 的高級用法進行詳細的講解。
利用函數實現學生信息庫
現在我們學習完了 函數的基本知識 ,接下來我們進行一個總結和聯系。練習一個學生信息庫的案例,并且隨著之后的章節學習我們還會不端升級、優化這個信息庫,達到真正可以使用的功能。
接下來我們先定義出學生信息庫的基本結構,之后開發這個信息庫的增、刪、改、查功能。
# coding:utf-8
"""
@Author:Neo
@Date:2020/1/14
@Filename:students_info.py
@Software:Pycharm
"""
students = { # 定義一個學生字典,key 為 id,value 為 學生信息(name、age、class_number、sex)
1: {
'name': 'Neo',
'age': 18,
'class_number': 'A',
'sex': 'boy'
},
2: {
'name': 'Jack',
'age': 16,
'class_number': 'B',
'sex': 'boy'
},
3: {
'name': 'Lily',
'age': 18,
'class_number': 'A',
'sex': 'girl'
},
4: {
'name': 'Adem',
'age': 18,
'class_number': 'C',
'sex': 'boy'
},
5: {
'name': 'HanMeiMei',
'age': 18,
'class_number': 'B',
'sex': 'girl'
}
}
def check_user_info(**kwargs): # 定義一個 check_user_info 函數,檢查學生信息傳入食肉缺失
if 'name' not in kwargs:
return '沒有發現學生姓名'
if 'age' not in kwargs:
return '缺少學生年齡'
if 'sex' not in kwargs:
return '缺少學生性別'
if 'class_number' not in kwargs:
return '缺少學生班級'
return True
def get_all_students(): # 定義一個 get_all_students 函數,獲取所有學生信息并返回
for id_, value in students.items():
print('學號:{}, 姓名:{}, 年齡:{}, 性別:{}, 班級:{}'.format(
id_, value['name'], value['age'], value['sex'], value['class_number']
))
return students
def add_student(**kwargs): # 定義一個 add_student 函數,執行添加學生信息的操作并進行校驗,學生id 遞增
check = check_user_info(**kwargs)
if check != True:
print(check)
return
id_ = max(students) + 1
students[id_] = {
'name': kwargs['name'],
'age': kwargs['age'],
'sex': kwargs['sex'],
'class_number': kwargs['class_number']
}
def delete_student(student_id): # 定義一個 delete_student 函數,執行刪除學生信息操作,并進行是否存在判斷
if student_id not in students:
print('{} 并不存在'.format(student_id))
else:
user_info = students.pop(student_id)
print('學號是{}, {}同學的信息已經被刪除了'.format(student_id, user_info['name']))
def update_student(student_id, **kwargs): # 定義一個 update_student 函數,執行更新學生信息操作,并進行校驗
if student_id not in students:
print('并不存在這個學號:{}'.format(student_id))
check = check_user_info(**kwargs)
if check != True:
print(check)
return
students[student_id] = kwargs
print('同學信息更新完畢')
# update_student(1, name='Atom', age=16, class_number='A', sex='boy') # 執行 更新學生信息函數,并查看結果
# get_all_students()
def get_user_by_id(student_id): # 定義一個 get_user_by_id 函數,可以通過學生 id 查詢學生信息
return students.get(student_id)
# print(get_user_by_id(3))
def search_users(**kwargs): # 定義一個 search_users 函數,可以通過 學生關鍵信息進行模糊查詢
values = list(students.values())
key = None
value = None
result = []
if 'name' in kwargs:
key = 'name'
value = kwargs[key]
elif 'sex' in kwargs:
key = 'sex'
value = kwargs['sex']
elif 'class_number' in kwargs:
key = 'class_number'
value = kwargs[key]
elif 'age' in kwargs:
key = 'age'
value = kwargs[key]
else:
print('沒有發現搜索的關鍵字')
return
for user in values:
if user[key] == value:
result.append(user)
return result
users = search_users(sex='girl')
print(users)
# >>> 執行結果如下:
# >>> [{'name': 'Lily', 'age': 18, 'class_number': 'A', 'sex': 'girl'}, {'name': 'HanMeiMei', 'age': 18, 'class_number': 'B', 'sex': 'girl'}]以上是“Python函數定義與使用的示例分析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





