溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Redis持久化實例分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

面試官:小伙子,談談對Redis的看法。
我:啊,看法呀,坐著看還是躺著看。Redis很小?很快?但很持久?
面試官:一本正經的說,我懷疑你在開車,不僅開開車還搞顏色。
我:。。。
面試官:去去去,我時間有限,別瞎扯淡。回到正題,你對Redis了解有多少。
我:輕量體積小、基于內存非常快、RDB配合AOF持久化讓其一樣堅挺持久。
面試官:說點具體的。
我:請看正文。

簡介
Redis是一個開源的、高性能的、基于鍵值對的緩存與存儲系統,通過提供多種鍵值數據類型來適應不同場景下的緩存與存儲需求。與此同時,Redis的諸多高層級功能讓其可以勝任消息隊列、任務隊列等不同的角色。除此之外,Redis還支持外部模塊擴展,在某些特定的場景下可以作為主數據庫使用。
由于內存的讀寫速度遠快于硬盤,就算現在的固態盤思維估計也是朝著內存那個思維模式發展的,大概也許我是個外行,但是長久存儲還是使用機械盤。所以Redis數據庫中的所有數據都存儲在內存中那是相當快的。也有一定的風險,會導致丟失數據,但配合RDB以及AOF持久化會減少風險。
此處準備的是源碼包,版本不在于最新,在于穩定適用。
其余版本在官網獲取,或者在其托管的平臺github上獲取,如下為Redis的官網下載地址。
https://redis.io/download
redis-6.0.8.tar.gz#安裝tar -zxvf redis-6.0.8.tar.gz#編譯make && make install
make[1]: *** [server.o] 錯誤 1

1.3.1、安裝依賴環境
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
1.3.2、加環境變量并生效
scl enable devtoolset-9 bashecho "/opt/rh/devtoolset-9/enable" >> /etc/profile
重新讀取環境變量配置文件
source /etc/profile
重新編譯解決問題
#切換到Redis的安裝目錄,一般源碼包安裝會放在/usr/local/下面,看個人使用習慣cd /opt/redis-6.0.8/ #編譯make && make install
常用基本命令練習可以參考菜鳥教程
https://www.runoob.com/redis/redis-commands.html
啟動redis-server服務端
#啟動redis服務nohup /opt/redis-6.0.8/src/redis-server &
登錄redis-cli客戶端
#登錄redis-cli/opt/redis-6.0.8/src/redis-cli
測試驗證,此時linux下的redis正式啟動成功,下面會帶來基本用法介紹。
pingpong

默認是沒有開放密碼設置的,需要手動開啟注釋掉的參數配置。
#編輯配置文件vim /opt/redis-6.0.8/redis.conf #原本的被注釋掉,復制一行改成你設置的密碼即可 #requirepass foobaredrequirepass 123456
Redis-x64-3.2.100.zip
2.1.1、Windows下解壓或者msi直接安裝即可。
2.1.2、設置服務命令(注冊為服務形式,自啟)
安裝服務
redis-server --service-install redis.windows-service.conf --loglevel verbose
卸載服務
redis-server --service-uninstall
redis-server redis.windows.conf
2.2.1、開啟服務
redis-server --service-start
2.2.2、停止服務
redis-server --service-stop
#同樣在redis解壓的或者安裝的目錄以管理員身份運行cmdredis-server --service-start
#在redis解壓的或者安裝的目錄以管理員身份運行cmdredis-cli.exe -h 127.0.0.1 -p 6379 #或者直接執行redis-cli #執行redis-cli #登錄測試ping
5、Windows下的管理工具rdm,是可視化界面
https://redisdesktop.com/download
面試官:redis中的數據類型有哪些,能聊聊嗎?
我:string(字符串類型)、hash(哈希類型)、list(列表類型)、set(集合類型)、zset(有序集合類型)、stream(流類型)
stream是redis5.0新增的特性支持。
面試官:嚯,小伙子有點東西啊,知道的還不少嘛,連stream流類型都知道。
我:一臉懵逼…
面試官:Redis的一些高級特性了解嗎?
我:略有了解。
面試官:能具體談談嗎?
我:飛速在大腦搜索者以前看書總結的。緩存、持久化迎面而來。
將Redis作為緩存服務器,但緩存被穿透后會對性能照成較大影響,所有緩存同時失效緩存雪崩,從而使服務無法響應。
我們希望Redis能將數據從內存中以某種形式同步到磁盤中,使之重啟以后根據磁盤中的記錄恢復數據。這一過程就是持久化。
面試官:知道Redis有哪幾種常見的持久化方式嗎?
我:Redis默認開啟的RDB持久化,AOF持久化方式需要手動開啟。
Redis支持兩種持久化。一種是RDB方式,一種是AOF方式。前者會根據指定的規則“定時”將內存中的數據存儲到硬盤上,而后者在每次執行命令后將命令本書記錄下來。對于這兩種持久化方式,你可以單獨使用其中一種,但大多數情況下是將二者緊密結合起來。
此時的面試官一臉期待,炯炯有神的看向了我,請繼續。
繼續介紹,RDB采取的是快照方式,默認設置自定義快照【自動同步】,默認配置如下。

同樣可以手動同步
#不推薦在生產環境中使用SAVE
#異步形式BGSAVE
#基于自定義快照FLASHALL
當使用Redis存儲非臨時數據時,一般需要打開AOF持久化來降低進程終止導致數據的丟失。AOF可以將Redis執行的每一條命令追加到硬盤文件中,著這個過程中顯然會讓Redis的性能打折扣,但大部分情況下這種情況可以接受。這里強調一點,使用讀寫較快的硬盤可以提高AOF的性能。
默認沒有開啟,需要手動開啟AOF,當你查看redis.conf文件時也會發現appendonly配置的是no
appendonly yes
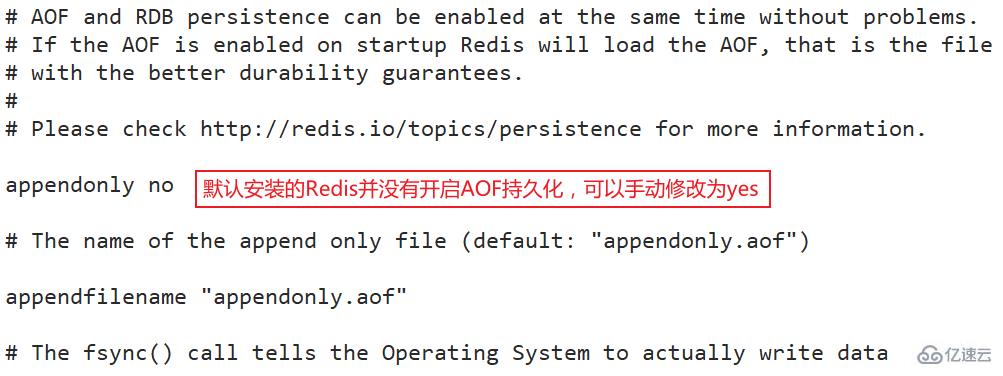
開啟AOF持久化后,每次執行一條命令會會更改Redis中的數據的目錄,Redis會將該命令寫入磁盤中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通過dir參數設置,默認的文件名是appendonly.aof,可以通過appendfilename參數修改。
appendfilename "appendonly.aof

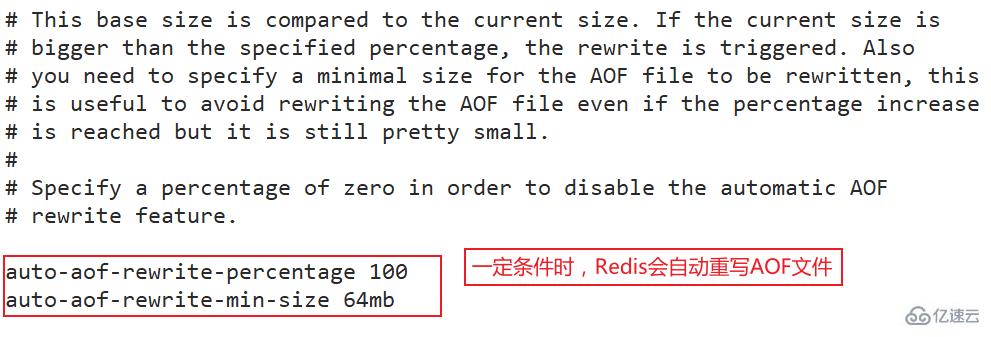
實際上Redis也正是這樣做的,每當達到一定的條件時Redis就會自動重寫AOF文件,這個條件可以通過redis.conf配置文件中設置:
auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
在啟動時Redis會逐行執行AOF文件中的命令將硬盤中的數據加載到內存中,加載的速度相比RDB會慢一些。
雖然每次執行更改數據庫內容的操作時,AOF都將命令記錄在AOF文件中。但事實上,由于操作系統的緩存機制,數據并沒與真正寫入硬盤,而是進入了操作系統的硬盤緩存。在默認情況下,操作系統每30秒會執行一次同步操作,以便將硬盤緩存中的內容寫入硬盤。
在Redis中可以通過appendfsync設置同步的時機:
# appendfsync always #默認設置為everysecappendfsync everysec # appendfsync no
Redis允許同時開啟AOF和RDB。這樣既保證了數據的安全,又對進行備份等操作比較友好。此時重新啟動Redis后,會使用AOF文件來恢復數據。因為AOF方式的持久化,將會丟失數據的概率降至最小化。
通過持久化功能,Redis保證了即使服務器重啟的情況下也不會丟失(少部分遺失)數據。但是數據庫是存儲在單臺服務器上的,難免不會發生各種突發情況,比如硬盤故障,服務器突然宕機等等,也會導致數據遺失。
為了盡可能的避免故障,通常做法是將數據庫復制多個副本以部署在不同的服務器上。這樣即使有一臺出現故障,其它的服務器依舊可以提供服務。為此,Redis提供了復制(replication)功能。即實現一個數據庫中的數據更新后,自動將更新的數據同步到其它數據庫上。
此時熟悉MySQL的同學,是不是覺得與MySQL的主從復制很像,以開啟二進制日志binlog實現同步復制。
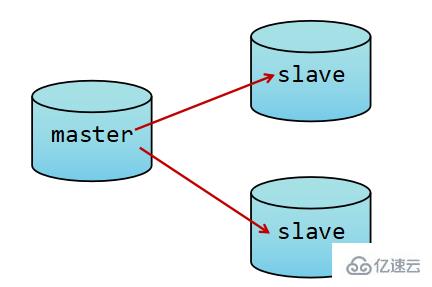
而Redis中使用復制功能更為容易,相比MySQL而言。只需要在從庫中啟動時加入slaveof 從數據庫地址。
#在從庫中配置slaveof master_database_ip_addr #測試,加了nohup與&是放入后臺,并且輸出日志到/root/目錄下的nohup.outnohup /opt/redis-6.0.8/src/redis-server --6380 --slaveof 192.168.245.147 6379 &

復制初始化。這里主要原理是從庫啟動,會向主庫發送SYNC命令。同時主庫接收到SYNC命令后會開始在后臺保存快照,即RDB持久化的過程,并將快照期間接收的命令緩存起來。當快照完成后,Redis會將快照文件和所有緩存的命令發送給從數據庫。從數據庫收到后,會載入快照文件并執行收到的緩存命令。
復制同步階段會貫穿整個主從同步過程,直到主從關系終止為止。在復制的過程中快照起到了至關重要的作用,只要執行復制就會進行快照,即使關閉了RDB方式的持久化,通過刪除所有save參數。
Redis采用了樂觀復制(optimistic replication)的復制策略。容忍在一定時間內主從數據庫的內容是不同的,但是兩者的數據最終是會同步的。具體來講,Redis在主從數據庫之間復制數據的過程本身是異步的,這就意味著,主數據庫執行完客戶端請求的命令會立即將命令在主數據庫的執行結果反饋給客戶端,并異步的將數據同步給從庫,不會等待從數據庫接收到該命令在返回給客戶端。
當數據至少同步給指定數量的從庫時,才是可寫,通過參數指定:
#設置最少限制3min-slaves-to-write 3 #設置允許從數據最長失去連接時間min-slaves-max-lag 10
基于以下三點實現
從庫會存儲主庫的運行ID(run id)。每個Redis運行實例均會擁有一個唯一運行ID,每當實例重啟后,就會自動生成一個新的運行ID。類似于MySQL的從節點配置的唯一ID去識別。
在復制同步階段,主庫一條命令被傳送到從庫時,會同時把該命令存放到一個積壓隊列(backlog)中,記錄當前積壓隊列中存放的命令的偏移量范圍。
從庫接收到主庫傳來的命令時,會記錄該命令的偏移量。
當主數據庫崩潰時,情況略微復雜。手動通過從數據庫數據庫恢復主庫數據時,需要嚴格遵循以下原則:
在從數據庫中使用SLAVEOF NO ONE命令將從庫提升為主庫繼續服務。
啟動之前崩潰的主庫,然后使用SLAVEOF命令將其設置為新的主庫的從庫。
注意:當開啟復制且數據庫關閉持久化功能時,一定不要使用supervisor以及類似的進程管理工具令主庫崩潰后重啟。同樣當主庫所在的服務器因故障關閉時,也要避免直接重新啟動。因為當主庫重啟后,沒有開啟持久化功能,數據庫中所有數據都被清空。此時從庫依然會從主庫中接收數據,從而導致所有從庫也被清空,導致數據庫的持久化開了個寂寞。
手動維護確實很麻煩,好在Redis提供了一種自動化方案:哨兵去實現這一過程,避免手動維護易出錯的問題。
從Redis的復制歷中,我們了解到在一個典型的一主多從的Redis系統中,從庫在整個系統中起到了冗余備份以及讀寫分離的作用。當主庫遇到異常中斷服務后,開發人員手動將從升主時,使系統繼續服務。過程相對復雜,不好實現自動化。此時可借助哨兵工具。
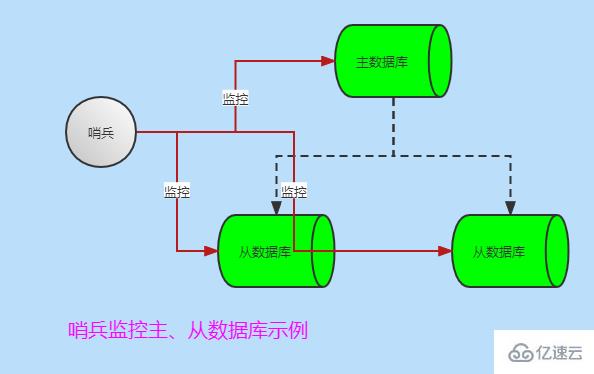
哨兵的作用
監控Redis系統運行情況
監控主庫和從庫是否正常運行
主庫gg思密達,自動將從庫升為主庫,美滋滋
當然也有多個哨兵監控主從數據庫模式,哨兵之間也會互相監控,如下圖:
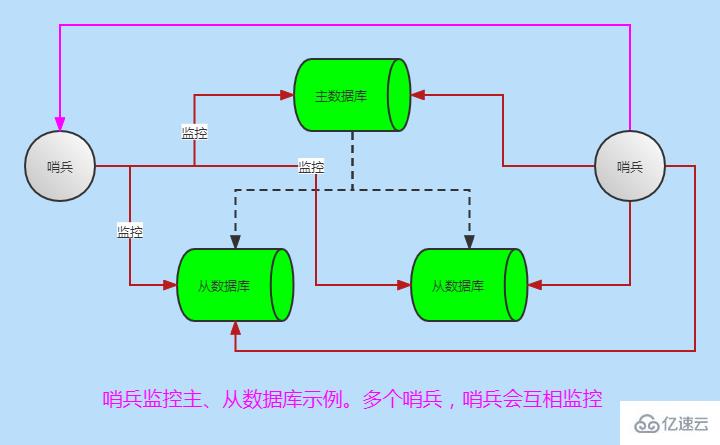
首先需要建立起一主多從的模型,然后開啟配置哨兵。
#主庫sentinel monitor master 127.0.0.1 6379 1 #建立配置文件,例如sentinel.confredis-sentinel /opt/path/to/sentinel.conf
關于哨兵就介紹這么多,現在大腦中有印象。至少知道有那么回事,可以和美女面試官多掰扯掰扯。
從Redis3.0開始加入了集群這一特性。
即使使用哨兵,此時的Redis集群的每個數據庫依然存有集群中的所有數據,從而導致集群的總數據存儲量受限于可用內存最小的數據庫節點,繼而出現木桶效應。正因為Redis所有數據都是基于內存存儲,問題已經很突出,尤其是當Redis作為持久化存儲服務時。
有這樣一種場景。就擴容來說,在客戶端分片后,如果像增加更多的節點,需要對數據庫進行手動遷移。遷移的過程中,為了保證數據的一致性,需要將進群暫時下線,相對比較復雜。
此時考慮到Redis很小,啊不口誤,是輕量的特點。可以采用預分片(presharding)在一定程度上避免問題的出現。換句話說,就是在部署的初期,提前考慮日后的存儲規模,建立足夠多的實例。
從上面的理論知識來看,哨兵和集群類似,但哨兵和集群是兩個獨立的功能。如果要進行水平擴容,集群是不錯的選擇。
配置集群,開啟配置文件redis.conf中的cluster-enabled
cluster-enabled yes

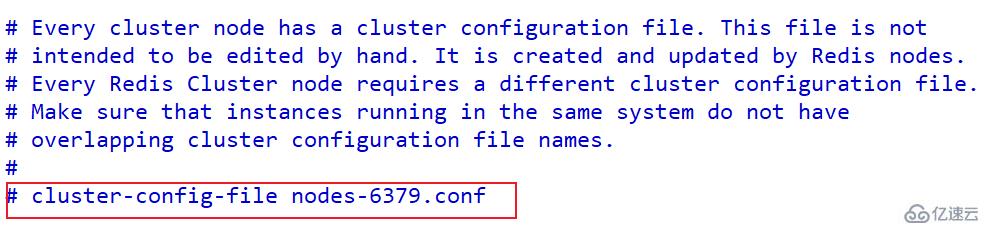
配置集群每個節點配置不同工作目錄,或者修改持久化文件
cluster-config-file nodes-6379.conf
集群測試大家可以執行配置,參考其他書籍亦可,實現并不難。只要是知其原理。
示例
package com.jedis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class Test {
@org.junit.Test
public void demo() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.set("name", "sky");
String params = jedis.get("jedis");
System.out.println(params);
jedis.close();
}
@org.junit.Test
public void config() {
// 獲取連接池的配置對象
JedisPoolConfig config = new JedisPoolConfig();
// 設置最大連接數
config.setMaxTotal(30);
// 設置最大空閑連接數
config.setMaxIdle(10);
// 獲取連接池
JedisPool pool = new JedisPool(config, "127.0.0.1", 6379);
// 獲得核心對象
Jedis jedis = null;
try {
//通過連接池獲取連接
jedis = pool.getResource();
//設置對象
jedis.set("poolname", "pool");
//獲取對象
String pools = jedis.get("poolname");
System.out.println("values:"+pools);
} catch (Exception e) {
e.printStackTrace();
}finally{
//釋放資源
if(jedis != null){
jedis.close();
}
if(pool != null){
pool.close();
}
}
}}“Redis持久化實例分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





