溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下在Python中如何通過機器學習實現人體姿勢估計,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
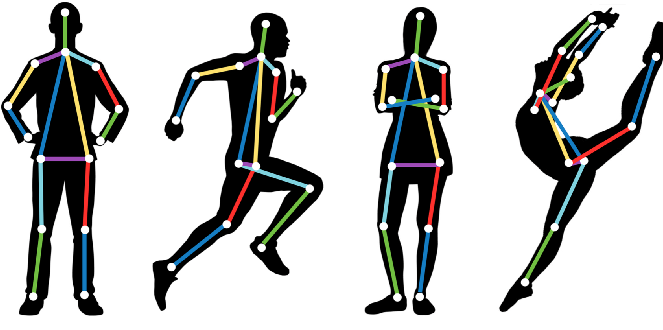
姿態估計是一種跟蹤人或物體運動的計算機視覺技術。這通常通過查找給定對象的關鍵點位置來執行。基于這些關鍵點,我們可以比較各種動作和姿勢并得出見解。姿態估計在增強現實、動畫、游戲和機器人領域得到了積極的應用。
目前有幾種模型可以執行姿態估計。下面給出了一些姿勢估計的方法:
1.Open pose
2.Pose net
3.Blaze pose
4.Deep Pose
5.Dense pose
6.Deep cut
選擇任何一種模型而不是另一種可能完全取決于應用程序。此外,運行時間、模型大小和易于實現等因素也可能是選擇特定模型的各種原因。因此,最好從一開始就了解你的要求并相應地選擇模型。
在本文中,我們將使用 Blaze pose檢測人體姿勢并提取關鍵點。該模型可以通過一個非常有用的庫輕松實現,即眾所周知的Media Pipe。
Media Pipe——Media Pipe是一個開源的跨平臺框架,用于構建多模型機器學習管道。它可用于實現人臉檢測、多手跟蹤、頭發分割、對象檢測和跟蹤等前沿模型。
Blaze Pose Detector ——大部分姿態檢測依賴于由 17 個關鍵點組成的 COCO 拓撲結構,而Blaze姿態檢測器預測 33 個人體關鍵點,包括軀干、手臂、腿部和面部。包含更多關鍵點對于特定領域姿勢估計模型的成功應用是必要的,例如手、臉和腳。每個關鍵點都使用三個自由度以及可見性分數進行預測。Blaze Pose是亞毫秒模型,可用于實時應用,其精度優于大多數現有模型。該模型有兩個版本:Blazepose lite 和 Blazepose full,以提供速度和準確性之間的平衡。
Blaze 姿勢提供多種應用程序,包括健身和瑜伽追蹤器。這些應用程序可以通過使用一個額外的分類器來實現,比如我們將在本文中構建的分類器。
你可以在此處了解有關Blaze Pose Detector的更多信息: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html
姿勢估計可以在 2D 或 3D 中完成。2D 姿態估計通過像素值預測圖像中的關鍵點。而3D姿態估計是指預測關鍵點的三維空間排列作為其輸出。
我們在上一節中了解到,人體姿勢的關鍵點可以用來比較不同的姿勢。在本節中,我們將使用Media Pipe庫本身來準備數據集。我們將拍攝兩個瑜伽姿勢的圖像,從中提取關鍵點并將它們存儲在一個 CSV 文件中。
你可以通過此鏈接從 Kaggle 下載數據集
該數據集包含 5 個瑜伽姿勢,但是,在本文中,我只采用了兩個姿勢。如果需要,你可以使用所有這些,程序將保持不變。
import mediapipe as mp import cv2 import time import numpy as np import pandas as pd import os mpPose = mp.solutions.pose pose = mpPose.Pose() mpDraw = mp.solutions.drawing_utils # For drawing keypoints points = mpPose.PoseLandmark # Landmarks path = "DATASET/TRAIN/plank" # enter dataset path data = [] for p in points: x = str(p)[13:] data.append(x + "_x") data.append(x + "_y") data.append(x + "_z") data.append(x + "_vis") data = pd.DataFrame(columns = data) # Empty dataset
在上面的代碼片段中,我們首先導入了有助于創建數據集的必要庫。然后在接下來的四行中,我們將導入提取關鍵點所需的模塊及其繪制工具。
接下來,我們創建一個空的 Pandas 數據框并輸入列。這里的列包括由Blaze姿態檢測器檢測到的 33 個關鍵點。每個關鍵點包含四個屬性,即關鍵點的 x 和 y 坐標(從 0 到 1 歸一化),z 坐標表示以臀部為原點且與 x 的比例相同的地標深度,最后是可見度分數。可見性分數表示地標在圖像中可見或不可見的概率。
count = 0
for img in os.listdir(path):
temp = []
img = cv2.imread(path + "/" + img)
imageWidth, imageHeight = img.shape[:2]
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blackie = np.zeros(img.shape) # Blank image
results = pose.process(imgRGB)
if results.pose_landmarks:
# mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS) #draw landmarks on image
mpDraw.draw_landmarks(blackie, results.pose_landmarks, mpPose.POSE_CONNECTIONS) # draw landmarks on blackie
landmarks = results.pose_landmarks.landmark
for i,j in zip(points,landmarks):
temp = temp + [j.x, j.y, j.z, j.visibility]
data.loc[count] = temp
count +=1
cv2.imshow("Image", img)
cv2.imshow("blackie",blackie)
cv2.waitKey(100)
data.to_csv("dataset3.csv") # save the data as a csv file在上面的代碼中,我們單獨遍歷姿勢圖像,使用Blaze姿勢模型提取關鍵點并將它們存儲在臨時數組“temp”中。
迭代完成后,我們將這個臨時數組作為新記錄添加到我們的數據集中。你還可以使用Media Pipe本身中的繪圖實用程序來查看這些地標。
在上面的代碼中,我在圖像以及空白圖像“blackie”上繪制了這些地標,以僅關注Blaze姿勢模型的結果。空白圖像“blackie”的形狀與給定圖像的形狀相同。
應該注意的一件事是,Blaze姿態模型采用 RGB 圖像而不是 BGR(由 OpenCV 讀取)。
獲得所有圖像的關鍵點后,我們必須添加一個目標值,作為機器學習模型的標簽。你可以將第一個姿勢的目標值設為 0,將另一個設為 1。之后,我們可以將這些數據保存到 CSV 文件中,我們將在后續步驟中使用該文件創建機器學習模型。

你可以從上圖中觀察數據集的外觀。
現在我們已經創建了我們的數據集,我們只需要選擇一種機器學習算法來對姿勢進行分類。在這一步中,我們將拍攝一張圖像,運行 blaze 姿勢模型(我們之前用于創建數據集)以獲取該圖像中人物的關鍵點,然后在該測試用例上運行我們的模型。
該模型有望以高置信度給出正確的結果。在本文中,我將使用 sklearn 庫中的 SVC(支持向量分類器)來執行分類任務。
from sklearn.svm import SVC
data = pd.read_csv("dataset3.csv")
X,Y = data.iloc[:,:132],data['target']
model = SVC(kernel = 'poly')
model.fit(X,Y)
mpPose = mp.solutions.pose
pose = mpPose.Pose()
mpDraw = mp.solutions.drawing_utils
path = "enter image path"
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(imgRGB)
if results.pose_landmarks:
landmarks = results.pose_landmarks.landmark
for j in landmarks:
temp = temp + [j.x, j.y, j.z, j.visibility]
y = model.predict([temp])
if y == 0:
asan = "plank"
else:
asan = "goddess"
print(asan)
cv2.putText(img, asan, (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),3)
cv2.imshow("image",img)在上面的代碼行中,我們首先從 sklearn 庫中導入了 SVC(支持向量分類器)。我們已經用目標變量作為 Y 標簽訓練了我們之前在 SVC 上構建的數據集。
然后我們讀取輸入圖像并提取關鍵點,就像我們在創建數據集時所做的那樣。
最后,我們輸入臨時變量并使用模型進行預測。現在可以使用簡單的 if-else 條件檢測姿勢。
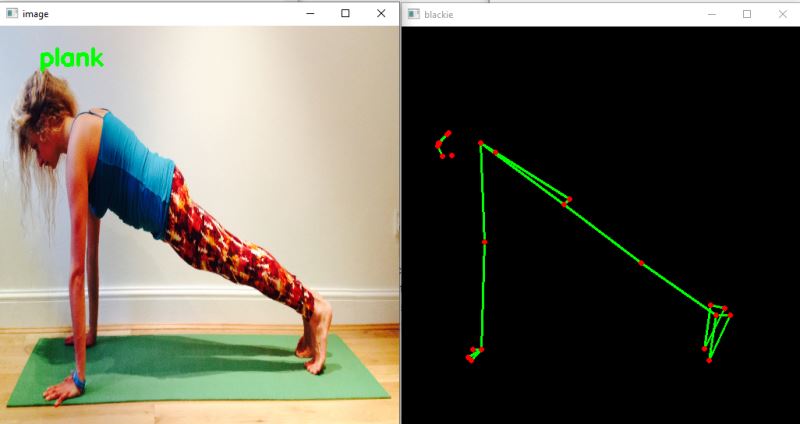
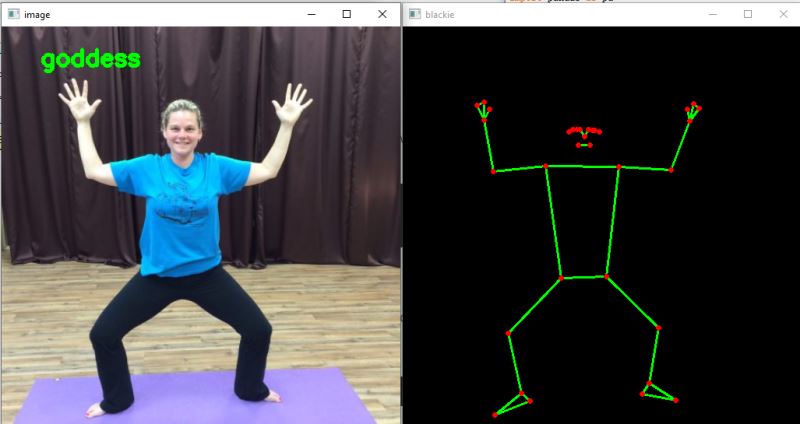
從上面的圖像中,你可以觀察到模型已經正確地對姿勢進行了分類。你還可以在右側看到Blaze姿勢模型檢測到的姿勢。
在第一張圖片中,如果你仔細觀察,一些關鍵點是不可見的,但姿勢分類是正確的。由于Blaze姿態模型給出的關鍵點屬性的可見性,這是可能的。
以上是“在Python中如何通過機器學習實現人體姿勢估計”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





