溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Elasticsearch集群搭建
這么長時間了ELK我們聽得耳朵都起繭子了。但ELK我們到底掌握的了多少呢,有或者說作為運維人員你部署的ELK是否可以到線上應用呢?下面我跟大家說說我個人的此集群上線思路與線上部署和應用的方法。此文比較長,同時也會分段跟新,防止大家只看做法不看思路。下面我要跟大家說:Welcome to my ELK world!我講分為兩條路走,第一條路技術點補充,第二條路生產環境線上操作。以后文章都會先更新技術點再整理操作。
ELK其實看起來簡單但是他是三個技術的結合,分別是:elasticsearch,logstash,kibana
其官網地址為:https://www.elastic.co/
我們學習的同時可以參考官網的權威指南。
接下來我們開始分模塊來做ELK。
一、 Elasticsearch
Elasticsearch 是一個分布式、可擴展、實時的搜索與數據分析引擎。 它能從項目一開始就賦予你的數據以搜索、分析和探索的能力,這是通常沒有預料到的。 它存在還因為原始數據如果只是躺在磁盤里面根本就毫無用處。
哦,讀到這里你了解到Elasticsearch,分布式,高性能,高可用,可伸縮的搜索和分析系統
那下面有幾個為題:
1、什么是搜索?
2、如果用數據庫做搜索會怎么樣?
3、什么是全文檢索、倒排索引和Lucene?
4、什么是Elasticsearch?
能不看下面內容回答上來的請讀下一篇內容,因為你已有基礎DBA經驗。
那我來給大家回答上邊的問題,
1.什么時索引?
百度:我們比如說想找尋任何的信息的時候,就會上百度去搜索一下,比如說找一部自己喜歡的電影,或者說找一本喜歡的書,或者找一條感興趣的新聞(提到搜索的第一印象)
百度 != 搜索,這是不對的
垂直搜索(站內搜索)
互聯網的搜索:電商網站,招聘網站,新聞網站,各種app
IT系統的搜索:OA軟件,辦公自動化軟件,會議管理,日程管理,項目管理,員工管理,搜索“張三”,“張三兒”,“張小三”;有個電商網站,賣家,后臺管理系統,搜索“牙膏”,訂單,“牙膏相關的訂單”
搜索,就是在任何場景下,找尋你想要的信息,這個時候,會輸入一段你要搜索的關鍵字,然后就期望找到這個關鍵字相關的有些信息。
(1)比方說,每條記錄的指定字段的文本,可能會很長,比如說“商品描述”字段的長度,有長達數千個,甚至數萬個字符,這個時候,每次都要對每條記錄的所有文本進行掃描,懶判斷說,你包不包含我指定的這個關鍵詞(比如說“牙膏”)
(2)還不能將搜索詞拆分開來,盡可能去搜索更多的符合你的期望的結果,比如輸入“生化機”,就搜索不出來“生化危機”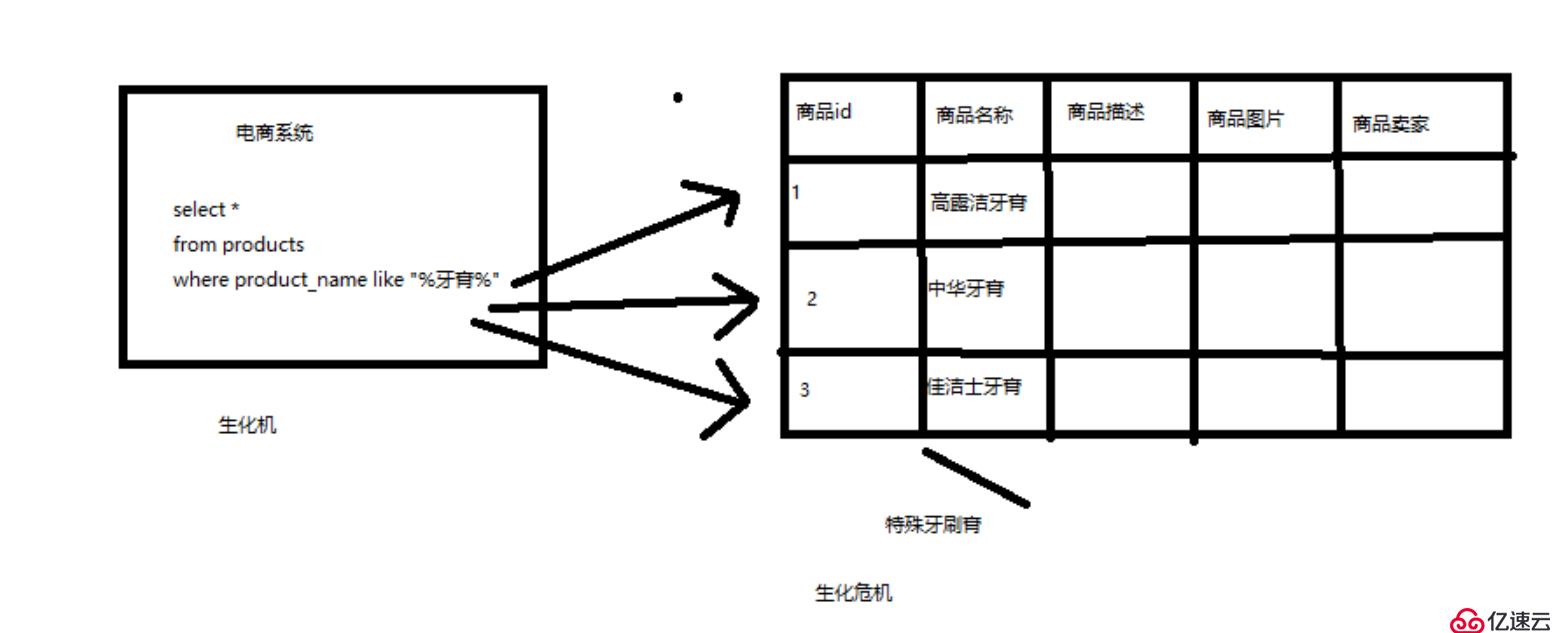
用數據庫來實現搜索,是不太靠譜的。通常來說,性能會很差。
3.什么是全文檢索和Lucene?
(1)全文檢索,倒排索引
(2)lucene,就是一個jar包,里面包含了封裝好的各種建立倒排索引,以及進行搜索的代碼,包括各種算法。我們就用java開發的時候,引入lucene jar,然后基于lucene的api進行去進行開發就可以了。用lucene,我們就可以去將已有的數據建立索引,lucene會在本地磁盤上面,給我們組織索引的數據結構。另外的話,我們也可以用lucene提供的一些功能和api來針對磁盤上額。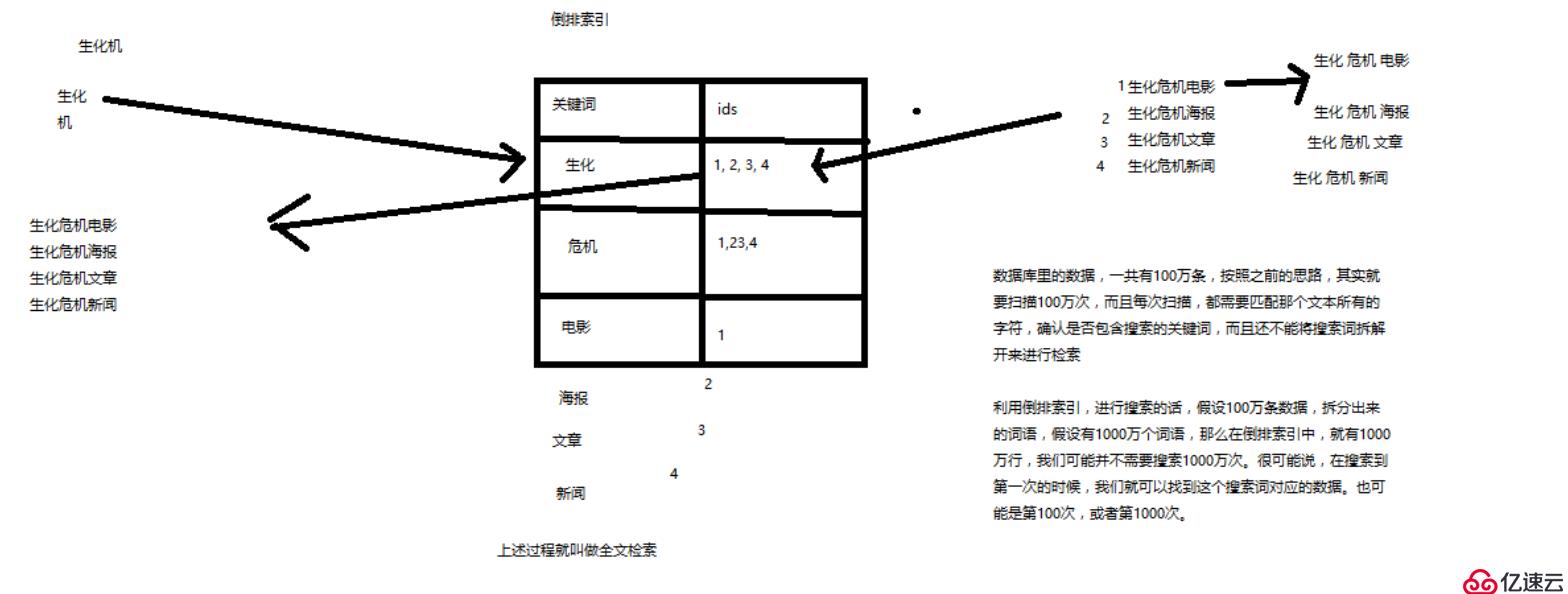
4.什么是Elasticsearch?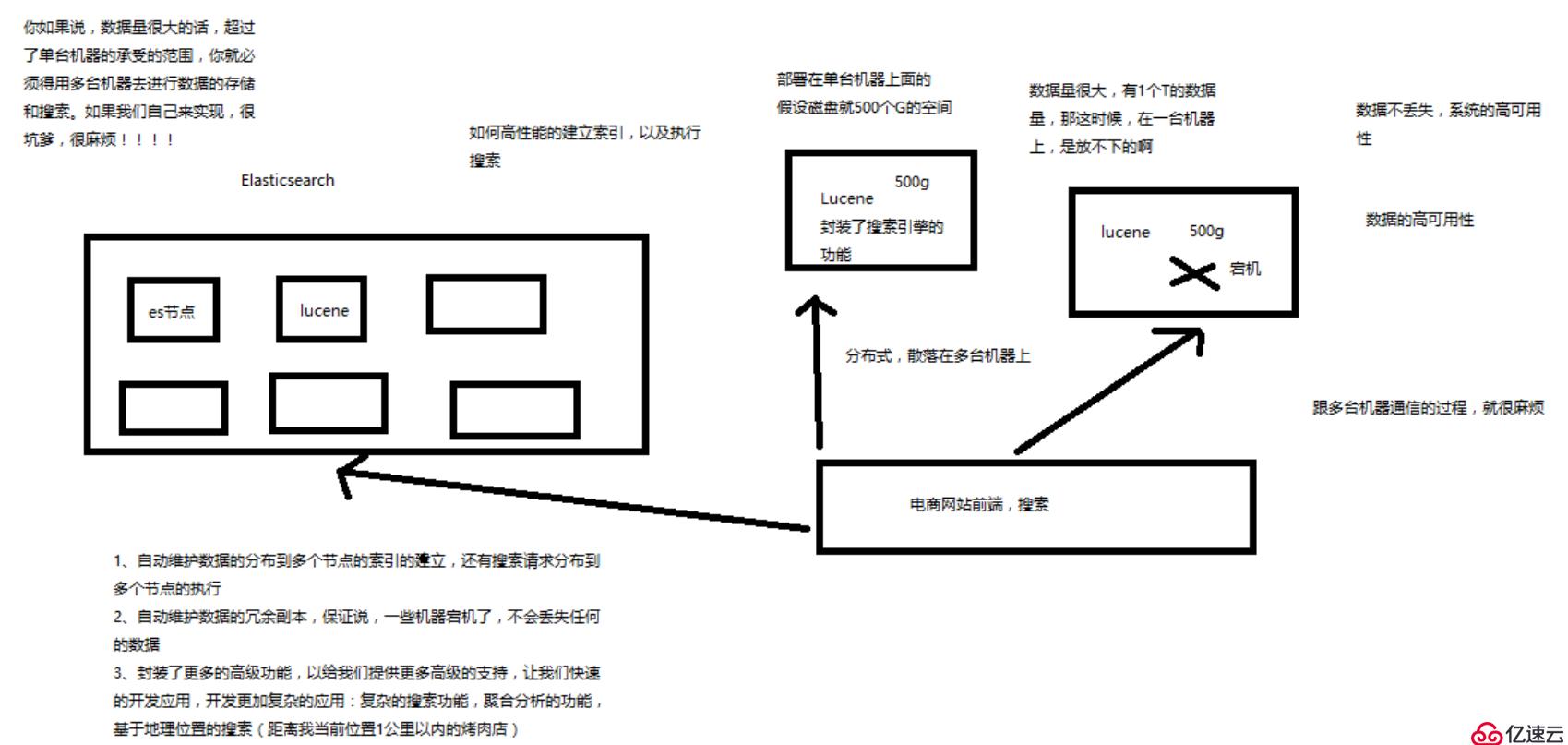
接下來我們再看
1、Elasticsearch的功能,干什么的
2、Elasticsearch的適用場景,能在什么地方發揮作用
3、Elasticsearch的特點,跟其他類似的東西不同的地方在哪里
1、Elasticsearch的功能
1.Elasticsearch的功能,干什么的
(1)分布式的搜索引擎和數據分析引擎
搜索:百度,網站的站內搜索,IT系統的檢索
數據分析:電商網站,最近7天牙膏這種商品銷量排名前10的商家有哪些;新聞網站,最近1個月訪問量排名前3的新聞版塊是哪些
分布式,搜索,數據分析
(2)全文檢索,結構化檢索,數據分析
全文檢索:我想搜索商品名稱包含牙膏的商品,select from products where product_name like "%牙膏%"
結構化檢索:我想搜索商品分類為日化用品的商品都有哪些,select from products where category_id='日化用品'
部分匹配、自動完成、搜索糾錯、搜索推薦
數據分析:我們分析每一個商品分類下有多少個商品,select category_id,count(*) from products group by category_id
(3)對海量數據進行近實時的處理
分布式:ES自動可以將海量數據分散到多臺服務器上去存儲和檢索
海聯數據的處理:分布式以后,就可以采用大量的服務器去存儲和檢索數據,自然而然就可以實現海量數據的處理了
近實時:檢索個數據要花費1小時(這就不要近實時,離線批處理,batch-processing);在秒級別對數據進行搜索和分析
跟分布式/海量數據相反的:lucene,單機應用,只能在單臺服務器上使用,最多只能處理單臺服務器可以處理的數據量
(1)維基百科,類似百度百科,牙膏,牙膏的維基百科,全文檢索,高亮,搜索推薦
(2)The Guardian(國外新聞網站),類似搜狐新聞,用戶行為日志(點擊,瀏覽,收藏,評論)+社交網絡數據(對某某新聞的相關看法),數據分析,給到每篇新聞文章的作者,讓他知道他的文章的公眾反饋(好,壞,熱門,垃圾,鄙視,崇拜)
(3)Stack Overflow(國外的程序異常討論論壇),IT問題,程序的報錯,提交上去,有人會跟你討論和回答,全文檢索,搜索相關問題和答案,程序報錯了,就會將報錯信息粘貼到里面去,搜索有沒有對應的答案
(4)GitHub(開源代碼管理),搜索上千億行代碼
(5)電商網站,檢索商品
(6)日志數據分析,logstash采集日志,ES進行復雜的數據分析(ELK技術,elasticsearch+logstash+kibana)
(7)商品價格監控網站,用戶設定某商品的價格閾值,當低于該閾值的時候,發送通知消息給用戶,比如說訂閱牙膏的監控,如果高露潔牙膏的家庭套裝低于50塊錢,就通知我,我就去買
(8)BI系統,商業智能,Business Intelligence。比如說有個大型商場集團,BI,分析一下某某區域最近3年的用戶消費金額的趨勢以及用戶群體的組成構成,產出相關的數張報表,**區,最近3年,每年消費金額呈現100%的增長,而且用戶群體85%是高級白領,開一個新商場。ES執行數據分析和挖掘,Kibana進行數據可視化
國內
(9)國內:站內搜索(電商,招聘,門戶,等等),IT系統搜索(OA,CRM,ERP,等等),數據分析(ES熱門的一個使用場景)
1、lucene和elasticsearch的前世今生
2、elasticsearch的核心概念
3、elasticsearch核心概念 vs. 數據庫核心概念
1.lucene和elasticsearch的前世今生
lucene,最先進、功能最強大的搜索庫,直接基于lucene開發,非常復雜,api復雜(實現一些簡單的功能,寫大量的java代碼),需要深入理解原理(各種索引結構)
elasticsearch,基于lucene,隱藏復雜性,提供簡單易用的restful api接口、java api接口(還有其他語言的api接口)
(1)分布式的文檔存儲引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB級數據
開箱即用,優秀的默認參數,不需要任何額外設置,完全開源
關于elasticsearch的一個傳說,有一個程序員失業了,陪著自己老婆去英國倫敦學習廚師課程。程序員在失業期間想給老婆寫一個菜譜搜索引擎,覺得lucene實在太復雜了,就開發了一個封裝了lucene的開源項目,compass。后來程序員找到了工作,是做分布式的高性能項目的,覺得compass不夠,就寫了elasticsearch,讓lucene變成分布式的系統。
(2)Cluster:集群,包含多個節點,每個節點屬于哪個集群是通過一個配置(集群名稱,默認是elasticsearch)來決定的,對于中小型應用來說,剛開始一個集群就一個節點很正常
(3)Node:節點,集群中的一個節點,節點也有一個名稱(默認是隨機分配的),節點名稱很重要(在執行運維管理操作的時候),默認節點會去加入一個名稱為“elasticsearch”的集群,如果直接啟動一堆節點,那么它們會自動組成一個elasticsearch集群,當然一個節點也可以組成一個elasticsearch集群
(4)Document&field:文檔,es中的最小數據單元,一個document可以是一條客戶數據,一條商品分類數據,一條訂單數據,通常用JSON數據結構表示,每個index下的type中,都可以去存儲多個document。一個document里面有多個field,每個field就是一個數據字段。
product document
{
"product_id": "1",
"product_name": "高露潔牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:索引,包含一堆有相似結構的文檔數據,比如可以有一個客戶索引,商品分類索引,訂單索引,索引有一個名稱。一個index包含很多document,一個index就代表了一類類似的或者相同的document。比如說建立一個product index,商品索引,里面可能就存放了所有的商品數據,所有的商品document。
(6)Type:類型,每個索引里都可以有一個或多個type,type是index中的一個邏輯數據分類,一個type下的document,都有相同的field,比如博客系統,有一個索引,可以定義用戶數據type,博客數據type,評論數據type。
商品index,里面存放了所有的商品數據,商品document
但是商品分很多種類,每個種類的document的field可能不太一樣,比如說電器商品,可能還包含一些諸如售后時間范圍這樣的特殊field;生鮮商品,還包含一些諸如生鮮保質期之類的特殊field
type,日化商品type,電器商品type,生鮮商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
電器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鮮商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一個type里面,都會包含一堆document
{
"product_id": "2",
"product_name": "長虹電視機",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "電器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基圍蝦",
"product_desc": "純天然,冰島產",
"category_id": "4",
"category_name": "生鮮",
"eat_period": "7天"
}
(7)shard:單臺機器無法存儲大量數據,es可以將一個索引中的數據切分為多個shard,分布在多臺服務器上存儲。有了shard就可以橫向擴展,存儲更多數據,讓搜索和分析等操作分布到多臺服務器上去執行,提升吞吐量和性能。每個shard都是一個lucene index。
(8)replica:任何一個服務器隨時可能故障或宕機,此時shard可能就會丟失,因此可以為每個shard創建多個replica副本。replica可以在shard故障時提供備用服務,保證數據不丟失,多個replica還可以提升搜索操作的吞吐量和性能。primary shard(建立索引時一次設置,不能修改,默認5個),replica shard(隨時修改數量,默認1個),默認每個索引10個shard,5個primary shard,5個replica shard,最小的高可用配置,是2臺服務器。
3.elasticsearch核心概念 vs. 數據庫核心概念
Elasticsearch 數據庫
Document 行
Type 表
Index 庫
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





