溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何從時延毛刺問題定位到Netty的性能統計設計,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
一、背景:
通常情況下,用戶以黑盒的方式使用Netty,通過Netty完成協議消息的讀取和發送,以及編解碼操作,不需要關注Netty的底層實現細節。
在高并發場景下,往往需要統計系統的關鍵性能KPI數據,結合日志、告警等對故障進行定位分析,如果對Netty的底層實現細節不了解,獲取哪些關鍵性能數據,以及數據正確的獲取方式都將成為難點。錯誤或者不準確的數據可能誤導定位思路和方向,導致問題遲遲不能得到正確解決。
二、時延毛刺故障排查的艱辛歷程:
問題現象:某電商生產環境在業務高峰期,偶現服務調用時延突刺問題,時延突然增大的服務沒有固定規律,問題發生的比例雖然很低,但是對客戶的體驗影響很大,需要盡快定位出問題原因并解決。
時延毛刺問題初步分析:
服務調用時延增大,但并不是異常,因此運行日志并不會打印ERROR日志,單靠傳統的日志無法進行有效問題定位。利用分布式消息跟蹤系統,進行分布式環境的故障定界。
通過對服務調用時延進行排序和過濾,找出時延增大的服務調用鏈詳細信息,發現業務服務端處理很快,但是消費者統計數據卻顯示服務端處理非常慢,調用鏈兩端看到的數據不一致,怎么回事?
對調用鏈的詳情進行分析發現,服務端打印的時延是業務服務接口調用的耗時,并沒有包含:
(1)服務端讀取請求消息、對消息做解碼,以及內部消息投遞、在線程池消息隊列排隊等待的時間。
(2)響應消息編碼時間、消息隊列發送排隊時間以及消息寫入到Socket發送緩沖區的時間。
服務調用鏈的工作原理如下:

圖1 服務調用鏈工作原理
將調用鏈中的消息調用過程詳細展開,以服務端讀取請求和發送響應消息為例進行說明,如下圖所示:

圖2 服務端調用鏈詳情
對于服務端的處理耗時,除了業務服務自身調用的耗時之外,還應該包含服務框架的處理時間,具體如下:
(1)請求消息的解碼(反序列化)時間。
(2)請求消息在業務線程池中排隊等待執行時間。
(3)響應消息編碼(序列化)時間。
(4)響應消息ByteBuf在發送隊列的排隊時間。
由于服務端調用鏈只采集了業務服務接口的調用耗時,沒有包含服務框架本身的調度和處理時間,導致無法對故障進行定界:服務端沒有統計服務框架的處理時間,因此不排除問題出在消息發送隊列或者業務線程池隊列積壓而導致時延變大。
服務調用鏈改進:
對服務調用鏈埋點進行優化,具體措施如下:
(1)包含客戶端和服務端消息編碼和解碼的耗時。
(2)包含請求和應答消息在隊列中的排隊時間。
(3)包含應答消息在通信線程發送隊列(數組)中的排隊時間。
同時,為了方便問題定位,增加打印輸出Netty的性能統計日志,主要包括:
(1)當前系統的總鏈路數、以及每個鏈路的狀態。
(2)每條鏈路接收的總字節數、周期T接收的字節數、消息接收吞吐量。
(3)每條鏈路發送的總字節數、周期T發送的字節數、消息發送吞吐量。
對服務調用鏈優化之后,上線運行一段時間,通過分析比對Netty性能統計日志、調用鏈日志,發現雙方的數據并不一致,Netty性能統計日志統計到的數據與前端門戶看到的也不一致,因此懷疑是新增的性能統計功能存在BUG,需要繼續對問題進行定位。
都是同步思維惹的禍:
傳統的同步服務調用,發起服務調用之后,業務線程阻塞,等待響應,接收到響應之后,業務線程繼續執行,對發送的消息進行累加,獲取性能KPI數據。
使用Netty之后,所有的網絡I/O操作都是異步執行的,即調用Channel的write方法,并不代表消息真正發送到TCP緩沖區中,如果在調用write方法之后就對發送的字節數做計數,統計結果就不準確。
對消息發送功能進行code review,發現代碼調用完writeAndFlush方法之后直接對發送的請求消息字節數進行計數,代碼示例如下:
public void channelRead(ChannelHandlerContextctx, Object msg) {
int sendBytes =((ByteBuf)msg).readableBytes();
ctx.writeAndFlush(msg);
totalSendBytes.getAndAdd(sendBytes);
}
調用writeAndFlush并不代表消息已經發送到網絡上,它僅僅是個異步的消息發送操作而已,調用writeAndFlush之后,Netty會執行一系列操作,最終將消息發送到網絡上,相關流程如下所示:
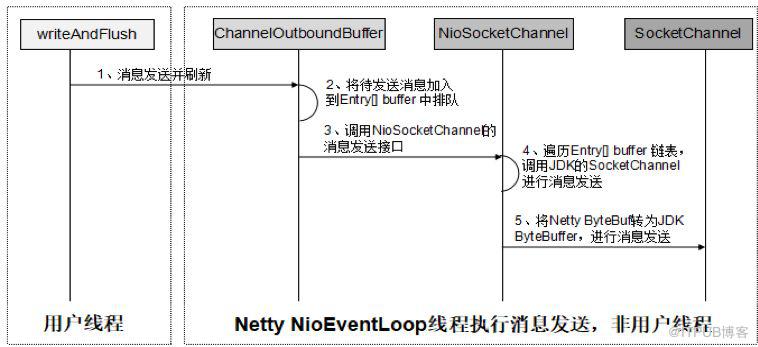
圖3 writeAndFlush處理流程圖
通過對writeAndFlush方法深入分析,我們發現性能統計代碼忽略了如下幾個耗時:
(1)業務ChannelHandler的執行時間。
(2)被異步封裝的WriteTask/WriteAndFlushTask在NioEventLoop任務隊列中的排隊時間。
(3)ByteBuf在ChannelOutboundBuffer隊列中排隊時間。
(4)JDK NIO類庫將ByteBuffer寫入到網絡的時間。
由于性能統計遺漏了上述4個關鍵步驟的執行時間,因此統計出來的發送速率比實際值會更高一些,這將干擾我們的問題定位思路。
正確的消息發送速率性能統計策略:
正確的消息發送速率性能統計方法如下:
(1)調用writeAndFlush方法之后獲取ChannelFuture。
(2)新增消息發送ChannelFutureListener并注冊到ChannelFuture中,監聽消息發送結果,如果消息寫入SocketChannel成功,則Netty會回調ChannelFutureListener的operationComplete方法。
(3)在消息發送ChannelFutureListener的operationComplete方法中進行性能統計。
正確的性能統計代碼示例如下:
public voidchannelRead(ChannelHandlerContext ctx, Object msg) {
int sendBytes =((ByteBuf)msg).readableBytes();
ChannelFuture writeFuture =ctx.write(msg);
writeFuture.addListener((f) ->
{
totalSendBytes.getAndAdd(sendBytes);
});
ctx.flush();
}
對Netty消息發送相關源碼進行分析,當發送的字節數大于0時,進行ByteBuf的清理工作,代碼如下:
protected voiddoWrite(ChannelOutboundBuffer in) throws Exception {
//代碼省略...
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
adjustMaxBytesPerGatheringWrite(attemptedBytes, localWrittenBytes,maxBytesPerGatheringWrite);
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
//代碼省略...
}
接著分析ChannelOutboundBuffer的removeBytes(long writtenBytes)方法,將發送的字節數與當前ByteBuf可讀的字節數進行對比,判斷當前的ByteBuf是否完成發送,如果完成則調用remove()清理它,否則只更新下發送進度,相關代碼如下:
protected voiddoWrite(ChannelOutboundBuffer in) throws Exception {
//代碼省略...
if (readableBytes <=writtenBytes) {
if (writtenBytes != 0) {
progress(readableBytes);
writtenBytes -=readableBytes;
}
remove();
} else {
if (writtenBytes != 0) {
buf.readerIndex(readerIndex+ (int) writtenBytes);
progress(writtenBytes);
}
break;
}
//代碼省略...
}
當調用remove()方法時,最終會調用消息發送ChannelPromise的trySuccess方法,通知監聽Listener消息已經完成發送,相關代碼如下所示:
public booleantrySuccess(V result) {
//代碼省略...
if (setSuccess0(result)) {
notifyListeners();
return true;
}
return false;
}
//代碼省略...
}
經過以上分析可以看出,調用write/writeAndFlush方法本身并不代表消息已經發送完成,只有監聽write/writeAndFlush的操作結果,在異步回調監聽中計數,結果才更精確。
需要注意的是,異步回調通知由Netty的NioEventLoop線程執行,即便異步回調代碼寫在業務線程中,也是由Netty的I/O線程來執行累加計數的,因此這塊兒需要考慮多線程并發安全問題,調用堆棧示例如下:
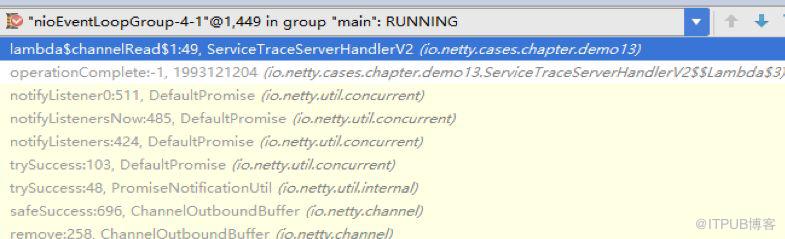
圖4 消息發送結果異步回調通知執行線程
如果消息報文比較大,或者一次批量發送的消息比較多,可能會出現“寫半包”問題,即一個消息無法在一次write操作中全部完成發送,可能只發送了一半,針對此類場景,可以創建GenericProgressiveFutureListener用于實時監聽消息發送進度,做更精準的統計,相關代碼如下所示:
privatestatic void notifyProgressiveListeners0(
ProgressiveFuture<?> future,GenericProgressiveFutureListener<?>[] listeners, long progress,long total) {
for(GenericProgressiveFutureListener<?> l: listeners) {
if (l == null) {
break;
}
notifyProgressiveListener0(future,l, progress, total);
}
}
問題定位出來之后,按照正確的做法對Netty性能統計代碼進行了修正,上線之后,結合調用鏈日志,很快定位出了業務高峰期偶現的部分服務時延毛刺較大問題,優化業務線程池參數配置之后問題得到解決。
常見的消息發送性能統計誤區:
在實際業務中比較常見的性能統計誤區如下:
(1)調用write/ writeAndFlush方法之后就開始統計發送速率。
(2)消息編碼時進行性能統計:編碼之后,獲取out可讀的字節數,然后做累加。編碼完成并不代表消息被寫入到SocketChannel中,因此性能統計也不準確。
Netty關鍵性能指標采集:
除了消息發送速率,還有其它一些重要的指標需要采集和監控,無論是在調用鏈詳情中展示,還是統一由運維采集、匯總和展示,這些性能指標對于故障的定界和定位幫助都很大。
Netty I/O線程池性能指標:
Netty I/O線程池除了負責網絡I/O消息的讀寫,還需要同時處理普通任務和定時任務,因此消息隊列積壓的任務個數是衡量Netty I/O線程池工作負載的重要指標。由于Netty NIO線程池采用的是一個線程池/組包含多個單線程線程池的機制,因此不需要像原生的JDK線程池那樣統計工作線程數、最大線程數等。相關代碼如下所示:
publicvoid channelActive(ChannelHandlerContext ctx) throws Exception {
kpiExecutorService.scheduleAtFixedRate(()->
{
Iterator<EventExecutor>executorGroups = ctx.executor().parent().iterator();
while (executorGroups.hasNext())
{
SingleThreadEventExecutorexecutor = (SingleThreadEventExecutor)executorGroups.next();
int size = executor.pendingTasks();
if (executor == ctx.executor())
System.out.println(ctx.channel() + "--> " + executor +" pending size in queue is : --> " + size);
else
System.out.println(executor+ " pending size in queue is : --> " + size);
}
},0,1000, TimeUnit.MILLISECONDS);
}
}
運行結果如下所示:
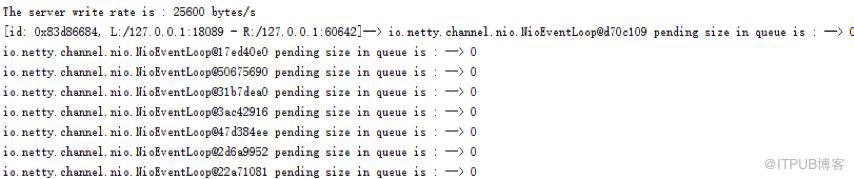
圖5 Netty I/O線程池性能統計KPI數據
Netty發送隊列積壓消息數:
Netty消息發送隊列積壓數可以反映網絡速度、通信對端的讀取速度、以及自身的發送速度等,因此對于服務調用時延的精細化分析對于問題定位非常有幫助,它的采集方式代碼示例如下:
publicvoid channelActive(ChannelHandlerContext ctx) throws Exception {
writeQueKpiExecutorService.scheduleAtFixedRate(()->
{
long pendingSize =((NioSocketChannel)ctx.channel()).unsafe().outboundBuffer().totalPendingWriteBytes();
System.out.println(ctx.channel() +"--> " + " ChannelOutboundBuffer's totalPendingWriteBytes is: "
+ pendingSize + "bytes");
},0,1000, TimeUnit.MILLISECONDS);
}
執行結果如下:

圖6 Netty Channel對應的消息發送隊列性能KPI數據
由于totalPendingSize是volatile的,因此統計線程即便不是Netty的I/O線程,也能夠正確的讀取其最新值。
Netty消息讀取速率性能統計:
針對某個Channel的消息讀取速率性能統計,可以在解碼ChannelHandler之前添加一個性能統計ChannelHandler,用來對讀取速率進行計數,相關代碼示例如下(ServiceTraceProfileServerHandler類):
public voidchannelActive(ChannelHandlerContext ctx) throws Exception {
kpiExecutorService.scheduleAtFixedRate(()->
{
int readRates =totalReadBytes.getAndSet(0);
System.out.println(ctx.channel() +"--> read rates " + readRates);
},0,1000, TimeUnit.MILLISECONDS);
ctx.fireChannelActive();
}
public void channelRead(ChannelHandlerContextctx, Object msg) {
int readableBytes =((ByteBuf)msg).readableBytes();
totalReadBytes.getAndAdd(readableBytes);
ctx.fireChannelRead(msg);
}
運行結果如下所示:

圖7 NettyChannel 消息讀取速率性能統計
以上是“如何從時延毛刺問題定位到Netty的性能統計設計”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





