溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在前幾天寫的一篇文字中,我描述了一次失敗的經歷,對于很在乎過程的我,描述下來就是成功。然而,我不得不回退到DxR,研究一下它的本質而不是其算法思
想。之所以失敗,是因為我的逆反心理在作怪,我真的沒有研究DxR的本質就開始動手,無疑于打一場毫無準備且對對手完全不了解的惡仗,如果不適可而止,其
結果必然和當初死磕Bloom一樣悲慘!
DxR并沒有發明什么新的算法,它之所以高效是因為它分離了路由項中的路由前綴和下一跳這兩個基本元素。在這個的基礎上,它就可以采用三張表來實現自己的既高效又占用空間小的目的。我來總結一下:
這
個前提及其重要!分離前綴和下一跳可以消除數據冗余,構建查找表的目標就從構建單純的查找匹配表轉換成了構建IPv4地址的某一段區間和下一跳表的映射關
系,這就直接導致了區間查找。我們來看一下很類似的Trie樹查找算法,這個算法中路由前綴和下一跳是作為一個“路由項”綁定在一起的,因此查找的過程就
是一個精確匹配+回溯的過程。而DxR算法則消除了回溯的過程。
這個我后面還會說,但記住,這不是核心,這只是一種實現方式。
直接索引表合并了巨大的IPv4地址區間,以便區間表在合并后的少的多的區間中更快速地進行搜索,兩個表的目的都是指向下一跳表的索引。這就建立了區間到下一跳的映射。
如
果到此為止你還不知道DxR算法是什么,那也無所謂,其實它的思想很簡單。路由表的最終結果就是將某個連續地址段對應到某個下一跳(不允許不連續掩碼
了...),因此路由表實際上是將整個IPv4地址空間分割成了若干個區間,每個區間只和一個下一跳關聯。我把那篇關于記錄失敗經歷的文章中一個正確的圖
貼如下:
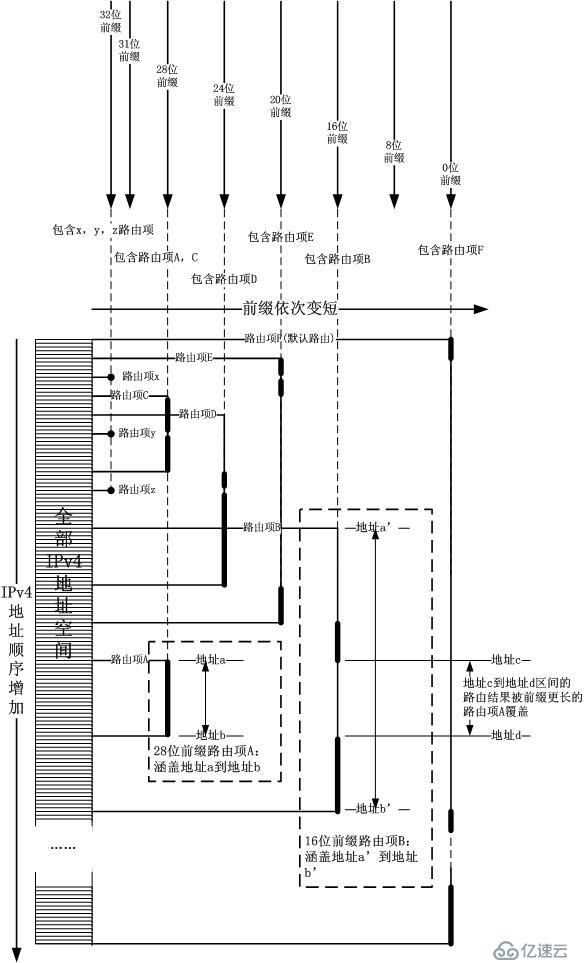
拿
著目標IP地址當索引,向右走,碰到的第一個路由項就是結果。最長掩碼的邏輯完全體現在插入/刪除過程中,即從左到右前綴依次變短,長前綴的路由項會蓋在
短前綴的路由項的前面,這就是核心思想。雖然我現在已經否定了拿IPv4地址直接去做索引,但是核心思想并沒有變,即“拿XX映射到具體的下一跳”,在那
篇失敗記錄中,XX是IPv4地址索引,而在正確的做法中,XX是區間。其實在HiPac防火墻中,也正是使用了這個思想,即區間查找。在HiPac算法
中,區間就是match域,而下一跳對應Rule。
那么,DxR算法就是針對上述圖示的一步步優化。為了更好的說明DxR,我再次給出上圖的變換形式:
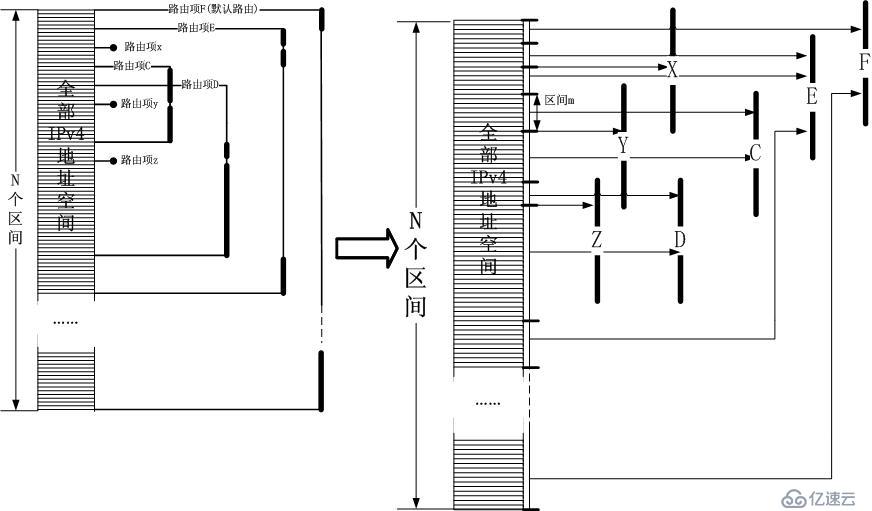
如
果按照上面的圖示,整個IPv4地址空間被分割成了N個區間,路由查找的最終目標是將某個IPv4地址對應到某個區間中!到此為止,其實工作已經完成了。
但是有個前提,那就是你要找出或者自己實現一個高性能的“區間匹配算法”!,即建立一個區間表,內部保存N個區間項,每個區間項對應一個下一跳索引,比如
區間m對應下一跳C,我們的目標是給定一個IPv4地址,判斷它屬于哪個區間。這樣的算法比比皆是,自己實現一個似乎也不難,比如二分法,哈希算法等,所
以本文不關注這些。然而DxR似乎并不滿足這個發現,當然我也不滿足。DxR似乎希望找到一種更加優化的方式實現這個區間匹配。
在給出DxR的框架之前,到此為止,我們發現,DxR實質上就是使用了區間匹配來將一個目標IPv4地址對應到一個區間,然后取出該區間對應的下一跳!
如
果針對每一個到來數據包的目標IPv4地址都要在N個區間中做匹配,似乎不太優雅。如果能將這N個區間劃分為若干個子區間,那么每次匹配時匹配的區間數量
將會大大減少,比如N為100,如果能將整個IPv4地址空間劃分為20個相等的子區間,那么每次匹配的區間數量將會是5個,而不是100個!!但是這里
又有一個前提,那就是劃分子區間的開銷一定要能被由于減少區間數量而帶來的收益抵消掉,并且收益要更大!
這個時候,如果你深入理解二級頁表就好辦了,一個頁目錄項包含1024個頁表項,一個頁表項指向一個4096字節大小的頁面。其中頁目錄就把整個32位虛
擬地址空間分割成了1024個相同大小的區間段,每一個區間段的大小為4096*1024,32位虛擬地址對應32位IPv4地址,事情不就是這樣嗎?不
過,二級頁表或多級頁表解決的是稀疏地址的問題,如果是一級的頁表,那么中間會有很多的“洞”,這是因為進程如何安排虛擬地址在內核和MMU看來是管不了
的。而對于目前我們遇到的問題,采用類似的分級方式是為了劃分子區間從而提高每次區間匹配的效率,注意,這并不是以索引為目的的,我錯誤的將索引作為了目
的而不是手段,于是跌到了萬劫不復的深淵!
但是,對于IPv4地址,并不采用10bit(這是考慮到虛擬地址尋址的特點以及頁面的大小而設定的)這樣的劃分法,而是采用k
bit劃分法,注意,路由表并不存在頁面的概念!如果k等于16,那么就把IPv4地址的高16位就成了一個索引,由于低16位的存在且自由取值,那么每
一個索引表項包括16位涵蓋的IPv4地址數量,即65535個IPv4地址。目前的區間查找表變成了下面的樣子:
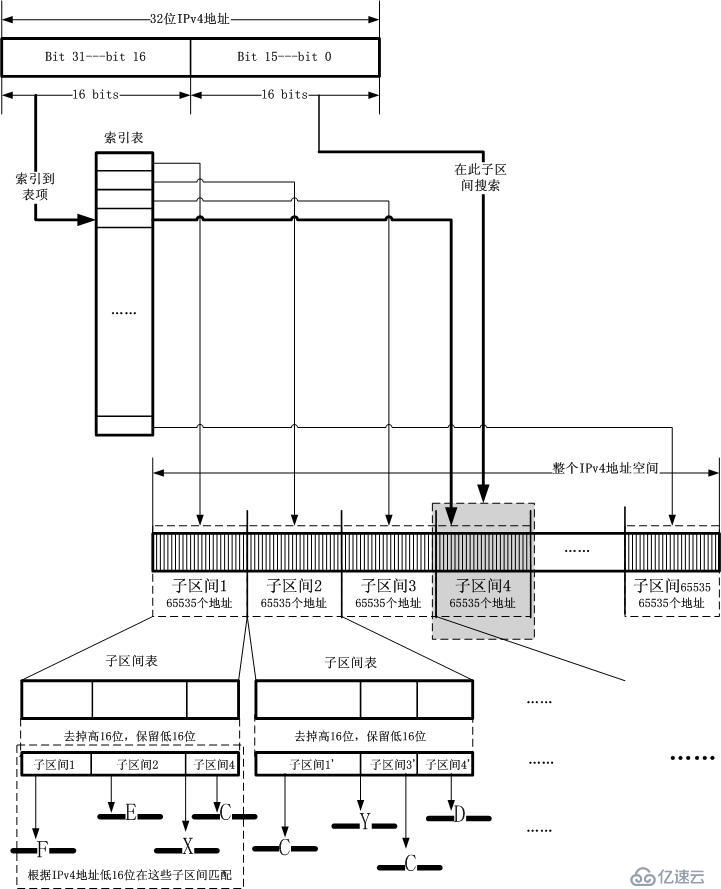
要知道,IPv4地址高16位地址可以一下子索引出子區間,這是一個瞬間的操作!然后下面的問題就是“如何合理布局這些子區間”。
如何將子區間布局成緊湊的結構事關重大,因為緊湊的數據結構意味著可以載入CPU Cache!
以上面最后一幅圖為例子,我們當然希望所有的區間依然連續存放,這樣似乎是緊湊的唯一方式。我們把這個緊湊的合并后的子區間表叫做區間表,如下圖所示:
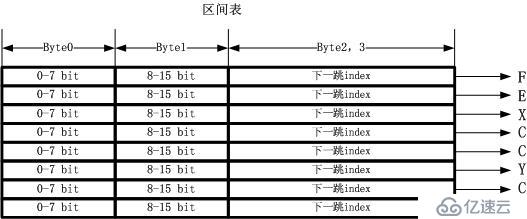
這個時候,IPv4地址的高16位索引表怎么可以區分出自己索引的那囊括65535個地址的區間到底要分割為哪些子區間呢?答案當然是指示一個起始位置和區間數量了。如果我們把所有的圖示展示成一種最終的方式,那么請看下圖:
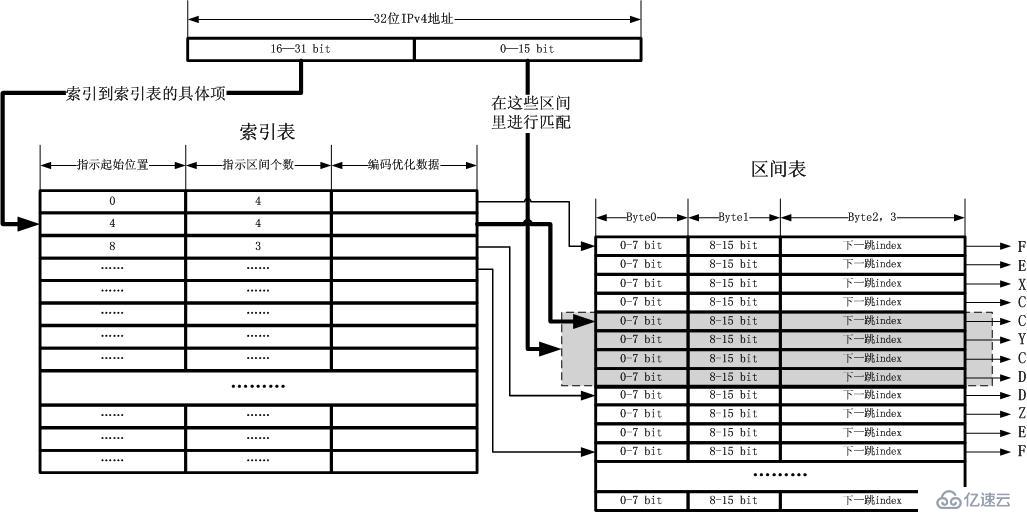
以
上的圖僅僅包含三個表,一個索引表,一個區間表,另外還有一個下一跳表。關于下一跳表圖中沒有畫出,這是因為它的內容不固定,可以僅僅是一個IP地址,也
可以有設備信息以及狀態信息等,也可以是一個鏈表,用于負載均衡,當然,也可以指向別的東西。其中最關鍵的就是前兩個表,即索引表和區間表。這兩張表都可
以放在很緊湊的空間中,占用很小的內存,這兩張表將以最大的能力毛遂自薦以被載入CPU Cache。
有點不好意思。因為上面說著說著就把該說的全部說了。
其實,DxR就是上面的那幅圖所表達的!只是在DxR中:
總
的來講,k值越大,索引表占據的空間越大,如果k值取32,那就不好意思了,索引表項為4G個,區間表不復存在,因為所有的IP地址到下一跳的映射都明細
化了,這就是我自己那次模擬MMU的設計最終的結果,總之,索引表越大,就有越多的IP地址到下一跳的映射明細化,區間表的大小在統計意義上就會越小,這
也是空間換時間的體現...固定索引表大小的時候,區間表的大小是不固定的,取決于你的路由表的路由項布局,因此要想好好使用DxR,沒有一點路由規劃能
力是不行的,比如你要盡量使用諸如匯總之類的技巧,為了使得路由可以匯總,你可能會還需要重新布線,讓可以匯總的路由可以共用同一接口相連的下一跳,這又
涉及到了一些路由分發的能力,特別是你在混用動態路由和靜態路由的時候。總之,IP路由是比較復雜的,涉及到了綜合的能力,算法,IP地址的理解,地址規
劃,路由分發,動態路由,配置命令,甚至綜合布線...
我并沒有說這個表如何增刪改,這個我覺得是可以自己分析的,它主要受到動態路由的影響,畢竟,如果線路狀態不是經常變化,路由表一般也是穩定的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





