溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中怎么實現數據合并與追加,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
數據合并(簡單合并,無需匹配)
針對簡單合并而言,在R語言中主要通過以下兩個函數來實現:
cbind()
dplyr::bind_cols()
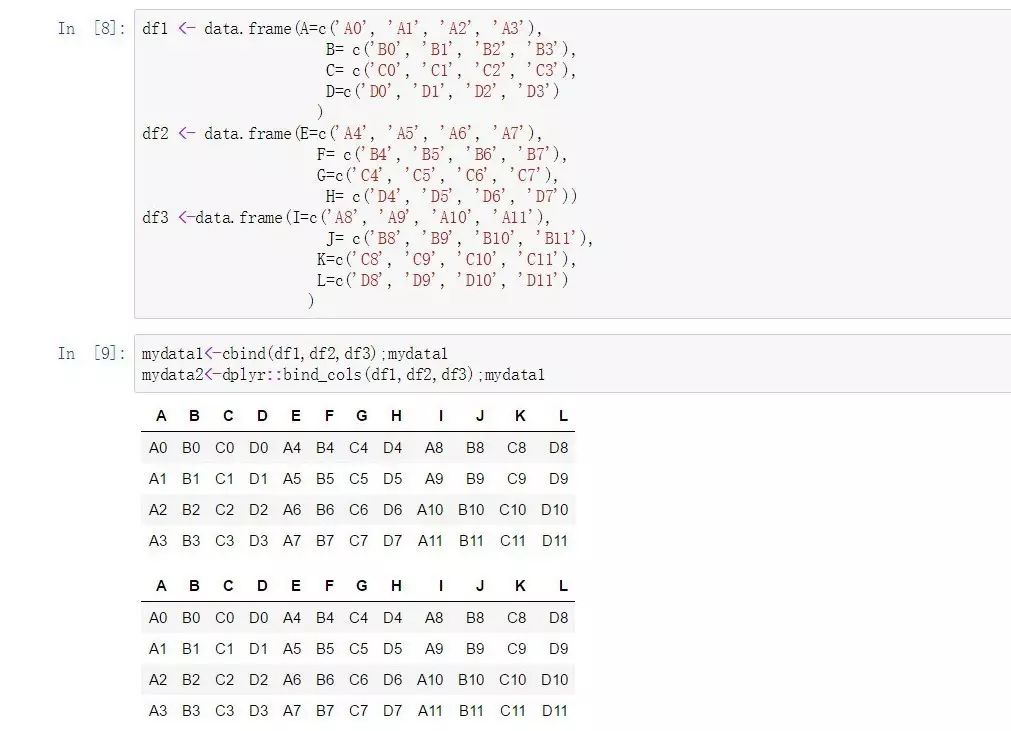
df1 <- data.frame(A=c('A0', 'A1', 'A2', 'A3'),
B= c('B0', 'B1', 'B2', 'B3'),
C= c('C0', 'C1', 'C2', 'C3'),
D=c('D0', 'D1', 'D2', 'D3')
)
df2 <- data.frame(E=c('A4', 'A5', 'A6', 'A7'),
F= c('B4', 'B5', 'B6', 'B7'),
G=c('C4', 'C5', 'C6', 'C7'),
H= c('D4', 'D5', 'D6', 'D7'))
df3 <-data.frame(I=c('A8', 'A9', 'A10', 'A11'),
J= c('B8', 'B9', 'B10', 'B11'),
K=c('C8', 'C9', 'C10', 'C11'),
L=c('D8', 'D9', 'D10', 'D11')
)
df1;df2;df3
mydata1<-cbind(df1,df2,df3);mydata1
mydata2<-dplyr::bind_cols(df1,df2,df3);mydata1
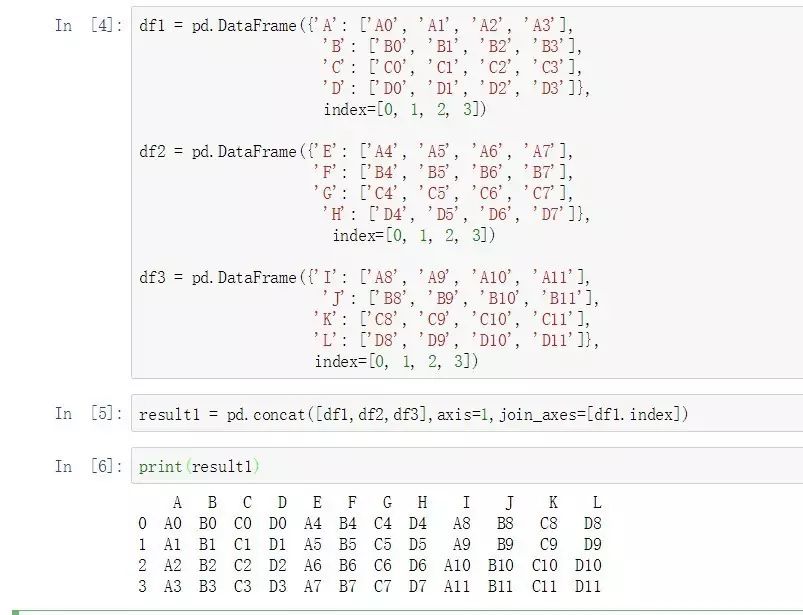
在Python中,簡單的合并可以通過Pandas中的concat函數來實現的。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'E': ['A4', 'A5', 'A6', 'A7'],
'F': ['B4', 'B5', 'B6', 'B7'],
'G': ['C4', 'C5', 'C6', 'C7'],
'H': ['D4', 'D5', 'D6', 'D7']},
index=[0, 1, 2, 3])
df3 = pd.DataFrame({'I': ['A8', 'A9', 'A10', 'A11'],
'J': ['B8', 'B9', 'B10', 'B11'],
'K': ['C8', 'C9', 'C10', 'C11'],
'L': ['D8', 'D9', 'D10', 'D11']},
index=[0, 1, 2, 3])
result1 = pd.concat([df1,df2,df3],axis=1,join_axes=[df1.index])
橫向合并:(需匹配)
在R語言中,這種操作有很多可選方案,如基礎函數merge、plyr包中的join函數以及dplyr包中的left/right/inter/full_join等函數。
merge
plyr::join
dplyr::left/right/inter/full_join
這里為了節省時間,只介紹第一種基礎函數,欲了解詳情,可以查看這篇歷史文章:
(R語言數據處理——數據合并與追加)
merge(x, y, #帶合并的數據集名稱(左右順序)
by = intersect(names(x), names(y)), #合并依據字段(名稱相同)
by.x = by, #名稱不同時需同時時聲明
by.y = by, #名稱不同時需同時時聲明
all = FALSE,#合并類型,TRUE為全連接 (full),FALSE為內連接 (inter)
all.x = all,#左連接
all.y = all,#右連接
)
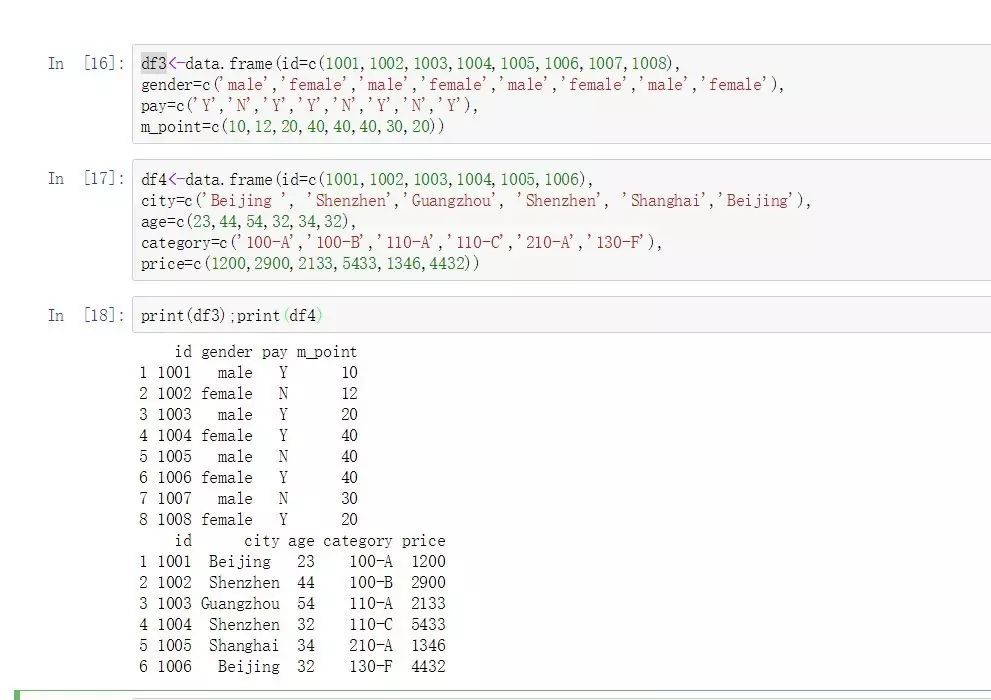
df3<-data.frame(id=c(1001,1002,1003,1004,1005,1006,1007,1008),
gender=c('male','female','male','female','male','female','male','female'),
pay=c('Y','N','Y','Y','N','Y','N','Y'),
m_point=c(10,12,20,40,40,40,30,20))
df4<-data.frame(id=c(1001,1002,1003,1004,1005,1006),
city=c('Beijing ', 'Shenzhen','Guangzhou', 'Shenzhen', 'Shanghai','Beijing'),
age=c(23,44,54,32,34,32),
category=c('100-A','100-B','110-A','110-C','210-A','130-F'),
price=c(1200,2900,2133,5433,1346,4432))
print(df3);print(df4)
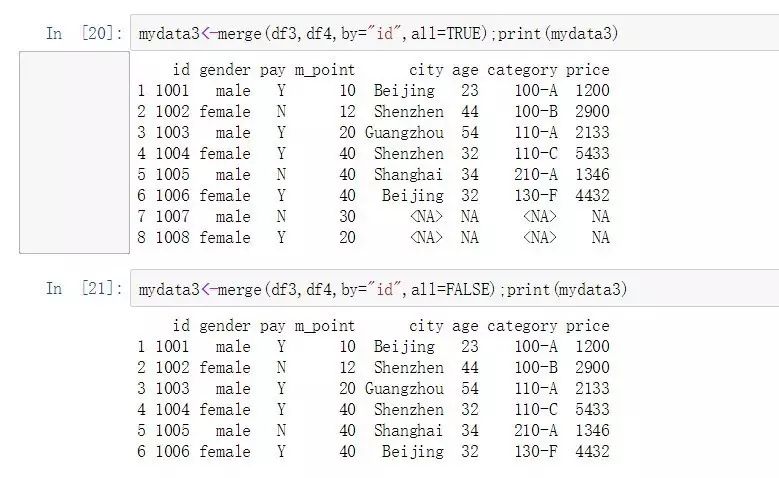
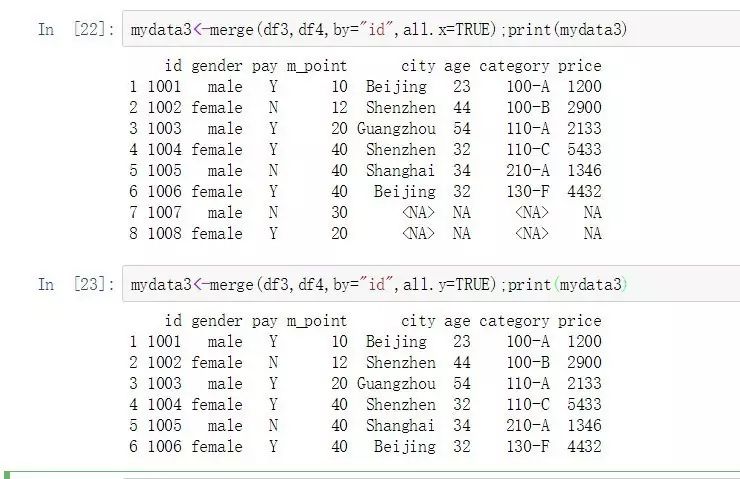
mydata3<-merge(df3,df4,by="id",all=TRUE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all=FALSE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all.x=TRUE);print(mydata3)
mydata3<-merge(df3,df4,by="id",all.y=TRUE);print(mydata3)
在Python中,這一操作也可以通過函數Pandas庫中的cancat函數或者merge函數來完成。
Pandas-merge
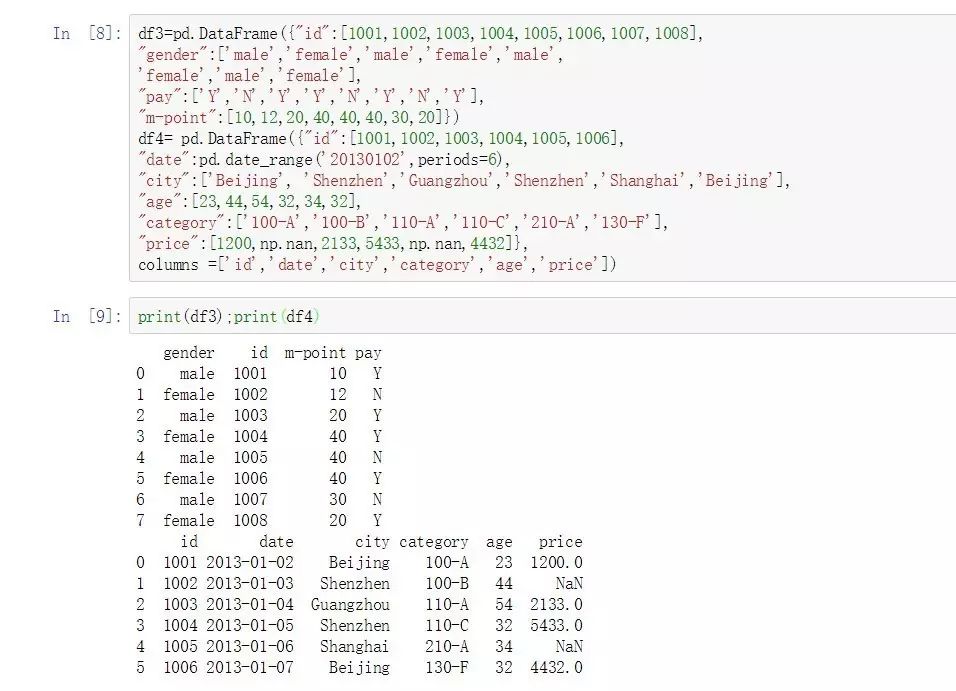
df3=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male',
'female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y'],
"m-point":[10,12,20,40,40,40,30,20]})
df4= pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102',periods=6),
"city":['Beijing', 'Shenzhen','Guangzhou','Shenzhen','Shanghai','Beijing'],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age','price'])
print(df3);print(df4)
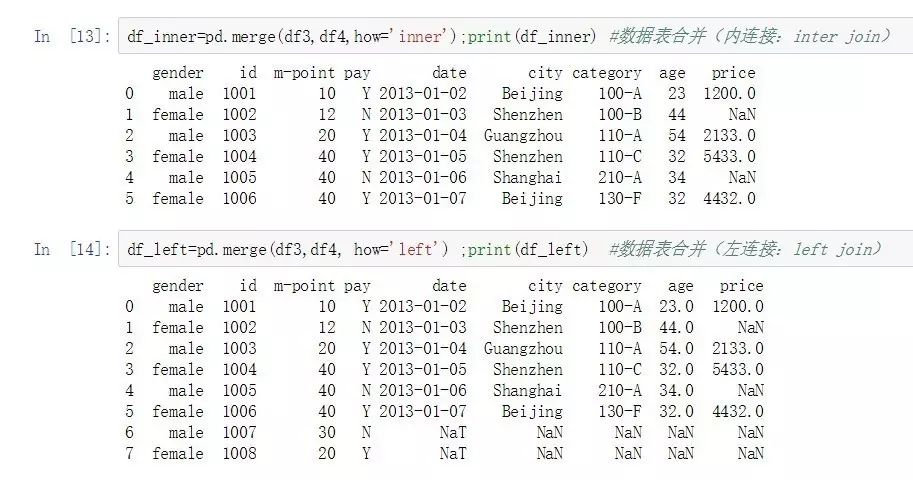
df_inner=pd.merge(df3,df4,how='inner');print(df_inner) #數據表合并(內連接:inter join)
df_left=pd.merge(df3,df4, how='left') ;print(df_left) #數據表合并(左連接:left join)
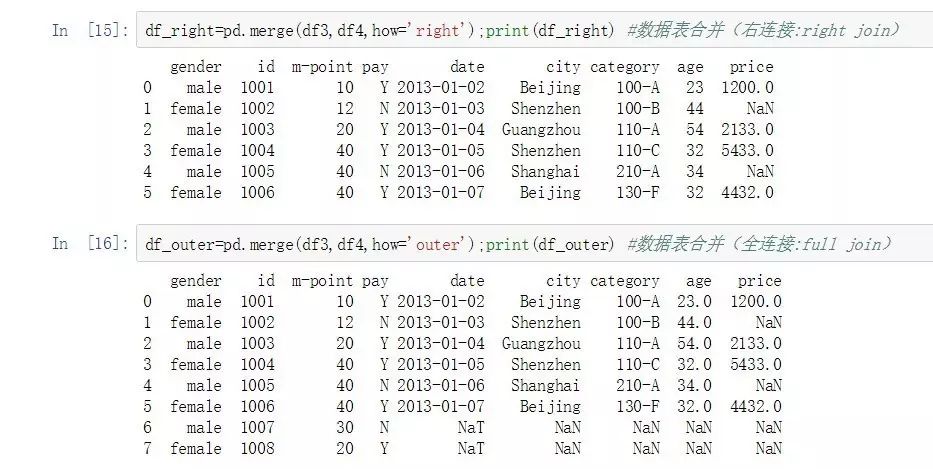
df_right=pd.merge(df3,df4,how='right');print(df_right) #數據表合并(右連接:right join)
df_outer=pd.merge(df3,df4,how='outer');print(df_outer) #數據表合并(全連接:full join)
數據追加:
數據追加通常只需保證數據及的寬度一致且列字段名稱一致,相對來說比較簡單。在R語言和Python中,也很好實現。
在R語言中,可視化朱數據追加的函數有:
rbind()
dplyr::bind_rows()
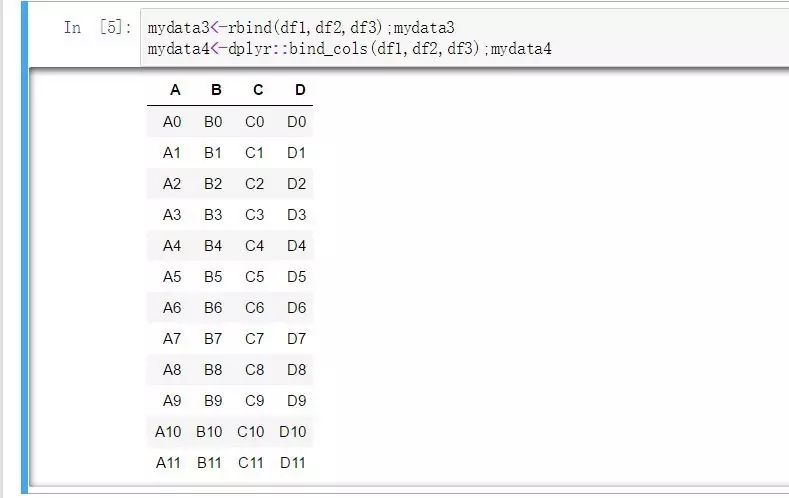
mydata3<-rbind(df1,df2,df3);mydata3
mydata4<-dplyr::bind_rows(df1,df2,df3);mydata4
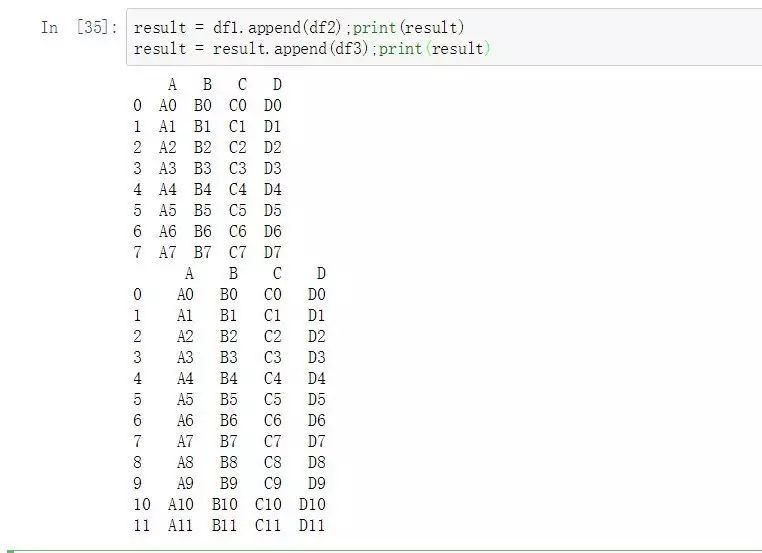
python中則可以很容易的通過數據框本身的append函數來實現簡單的數據追加:
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4,5,6,7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9,10,11])
result = df1.append(df2);print(result)
result = result.append(df3);print(result)
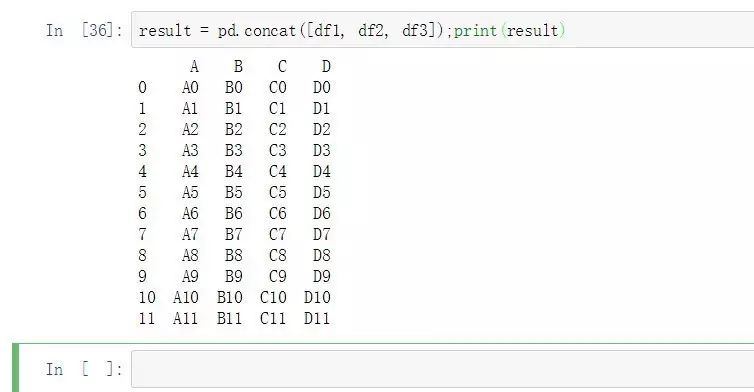
如果是使用canat函數也可以非常輕松的完成數據追加:
result = pd.concat([df1, df2, df3]);print(result)
本文匯總:
數據合并(簡單合并)
R:
cbind()
dplyr::bind_cols()
Python:
Pandas-cancat()
數據合并(匹配和并)
R:
merge
plyr::join()
dplyr::left/right/inter/full_join()
Python:
Pandas-merge
數據追加:
R:
rbind()
dplyr::bind_rows()
Python:
Pandas-append()
Pandas-cancat()
上述內容就是Python中怎么實現數據合并與追加,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





