溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用python提取chrome瀏覽器的歷史記錄及收藏夾”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1.打開 chrome瀏覽器,輸入 chrome://version,進入瀏覽器版本信息頁面 2.復制頁面下圖,劃線地址
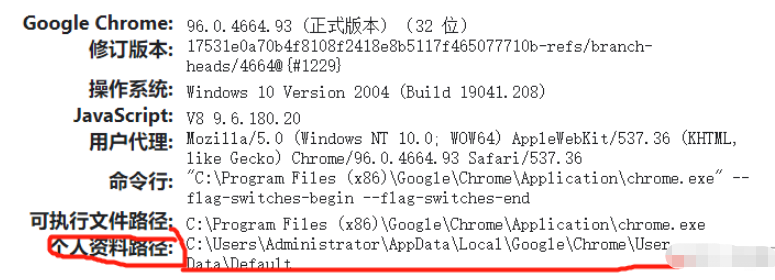
上面我的chrome瀏覽器的緩存路徑是:
C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Default
瀏覽器的收藏夾的數據,記錄在Bookmarks文件里面
Bookmark文件的內容格式是json

解析代碼為
import os import json #chrome data path path = "C:/Users/Administrator/AppData/Local/Google/Chrome/User Data/Default" #chrome browser bookmark class BookMark: def __init__(self,chromePath=path): #chromepath self.chromePath = chromePath #parse bookmarks with open(os.path.join(path,'Bookmarks'),encoding='utf-8') as f: bookmarks = json.loads(f.read()) self.bookmarks = bookmarks #folders self.folders = self.get_folders() def get_folders(self): #folders names = [ (i,self.bookmarks['roots'][i]['name']) for i in self.bookmarks['roots'] ] return names def get_folder_data(self,folder=0): return self.bookmarks['roots'][self.folders[folder][0]]['children'] def set_chrome_path(self,chromePath): self.chromePath = chromePath def refresh(self): 'update chrome data from chrome path' #parse bookmarks with open(os.path.join(path,'Bookmarks'),encoding='utf-8') as f: bookmarks = json.loads(f.read()) self.bookmarks = bookmarks
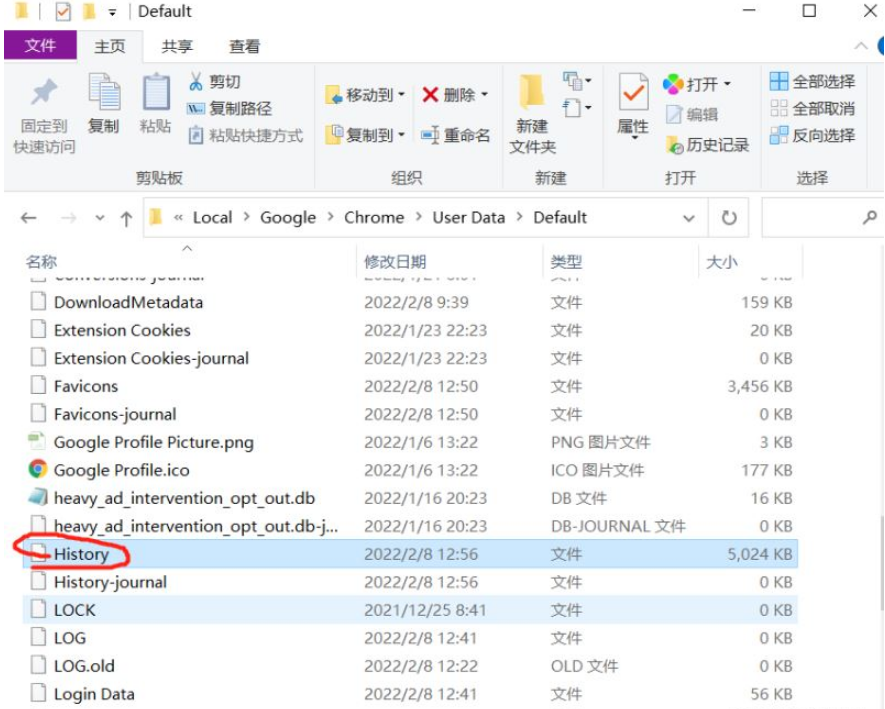
歷史數據,存儲在下面的History文件里面,內容格式是sqlite的數據庫文件,可以直接使用sqlite3來解析,當然也可以使用DB Browser for SQLite來圖形化界面顯示History sqlite數據文件。
import os
import sqlite3
#chrome data path
path = "C:/Users/Administrator/AppData/Local/Google/Chrome/User Data/Default"
#History
class History:
def __init__(self,chromePath=path):
self.chromePath = chromePath
def connect(self):
self.conn = sqlite3.connect(os.path.join(self.chromePath,"History"))
self.cousor = self.conn.cursor()
def close(self):
self.conn.close()
def get_history(self):
cursor = self.conn.execute("SELECT id,url,title,visit_count from urls")
rows = []
for _id,url,title,visit_count in cursor:
row = {}
row['id'] = _id
row['url'] = url
row['title'] = title
row['visit_count'] = visit_count
rows.append(row)
return rowsimport os
import sqlite3
#chrome data path
path = "C:/Users/Administrator/AppData/Local/Google/Chrome/User Data/Default"
#History
class History:
def __init__(self,chromePath=path):
self.chromePath = chromePath
def connect(self):
self.conn = sqlite3.connect(os.path.join(self.chromePath,"History"))
self.cousor = self.conn.cursor()
def close(self):
self.conn.close()
def get_history(self):
cursor = self.conn.execute("SELECT id,url,title,visit_count from urls")
rows = []
for _id,url,title,visit_count in cursor:
row = {}
row['id'] = _id
row['url'] = url
row['title'] = title
row['visit_count'] = visit_count
rows.append(row)
return rows“怎么使用python提取chrome瀏覽器的歷史記錄及收藏夾”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





