溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何使用Python對口紅進行數據分析來選定情人節禮物的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
實現案例之前,我們要先安裝一個谷歌驅動,因為我們是使用selenium 操控谷歌驅動,然后操控瀏覽器實現自動操作的,模擬人的行為去操作瀏覽器。
以谷歌瀏覽器為例,打開瀏覽器看下我們自己的版本,然后下載跟自己瀏覽器版本一樣或者最相近的版本,下載后解壓一下,把解壓好的插件放到我們的python環境里面,或者和代碼放到一起也可以。
selenium pip install selenium ,直接輸入selenium的話是默認安裝最新的,selenium后面加上版本號就是安裝對應的的版本;
csv 內置模塊,不需要安裝,把數據保存到Excel表格用的;
time 內置模塊,不需要安裝,時間模塊,主要用于延時等待;
我們訪問一個網站,要輸入一個網址,所以代碼也是這么寫的。
首先導入模塊
from selenium import webdriver
文件名或者包名不要命名為selenium,會導致無法導入。 webdriver可以認為是瀏覽器的驅動器,要驅動瀏覽器必須用到webdriver,支持多種瀏覽器。
實例化瀏覽器對象 ,我這里用的是谷歌,建議大家用谷歌,方便一點。
driver = webdriver.Chrome()
我們用get訪問一個網址,自動打開網址。
driver.get('https://www.jd.com/')運行一下
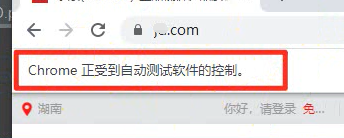
打開網址后,以買口紅為例。
我們首先要通過你想購買的商品關鍵字來搜索得到商品信息,用搜索結果去獲取信息。
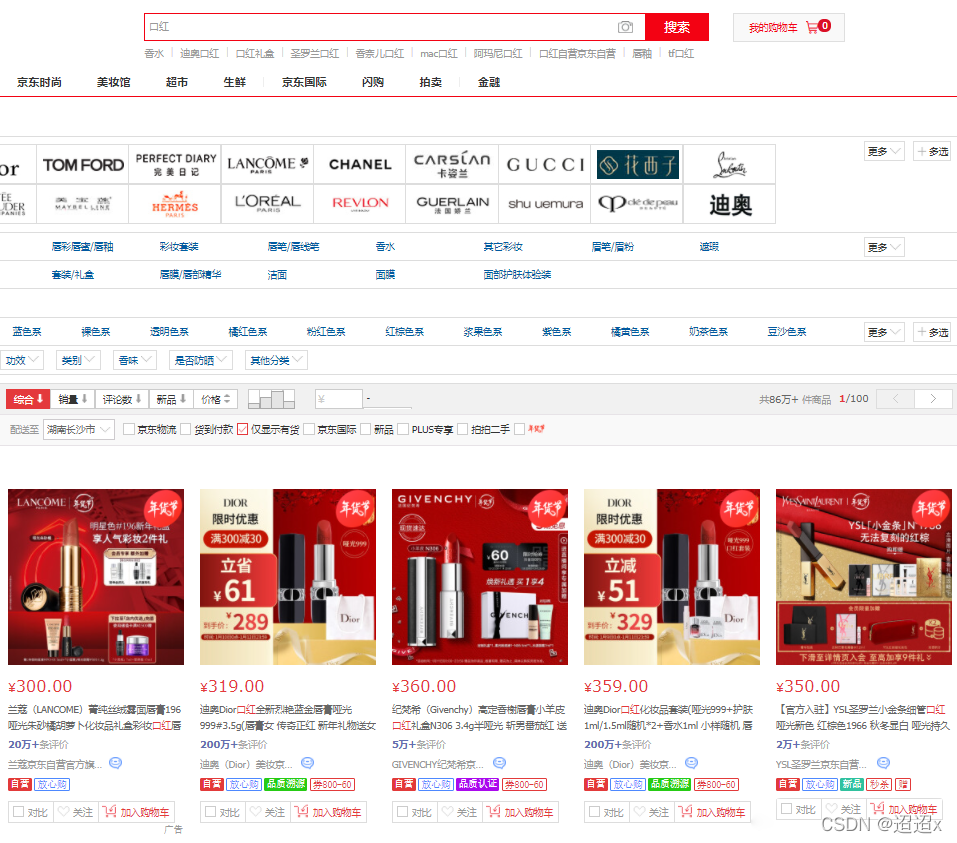
那我們也要寫一個輸入,空白處點擊右鍵,選擇檢查。選擇element 元素面板

鼠標點擊左邊的箭頭按鈕,去點擊搜索框,它就會直接定位到搜索標簽。在標簽上點擊右鍵,選擇copy,選擇copy selector 。如果你是xpath ,就copy它的xpath 。然后把我們想要搜索的內容寫出來
driver.find_element_by_css_selector('#key').send_keys('口紅')再運行的時候,它就會自動打開瀏覽器進入目標網址搜索口紅。
同樣的方法,找到搜索按鈕進行點擊。
driver.find_element_by_css_selector('.button').click()再運行就會自動點擊搜索了,頁面搜索出來了,那么咱們正常瀏覽網頁是要下拉網頁對吧,咱們讓它自動下拉就好了。 先導入time模塊
import time
執行頁面滾動的操作
def drop_down(): """執行頁面滾動的操作""" # javascript for x in range(1, 12, 2): # for循環下拉次數,取1 3 5 7 9 11, 在你不斷的下拉過程中, 頁面高度也會變的; time.sleep(1) j = x / 9 # 1/9 3/9 5/9 9/9 # document.documentElement.scrollTop 指定滾動條的位置 # document.documentElement.scrollHeight 獲取瀏覽器頁面的最大高度 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j driver.execute_script(js) # 執行我們JS代碼
循環寫好了,然后調用一下。
drop_down()
我們再給它來個延時
driver.implicitly_wait(10)
這是一個隱式等待,等待網頁延時,網不好的話加載很慢。
隱式等待不是必須等十秒,在十秒內你的網絡加載好后,它隨時會加載,十秒后沒加載出來的話才會強行加載。
還有另外一種死等的,你寫的幾秒就等幾秒,相對沒有那么人性化。
time.sleep(10)
加載完數據后我們需要去找商品數據來源
價格/標題/評價/封面/店鋪等等
還是鼠標右鍵點擊檢查,在element ,點擊小箭頭去點擊你想查看的數據。
可以看到都在li標簽里面 獲取所有的 li 標簽內容,還是一樣的,直接copy 。 在左下角就有了 這里表示的是取的第一個,但是我們是要獲取所有的標簽,所以左邊框框里 li 后面的可以刪掉不要。 不要的話,可以看到這里是60個商品數據,一頁是60個。 所以我們把剩下的復制過來, 用lis接收一下 。
lis = driver.find_elements_by_css_selector('#J_goodsList ul li')因為我們是獲取所有的標簽數據,所以比之前多了一個s

打印一下
print(lis)
通過lis返回數據 列表 [] 列表里面的元素 <> 對象

遍歷一下,把所有的元素拿出來。
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品標題 獲取標簽文本數據
price = li.find_element_by_css_selector('.p-price strong i').text # 價格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 評論量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店鋪名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品詳情頁
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推導式 ','.join 以逗號把列表中的元素拼接成一個字符串數據
dit = {
'商品標題': title,
'商品價格': price,
'評論量': commit,
'店鋪名字': shop_name,
'標簽': icon,
'商品詳情頁': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')搜索功能
key_world = input('請輸入你想要獲取商品數據: ')要獲取的數據 ,獲取到后保存CSV
f = open(f'京東{key_world}商品數據.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品標題',
'商品價格',
'評論量',
'店鋪名字',
'標簽',
'商品詳情頁',
])
csv_writer.writeheader()然后再寫一個自動翻頁
for page in range(1, 11):
print(f'正在爬取第{page}頁的數據內容')
time.sleep(1)
drop_down()
get_shop_info() # 下載數據
driver.find_element_by_css_selector('.pn-next').click() # 點擊下一頁from selenium import webdriver
import time
import csv
def drop_down():
"""執行頁面滾動的操作"""
for x in range(1, 12, 2):
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滾動條的位置
# document.documentElement.scrollHeight 獲取瀏覽器頁面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 執行JS代碼
key_world = input('請輸入你想要獲取商品數據: ')
f = open(f'京東{key_world}商品數據.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品標題',
'商品價格',
'評論量',
'店鋪名字',
'標簽',
'商品詳情頁',
])
csv_writer.writeheader()
# 實例化一個瀏覽器對象
driver = webdriver.Chrome()
driver.get('https://www.jd.com/') # 訪問一個網址 打開瀏覽器 打開網址
# 通過css語法在element(元素面板)里面查找 #key 某個標簽數據 輸入一個關鍵詞 口紅
driver.find_element_by_css_selector('#key').send_keys(key_world) # 找到輸入框標簽
driver.find_element_by_css_selector('.button').click() # 找到搜索按鈕 進行點擊
# time.sleep(10) # 等待
# driver.implicitly_wait(10) # 隱式等待
def get_shop_info():
# 第一步 獲取所有的li標簽內容
driver.implicitly_wait(10)
lis = driver.find_elements_by_css_selector('#J_goodsList ul li') # 獲取多個標簽
# 返回數據 列表 [] 列表里面的元素 <> 對象
# print(len(lis))
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品標題 獲取標簽文本數據
price = li.find_element_by_css_selector('.p-price strong i').text # 價格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 評論量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店鋪名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品詳情頁
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推導式 ','.join 以逗號把列表中的元素拼接成一個字符串數據
dit = {
'商品標題': title,
'商品價格': price,
'評論量': commit,
'店鋪名字': shop_name,
'標簽': icon,
'商品詳情頁': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
# print(href)
for page in range(1, 11):
print(f'正在爬取第{page}頁的數據內容')
time.sleep(1)
drop_down()
get_shop_info() # 下載數據
driver.find_element_by_css_selector('.pn-next').click() # 點擊下一頁
driver.quit() # 關閉瀏覽器

感謝各位的閱讀!關于“如何使用Python對口紅進行數據分析來選定情人節禮物”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





