溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下python pandas中如何實現合并與拼接,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
在許多應用中,數據可能來自不同的渠道,在數據處理的過程中常常需要將這些數據集進行組合合并拼接,形成更加豐富的數據集。pandas提供了多種方法完全可以滿足數據處理的常用需求。具體來說包括有join、merge、concat、append等。

一般來說
| 方法 | 說明 |
|---|---|
| join | 最簡單,主要用于基于索引的橫向合并拼接 |
| merge | 最常用,主要用戶基于指定列的橫向合并拼接 |
| concat | 最強大,可用于橫向和縱向合并拼接 |
| append | 主要用于縱向追加 |
| combine_first | 合并重疊數據,填充缺失值 |
| update | 將一個數據集的值更新到另一個數據集 |
下面就來逐一介紹每個方法
join主要用于基于索引的橫向合并拼接
在介紹pandas的join之前我們來看一下SQL對數據集join的幾種模式。如果大家對SQL比較熟悉的話應該對SQL操作數據集進行各種合并拼接印象深刻。SQL中各種JOIN的方法如下:
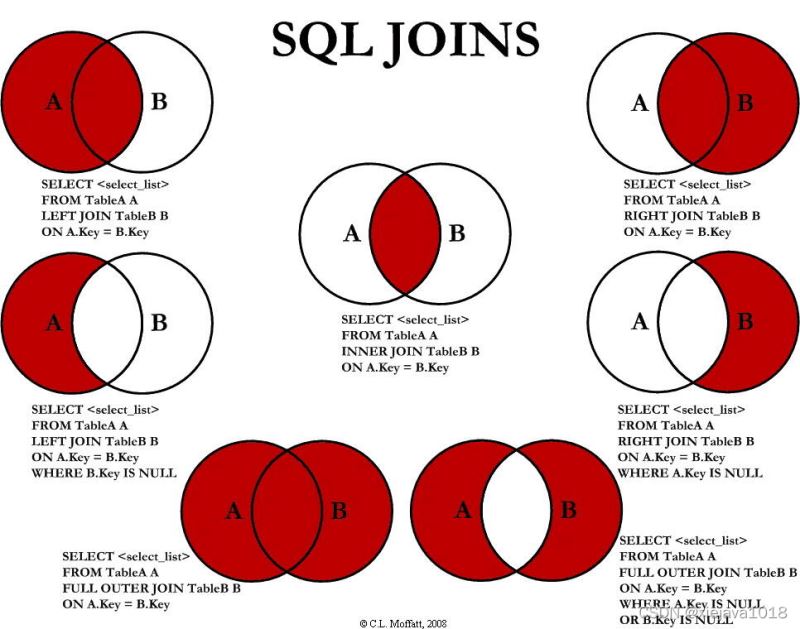
pandas的join實現了left join、right jion、inner join、out jion常用的4中join方法
來自官網的參數說明:
dataframe.join(other, # 待合并的另一個數據集 on=None, # 連接的鍵 how='left', # 連接方式:‘left', ‘right', ‘outer', ‘inner' 默認是left lsuffix='', # 左邊(第一個)數據集相同鍵的后綴 rsuffix='', # 第二個數據集的鍵的后綴 sort=False) # 是否根據連接的鍵進行排序;默認False
我們來看下實例,有兩個數據集一個是人員姓名,一個是人員的工資
left=pd.DataFrame(['張三','李四','王五','趙六','錢七'], index=[3,4,5,6,7],columns=['姓名']) right=pd.DataFrame([13000,15000,9000,8600,10000], index=[3,4,5,6,8],columns=['工資'])

注意,left和right的數據集分別都指定了index,因為join主要用于基于索引的橫向合并拼接。
left.join(right) #默認how='left'
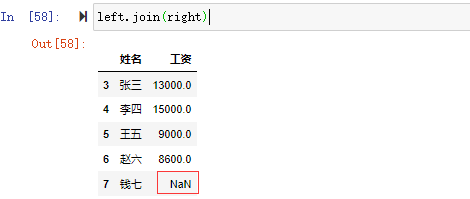
jion操作默認是left jion的操作,可以看到left索引為7姓名為錢七,在right中沒有索引為7的對應所以顯示left的姓名但right的工資為NaN,right中索引為8的數據在left中沒有索引為8的,所以沒有顯示。left join合并left的數據
left join 如下圖所示

left.join(right,how='right')
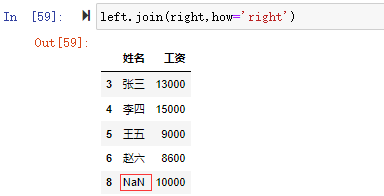
右鏈接合并時可以看到,left的數據集沒有索引為8的項,所以索引為8的項顯示right數據集的工資數據但姓名為NaN,在left中索引為7的項因為right中不存在,所以沒有顯示。right join合并right的數據
right join 如下圖所示
left.join(right,how='inner')

內鏈接合并時,可以看到left數據集中的索引為7姓名為錢七因為在right數據集中找不到對應的索引,right數據集中索引為8的在left找不到對應的索引所以內連接合并時索引7和8都沒有進行合并,inner join只合并兩個數據集共有的數據
inner join 如下圖所示
left.join(right,how='outer')
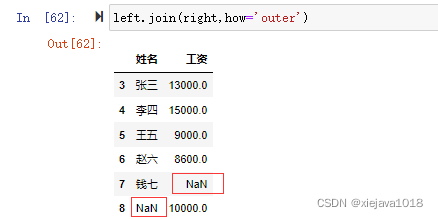
外鏈接合并時,可以看到不管是left中的數據還是right中的數據都進行了合并。right join合并兩個數據集中所有的數據。
outer join 如下圖所示
join很簡單,但是它有局限性,因為它只能根據索引來合并。不能指定鍵來進行合并。比如我要根據編號和姓名來合并,join就比較難辦了。但是pandas提供了merge的方法,可以指定列來進行合并拼接。
merge最常用,主要用戶基于指定列和橫向合并拼接,語法如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True)| 參數名稱 | 說明 |
|---|---|
| left/right | 兩個不同的 DataFrame 對象。 |
| on | 指定用于連接的鍵(即列標簽的名字),該鍵必須同時存在于左右兩個 DataFrame 中,如果沒有指定,并且其他參數也未指定, 那么將會以兩個 DataFrame 的列名交集做為連接鍵。 |
| left_on | 指定左側 DataFrame 中作連接鍵的列名。該參數在左、右列標簽名不相同,但表達的含義相同時非常有用。 |
| right_on | 指定左側 DataFrame 中作連接鍵的列名。 |
| left_index | 布爾參數,默認為 False。如果為 True 則使用左側 DataFrame 的行索引作為連接鍵,若 DataFrame 具有多層索引(MultiIndex),則層的數量必須與連接鍵的數量相等。 |
| right_index | 布爾參數,默認為 False。如果為 True 則使用左側 DataFrame 的行索引作為連接鍵。 |
| how | 要執行的合并類型,從 {‘left’, ‘right’, ‘outer’, ‘inner’} 中取值,默認為“inner”內連接。 |
| sort | 布爾值參數,默認為True,它會將合并后的數據進行排序;若設置為 False,則按照 how 給定的參數值進行排序。 |
| suffixes | 字符串組成的元組。當左右 DataFrame 存在相同列名時,通過該參數可以在相同的列名后附加后綴名,默認為(’_x’,’_y’)。 |
| copy | 默認為 True,表示對數據進行復制。 |
我們來看下面的數據集,在上面的數據集中left數據集加入了員工的編號,right數據集加入了編號及姓名。索引就按默認的索引。
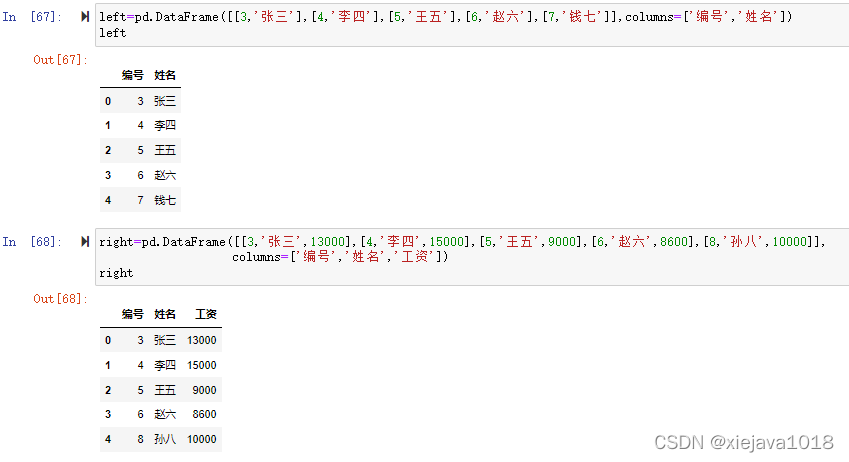
left=pd.DataFrame([[3,'張三'],[4,'李四'],[5,'王五'],[6,'趙六'],[7,'錢七']], columns=['編號','姓名']) right=pd.DataFrame([[3,'張三',13000],[4,'李四',15000],[5,'王五',9000],[6,'趙六',8600],[8,'孫八',10000]], columns=['編號','姓名','工資'])
pd.merge(left,right)
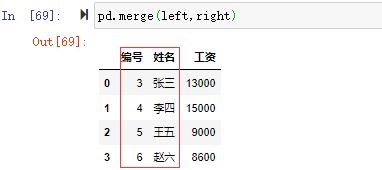
沒有指定連接鍵,默認用重疊列名,沒有指定連接方式,默認inner內連接(取left和right編號和姓名的交集)
和join一樣通過how來指定連接方式如:
pd.merge(left,right,how='left')
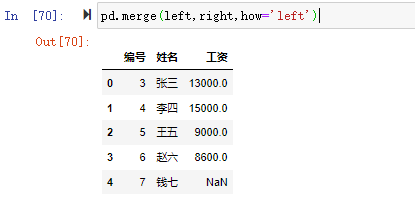
how的連接方式和join一樣支持left、right、inner、outer
merge還可以指定多個列進行合并鏈接,也就是和SQL一樣設置多個關聯的列。
pd.merge(left,right,how='outer',on=['編號','姓名'])
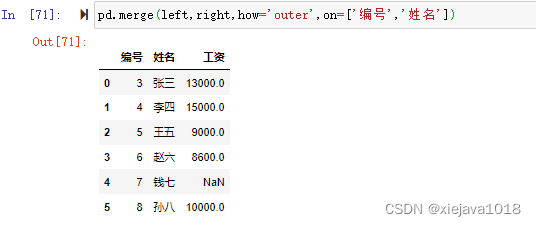
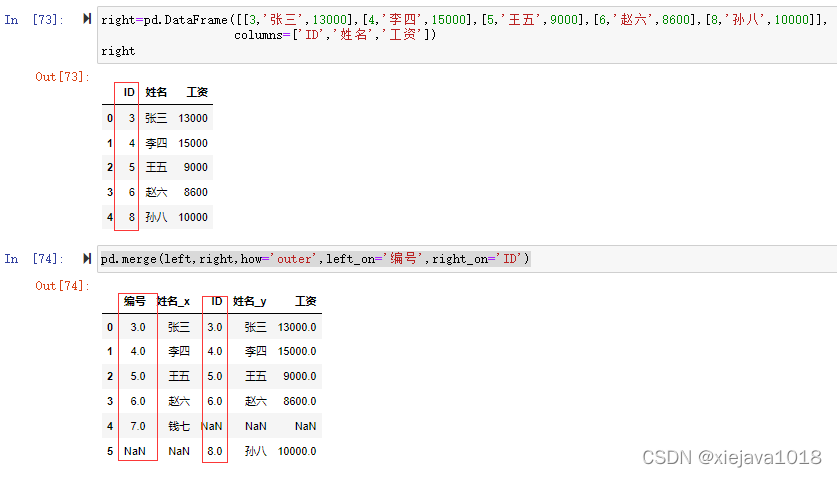
如果兩個對象的列名不同,可以使用left_on,right_on分別指定,如我們把right數據集的“編碼”列標簽改成“ID”后如果需要left數據集的"編號"和right數據集的"ID"進行關聯
right=pd.DataFrame([[3,'張三',13000],[4,'李四',15000],[5,'王五',9000],[6,'趙六',8600],[8,'孫八',10000]],columns=['ID','姓名','工資']) pd.merge(left,right,how='outer',left_on='編號',right_on='ID')
雖然說merge已經很強大了,但是pandas愿意給你更多,它提供了concat,可以實現橫向和縱向的合并與拼接。也就是說不但實現了SQL中的join還實現了union
concat() 函數用于沿某個特定的軸執行連接操作,語法如下:
pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False)
| 參數名稱 | 說明 |
|---|---|
| objs | 一個序列或者是Series、DataFrame對象。 |
| axis | 表示在哪個軸方向上(行或者列)進行連接操作,默認 axis=0 表示行方向。 |
| join | 指定連接方式,取值為{“inner”,“outer”},默認為 outer 表示取并集,inner代表取交集。 |
| ignore_index | 布爾值參數,默認為 False,如果為 True,表示不在連接的軸上使用索引。 |
| join_axes | 表示索引對象的列表。 |
來看具體的例子
left2=pd.DataFrame([[1,'陳一'],[2,'周二']],columns=['編號','姓名'])

concat默認縱向拼接,我們要在left1數據集的基礎上把left2數據集給合并上去,很簡單用concat直接就可以合并。
df=pd.concat([left,left2])

df_outer=pd.concat([left,right],axis=1,join='outer')#外鏈接 df_inner=pd.concat([left,right],axis=1,join='inner')#內鏈接
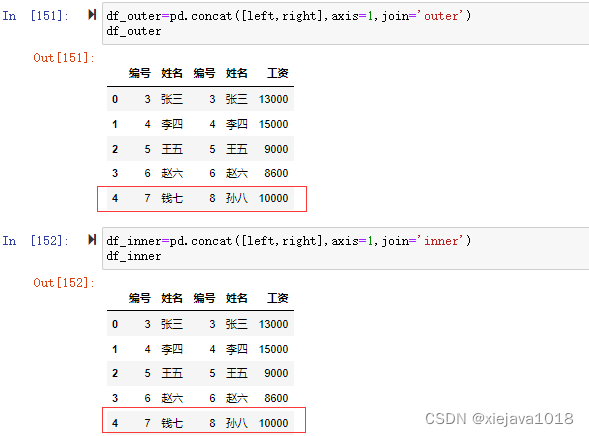
注意:因為concat的鏈接和join一樣是通過索引來鏈接合并,并不能指定通過某個特定的列來鏈接進行合并,所以看到的合并后的數據集left和right的編號和姓名是錯位的。
如果要根據編號來關聯可以指定編號作為索引再進行橫向合并,這樣就沒有問題了。
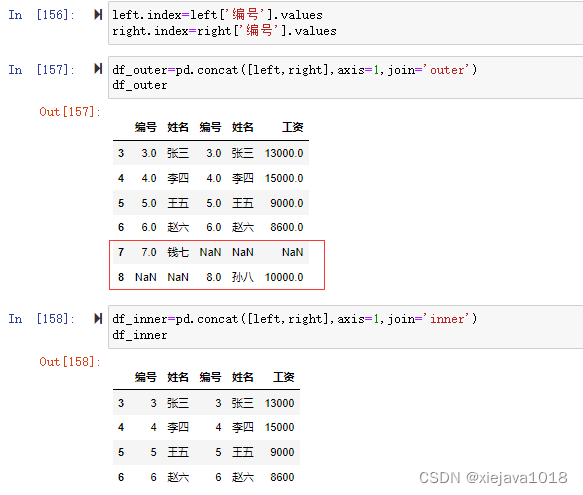
left.index=left['編號'].values right.index=right['編號'].values df_outer=pd.concat([left,right],axis=1,join='outer') df_inner=pd.concat([left,right],axis=1,join='inner')
df.append 可以將其他行附加到調用方的末尾,并返回一個新對象。它是最簡單常用的數據合并方式。語法如下:
df.append(self, other, ignore_index=False,verify_integrity=False, sort=False)
其中:
other 是它要追加的其他 DataFrame 或者類似序列內容
ignore_index 如果為 True 則重新進行自然索引
verify_integrity 如果為 True 則遇到重復索引內容時報錯
sort 進行排序
來看下面的例子:
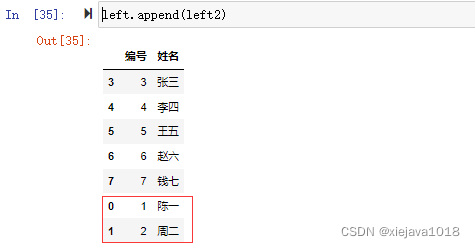
將同結構的數據追加在原數據后面,在left數據集后面追加left2數據集,left2的數據集內容如下:
left2=pd.DataFrame([[1,'陳一'],[2,'周二']],columns=['編號','姓名']) left2

left.append(left2)
不同結構數據追加,原數據沒有的列會增加,沒有對應內容的會為空NaN。
如:left3的數據集列有"編號"、“姓名”、“工資”
left3=pd.DataFrame([[8,'孫八',10000],[9,'何九',15000]],columns=['編號','姓名','工資']) left3

left.append(left3)
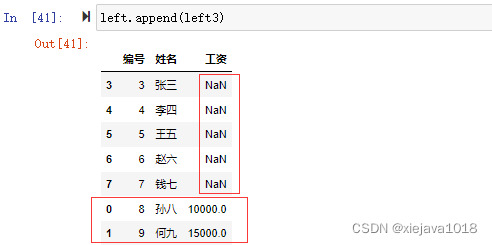
當left后追加left3后的數據集會增加“工資列”,沒有對應內容的會為空。
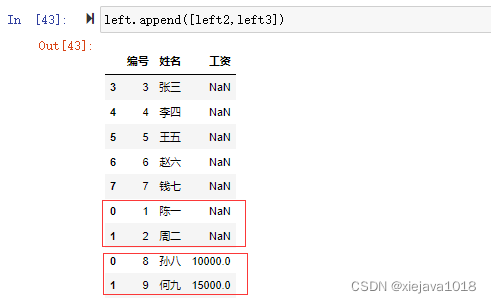
append參數可帶數據集列表,可以將多個數據集追加到原數據集
如我們將left2和left3都追加到left
left.append([left2,left3])
combine_first可用于合并重復數據,用其他數據集填充沒有的數據。如一個DataFrame數據集中出現了缺失數據,就可以用其他DataFrame數據集中的數據進行填充。語法格式如下:
combine_first(other) #只有一個參數other,該參數用于接收填充缺失值的DataFrame對象。
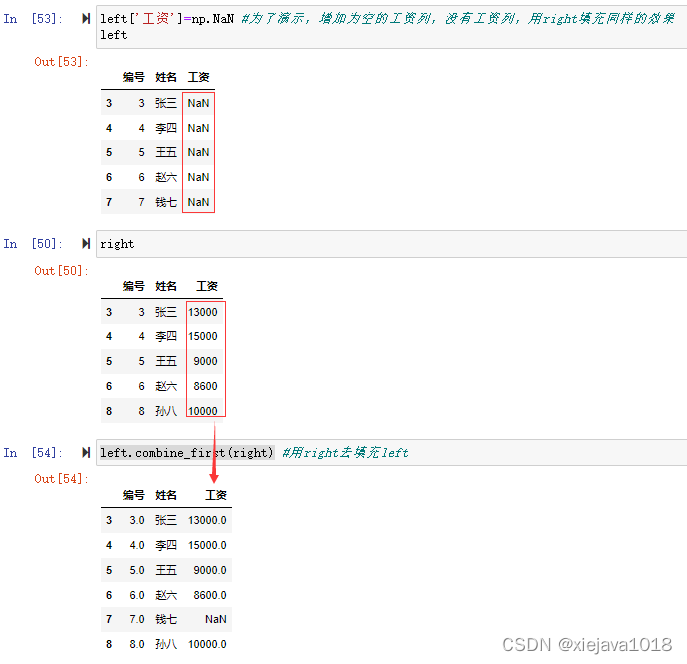
如left數據集中沒有"工資"的數據,我們可以用right數據集有的數據去填充left數據集中的數據。
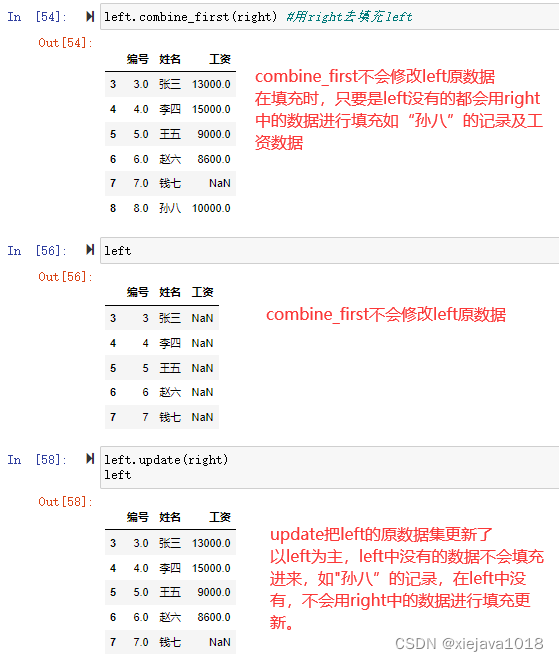
left.combine_first(right) #用right去填充left
update和combine_first比較類似,區別在于:
1、填充合并方式稍有差異
combine_first:如果s1中c的值為空,用s2的值替換,否則保留s1的值
update:如果s2中的值不為空,那么替換s1,否則保留s1的值
2、update是更新原數據,combine_first會返回一個填充后的新數據集,對原數據不做更新。
left.update(right) #用right的數據更新left中的數據。
看完了這篇文章,相信你對“python pandas中如何實現合并與拼接”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





