溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
基于TensorFlow2.x的實時多人二維姿勢估計是怎樣的,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
正如Zhe Cao在其2017年的論文中所述,實時多人二維姿勢估計對于機器理解圖像和視頻中的人至關重要。

顧名思義,它是一種用來估計一個人身體位置的技術,比如站著、坐著或躺下。獲得這一估計值的一種方法是找到18個“身體關節”或人工智能領域中命名的“關鍵點(Key Points)”。下面的圖像顯示了我們的目標,即在圖像中找到這些點:
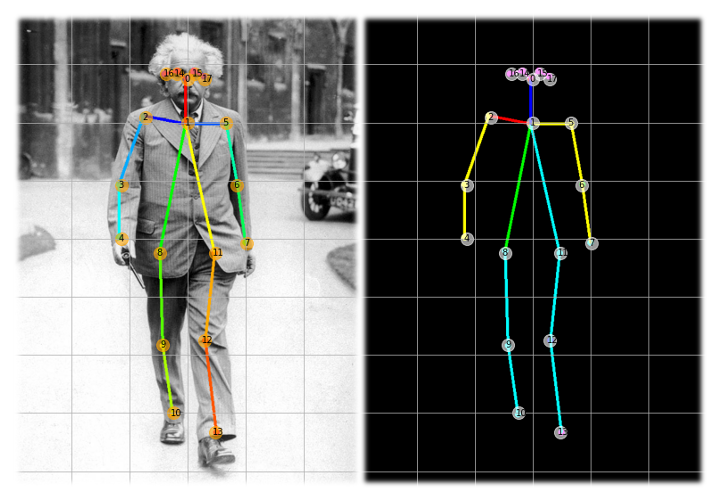
關鍵點從0點(上頸部)向下延伸到身體關節,然后回到頭部,最后是第17點(右耳)。
使用人工智能方法出現的第一個有意義的工作是DeepPose,2014年由谷歌的Toshev和Zegedy撰寫的論文。提出了一種基于深度神經網絡(DNNs)的人體姿勢估計方法,該方法將人體姿勢估計歸結為一個基于DNN的人體關節回歸問題。
該模型由一個AlexNet后端(7層)和一個額外的目標層,輸出2k個關節坐標。這種方法的一個重要問題是,首先,模型應用程序必須檢測到一個人(經典的對象檢測)。因此,在圖像上發現的每個人體必須分開處理,這大大增加了處理圖像的時間。
這種方法被稱為“自上而下”,因為首先要找到身體,然后從中找到與其相關聯的關節。
姿勢估計有幾個問題,如:
每個圖像可能包含未知數量的人,這些人可以出現在任何位置或比例。
人與人之間的相互作用會導致復雜的空間干擾,這是由于接觸或肢體關節連接,使得關節的關聯變得困難。
運行時的復雜性往往隨著圖像中的人數而增加,這使得實時性能成為一個挑戰。
為了解決這些問題,一種更令人興奮的方法是OpenPose,這是2016年由卡內基梅隆大學機器人研究所的ZheCao和他的同事們引入的。
OpenPose提出的方法使用一個非參數表示,稱為部分親和力場(PAFs)來“連接”圖像上的每個身體關節,將它們與個人聯系起來。
換句話說,OpenPose與DeepPose相反,首先在圖像上找到所有關節,然后“向上”搜索最有可能包含該關節的身體,而不使用檢測人的檢測器(“自下而上”方法)。OpenPose可以找到圖像上的關鍵點,而不管圖像上有多少人。下面的圖片是從ILSVRC和COCO研討會2016上的OpenPose演示中檢索到的,它讓我們了解了這個過程。

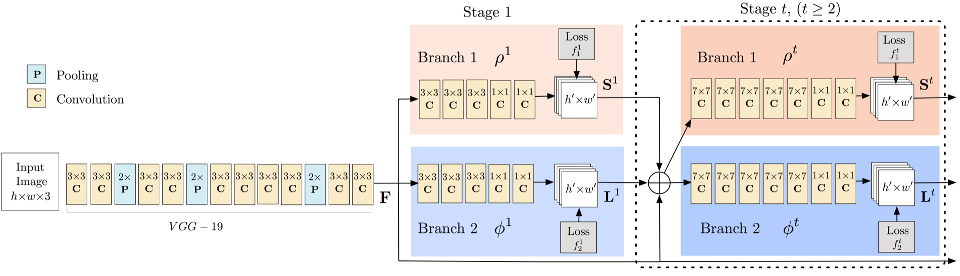
下圖顯示了用于訓練的兩個多階段CNN模型的結構。首先,前饋網絡同時預測一組人體部位位置的二維置信度映射(關鍵點標注來自(dataset/COCO/annotations/)和一組二維的部分親和力場(L)。
在每一個階段之后,兩個分支的預測以及圖像特征被連接到下一個階段。最后,利用貪婪的推理對置信圖和相似域進行解析,輸出圖像中所有人的二維關鍵點。
在項目執行過程中,我們將回到其中一些概念進行澄清。但是,強烈建議你遵循2016年的OpenPose ILSVRC和COCO研討會演示(http://image-net.org/challenges/talks/2016/Multi-person%20pose%20estimation-CMU.pdf)和CVPR 2017的視頻錄制(https://www.youtube.com/watch?v=OgQLDEAjAZ8&list=PLvsYSxrlO0Cl4J_fgMhj2ElVmGR5UWKpB),以便更好地理解。
最初的OpenPose是使用基于模型的VGG預訓練網絡和Caffe框架開發的。但是,我們將遵循Ildoo Kim 的TensorFlow實現,詳細介紹了他的tf-pose-estimation。
Github鏈接:https://github.com/ildoonet/tf-pose-estimation
tf-pose-estimation是一種“Openpose”算法,它是利用Tensorflow實現的。它還提供了幾個變體,這些變體對網絡結構進行了一些更改,以便在CPU或低功耗嵌入式設備上進行實時處理。
tf-pose-estimation的GitHub頁面展示了幾種不同模型的實驗,如:
cmu:原論文中描述的基于模型的VGG預訓練網絡的權值是Caffe格式,將其轉換并用于TensorFlow。
dsconv:除了mobilenet的深度可分離卷積之外,與cmu版本的架構相同。
mobilenet:基于mobilenet V1論文,使用12個卷積層作為特征提取層。
mobilenet v2:與mobilenet相似,但使用了它的改進版本。
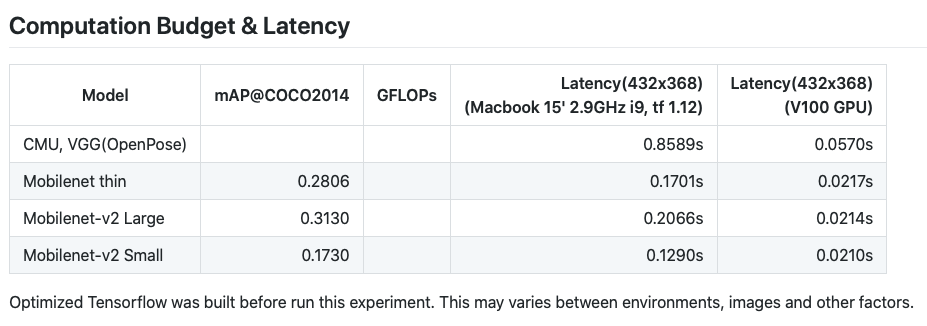
本文的研究是在mobilenet V1(“mobilenet_thin”)上進行的,它在計算預算和延遲方面具有中等性能:
我們參考了Gunjan Seth的文章Pose Estimation with TensorFlow 2.0(https://medium.com/@gsethi2409/pose-estimation-with-tensorflow-2-0-a51162c095ba)。
轉到終端并創建一個工作目錄(例如,“Pose_Estimation”),并移動到那里:
mkdir Pose_Estimation cd Pose_Estimation
創建虛擬環境(例如,Tf2_Py37)
conda create --name Tf2_Py37 python=3.7.6 -y conda activate Tf2_Py37
安裝TF2
pip install --upgrade pip pip install tensorflow
安裝開發期間要使用的基本軟件包:
conda install -c anaconda numpy conda install -c conda-forge matplotlib conda install -c conda-forge opencv
下載tf-pose-estimation:
git clone https://github.com/gsethi2409/tf-pose-estimation.git
轉到tf-pose-estimation文件夾并安裝requirements
cd tf-pose-estimation/ pip install -r requirements.txt
在下一步,安裝SWIG,一個接口編譯器,用C語言和C++編寫的程序連接到Python等腳本語言。它通過在C/C++頭文件中找到的聲明來工作,并使用它們生成腳本語言需要訪問底層C/C++代碼的包裝代碼。
conda install swig
使用SWIG,構建C++庫進行后處理。
cd tf_pose/pafprocess swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace
現在,安裝tf-slim庫,一個用于定義、訓練和評估TensorFlow中復雜模型的輕量級庫。
pip install git+https://github.com/adrianc-a/tf-slim.git@remove_contrib
就這樣!現在,有必要進行一次快速測試。返回tf-pose-estimation主目錄。
如果你按照順序,你必須在 tf_pose/pafprocess內。否則,請使用適當的命令更改目錄。
cd ../..
在tf-pose-estimation目錄中有一個python腳本 run.py,讓我們運行它,參數如下:
model=mobilenet_thin
resize=432x368(預處理時圖像的大小)
image=./images/ski.jpg(圖像目錄內的示例圖像)
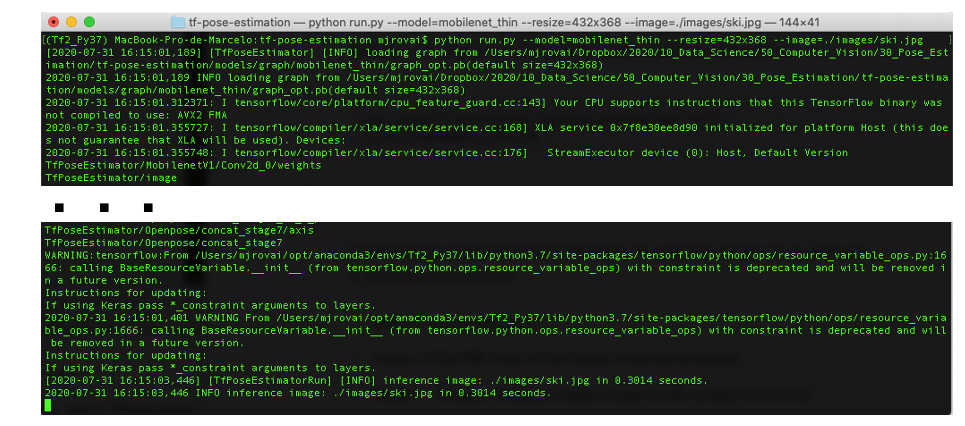
python run.py --model=mobilenet_thin --resize=432x368 --image=./images/ski.jpg
請注意,在幾秒鐘內,不會發生任何事情,但大約一分鐘后,終端應顯示與下圖類似的內容:
但是,更重要的是,圖像將出現在獨立的OpenCV窗口上:
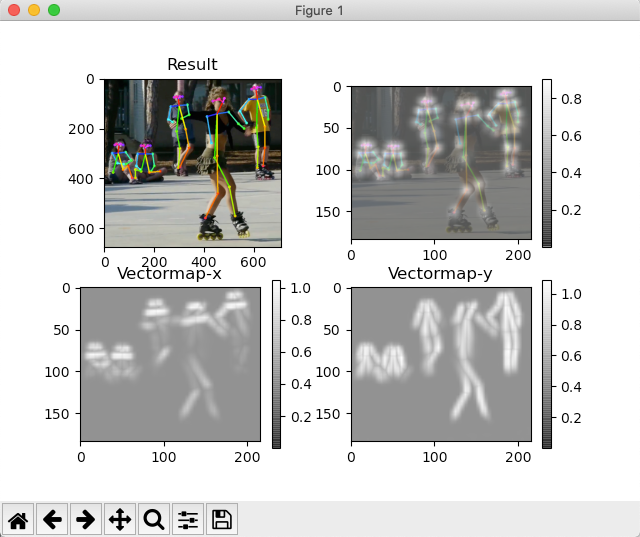
太好了!這些圖片證明了一切都是正確安裝和運作良好的!我們將在下一節中詳細介紹。
然而,為了快速解釋這四幅圖像的含義,左上角(“Result”)是繪制有原始圖像的姿勢檢測骨架(在本例中,ski.jpg)作為背景。右上角的圖像是一個“熱圖”,其中顯示了“檢測到的組件”(S),兩個底部圖像都顯示了組件的關聯(L)。“Result”是把S和L連接起來。
下一個測試是現場視頻:
如果計算機只安裝了一個攝像頭,請使用:camera=0
python run_webcam.py --model=mobilenet_thin --resize=432x368 --camera=1
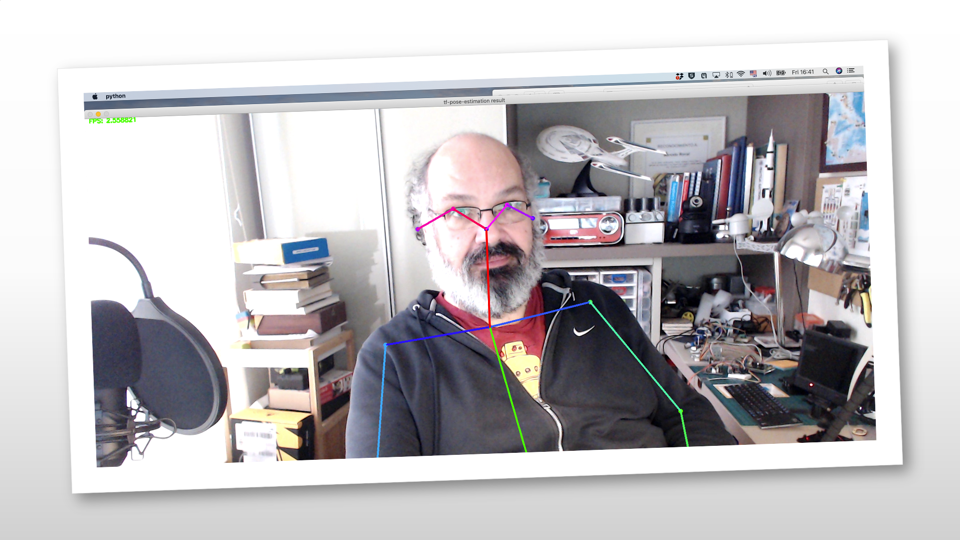
如果一切順利,就會出現一個窗口,里面有一段真實的視頻,就像下面的截圖:
在本節中,我們將更深入地介紹我們的TensorFlow姿勢估計實現。建議你按照這篇文章,試著復制Jupyter Notebook:10_Pose_Estimation_Images,可以從GitHub項目下載:https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/10_Pose_Estimation_Images.ipynb
作為參考,這個項目是在MacPro(2.9Hhz Quad-Core i7 16GB 2133Mhz RAM)上開發的。
import sys import time import logging import numpy as np import matplotlib.pyplot as plt import cv2 from tf_pose import common from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh
可以使用位于model/graph子目錄中的模型,如mobilenet_v2_large或cmu(VGG pretrained model)。
對于cmu,*.pb文件在安裝期間沒有下載,因為它們很大。要使用它,請運行位于/cmu子目錄中的bash腳本download.sh。
這個項目使用mobilenet_thin(MobilenetV1),考慮到所有使用的圖像都應該被調整為432x368。
參數:
model='mobilenet_thin' resize='432x368' w, h = model_wh(resize)
創建估計器:
e = TfPoseEstimator(get_graph_path(model), target_size=(w, h))
為了便于分析,讓我們加載一個簡單的人體圖像。OpenCV用于讀取圖像。圖像存儲為RGB,但在內部,OpenCV與BGR一起工作。使用OpenCV顯示圖像沒有問題,因為在特定窗口上顯示圖像之前,它將從BGR轉換為RGB(如所示ski.jpg上一節)。
一旦圖像被打印到Jupyter單元上,Matplotlib將被用來代替OpenCV。因此,在顯示之前,需要對圖像進行轉換,如下所示:
image_path = ‘./images/human.png’ image = cv2.imread(image_path) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt.imshow(image) plt.grid();

請注意,此圖像的形狀為567x567。OpenCV讀取圖像時,自動將其轉換為數組,其中每個值從0到255,其中0表示“白色”,255表示“黑色”。

一旦圖像是一個數組,就很容易使用shape驗證其大小:
image.shape
結果將是(567567,3),其中形狀是(寬度、高度、顏色通道)。
盡管可以使用OpenCV讀取圖像,但我們將使用tf_pose.common庫中的函數read_imgfile(image_path) 以防止顏色通道出現任何問題。
image = common.read_imgfile(image_path, None, None)
一旦我們將圖像作為一個數組,我們就可以將方法推理應用到估計器(estimator, e)中,將圖像數組作為輸入
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=4.0)
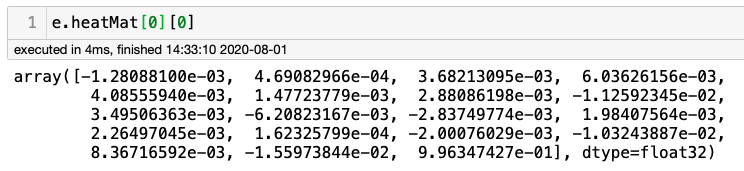
運行上述命令后,讓我們檢查數組e.heatmap。該陣列的形狀為(184,216,19),其中184為h/2,216為w/2,19與特定像素屬于18個關節(0到17)+1(18:none)中的一個的概率有關。例如,檢查左上角像素時,應出現“none”:
可以驗證此數組的最后一個值
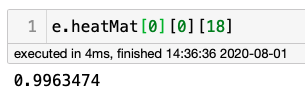
這是最大的值;可以理解的是,在99.6%的概率下,這個像素不屬于18個關節中的任何一個。
讓我們試著找出頸部的底部(肩膀之間的中點)。它位于原始圖片的中間寬度(0.5*w=108)和高度的20%左右,從上/下(0.2*h=37)開始。所以,讓我們檢查一下這個特定的像素:
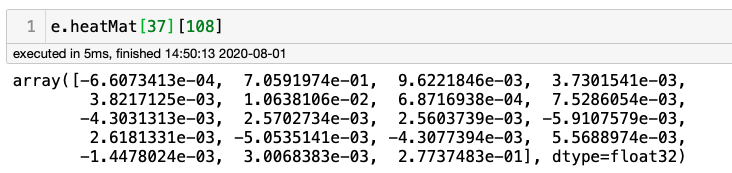
很容易意識到位置1的最大值為0.7059…(或通過計算e.heatMat[37][108].max()),這意味著特定像素有70%的概率成為“頸部”。下圖顯示了所有18個COCO關鍵點(或“身體關節”),顯示“1”對應于“頸部底部”。
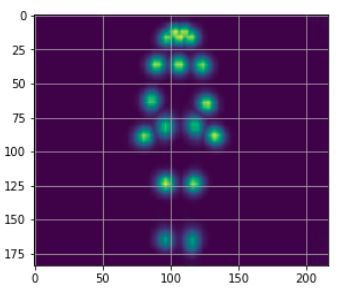
可以為每個像素繪制,一種代表其最大值的顏色。這樣一來,一張顯示關鍵點的熱圖就會神奇地出現:
max_prob = np.amax(e.heatMat[:, :, :-1], axis=2) plt.imshow(max_prob) plt.grid();
我們現在在調整后的原始圖像上繪制關鍵點:
plt.figure(figsize=(15,8)) bgimg = cv2.cvtColor(image.astype(np.uint8), cv2.COLOR_BGR2RGB) bgimg = cv2.resize(bgimg, (e.heatMat.shape[1], e.heatMat.shape[0]), interpolation=cv2.INTER_AREA) plt.imshow(bgimg, alpha=0.5) plt.imshow(max_prob, alpha=0.5) plt.colorbar() plt.grid();

因此,可以在圖像上看到關鍵點,因為color bar上顯示的值意味著:如果黃色更深就有更高的概率。
為了得到L,即關鍵點(或“關節”)之間最可能的連接(或“骨骼”),我們可以使用e.pafMat的結果數組。其形狀為(184,216,38),其中38(2x19)與該像素與18個特定關節+none中的一個作為水平(x)或垂直(y)連接的一部分的概率有關。
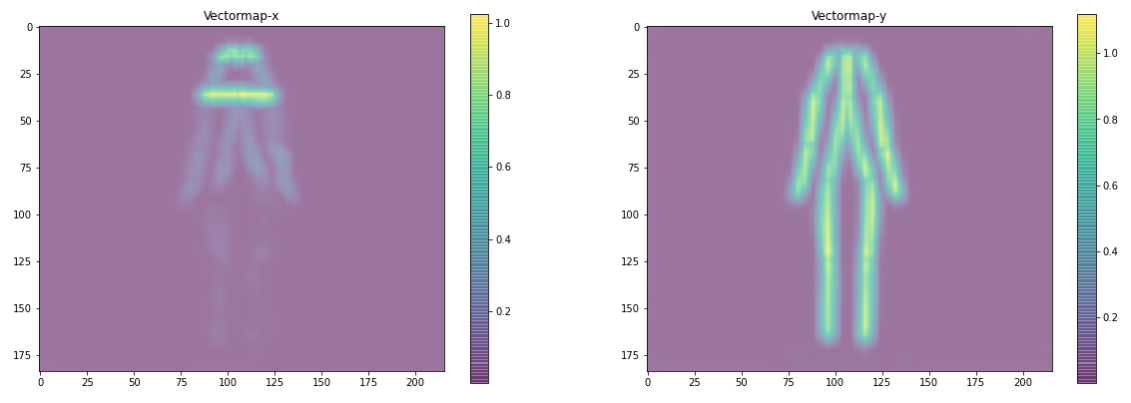
繪制上述圖表的函數在Notebook中。
使用e.inference()方法的結果傳遞給列表human,可以使用draw_human方法繪制骨架:
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
結果如下圖:
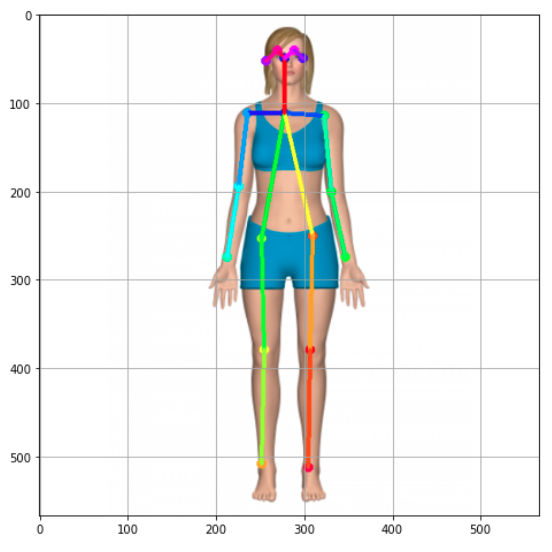
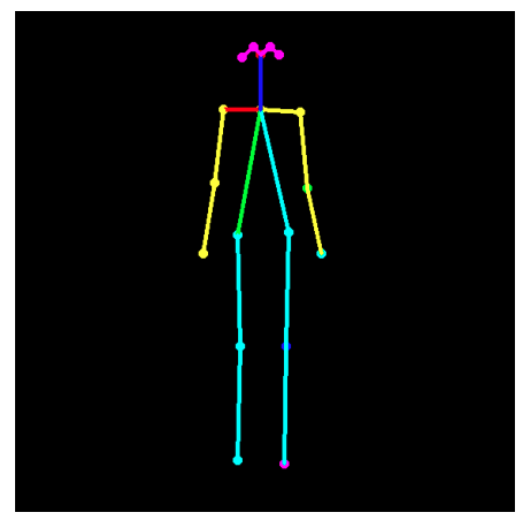
如果需要的話,可以只繪制骨架,如下所示(讓我們重新運行所有代碼進行回顧):
image = common.read_imgfile(image_path, None, None) humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=4.0) black_background = np.zeros(image.shape) skeleton = TfPoseEstimator.draw_humans(black_background, humans, imgcopy=False) plt.figure(figsize=(15,8)) plt.imshow(skeleton); plt.grid(); plt.axis(‘off’);
姿勢估計可用于機器人、游戲或醫學等一系列應用。為此,從圖像中獲取物理關鍵點坐標以供其他應用程序使用可能很有趣。
查看e.inference()生成的human列表,可以驗證它是一個包含單個元素、字符串的列表。在這個字符串中,每個關鍵點都以其相對坐標和相關概率出現。例如,對于目前使用的人像,我們有:

例如:
BodyPart:0-(0.49, 0.09) score=0.79 BodyPart:1-(0.49, 0.20) score=0.75 ... BodyPart:17-(0.53, 0.09) score=0.73
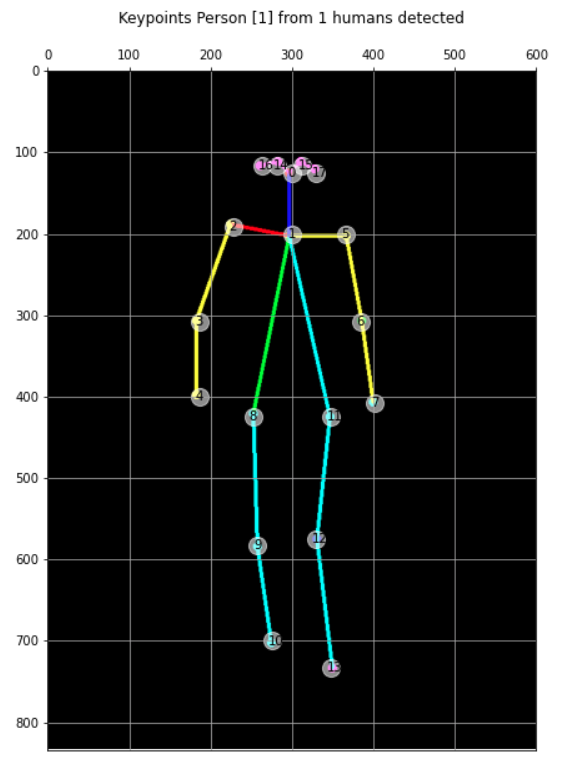
我們可以從該列表中提取一個數組(大小為18),其中包含與原始圖像形狀相關的實際坐標:
keypoints = str(str(str(humans[0]).split('BodyPart:')[1:]).split('-')).split(' score=')
keypts_array = np.array(keypoints_list)
keypts_array = keypts_array*(image.shape[1],image.shape[0])
keypts_array = keypts_array.astype(int)讓我們在原始圖像上繪制這個數組(數組的索引是 key point)。結果如下:
plt.figure(figsize=(10,10)) plt.axis([0, image.shape[1], 0, image.shape[0]]) plt.scatter(*zip(*keypts_array), s=200, color='orange', alpha=0.6) img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt.imshow(img) ax=plt.gca() ax.set_ylim(ax.get_ylim()[::-1]) ax.xaxis.tick_top() plt.grid(); for i, txt in enumerate(keypts_array): ax.annotate(i, (keypts_array[i][0]-5, keypts_array[i][1]+5)

Notebook顯示了迄今為止開發的所有代碼,“encapsulated”為函數。例如,讓我們看看另一幅圖像:
image_path = '../images/einstein_oxford.jpg' img, hum = get_human_pose(image_path) keypoints = show_keypoints(img, hum, color='orange')

img, hum = get_human_pose(image_path, showBG=False) keypoints = show_keypoints(img, hum, color='white', showBG=False)
到目前為止,只研究了包含一個人的圖像。一旦開發出從圖像中同時捕捉所有關節(S)和PAF(L)的算法,為了簡單起見我們找到最可能的連接。因此,獲取結果的代碼是相同的;例如,只有當我們得到結果(“human”)時,列表的大小將與圖像中的人數相匹配。
例如,讓我們使用一個有五個人的圖像:
image_path = './images/ski.jpg' img, hum = get_human_pose(image_path) plot_img(img, axis=False)

算法發現所有的S和L都與這5個人聯系在一起。結果很好!

從讀取圖像路徑到繪制結果,所有過程都不到0.5秒,與圖像中發現的人數無關。
讓我們把它復雜化,讓我們看到一個畫面,人們更“混合”地在一起跳舞:
image_path = '../images/figure-836178_1920.jpg img, hum = get_human_pose(image_path) plot_img(img, axis=False)

結果似乎也很好。我們只繪制關鍵點,每個人都有不同的顏色:
plt.figure(figsize=(10,10))
plt.axis([0, img.shape[1], 0, img.shape[0]])
plt.scatter(*zip(*keypoints_1), s=200, color='green', alpha=0.6)
plt.scatter(*zip(*keypoints_2), s=200, color='yellow', alpha=0.6)
ax=plt.gca()
ax.set_ylim(ax.get_ylim()[::-1])
ax.xaxis.tick_top()
plt.title('Keypoints of all humans detected\n')
plt.grid();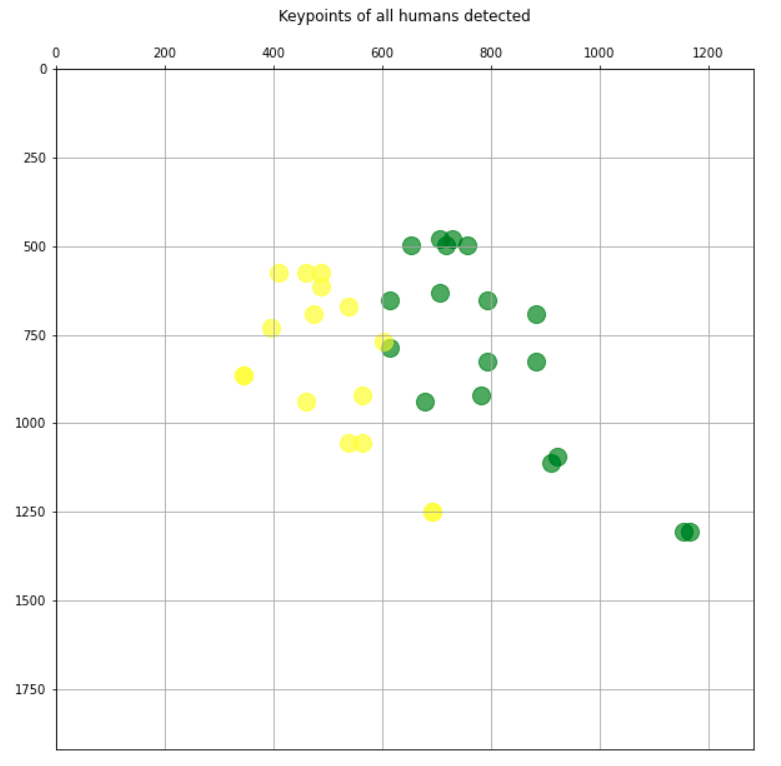
在視頻中獲取姿勢估計的過程與我們對圖像的處理相同,因為視頻可以被視為一系列圖像(幀)。建議你按照本節內容,嘗試復制Jupyter Notebook:20_Pose_Estimation_Video:https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/20_Pose_Estimation_Video.ipynb。
OpenCV在處理視頻方面做得非常出色。
因此,讓我們獲取一個.mp4視頻,并使用OpenCV捕獲其幀:
video_path = '../videos/dance.mp4 cap = cv2.VideoCapture(video_path)
現在讓我們創建一個循環來捕獲每一幀。有了這個框架,我們將應用e.inference(),然后根據結果繪制骨架,就像我們對圖像所做的那樣。最后還包括了一個代碼,當按下一個鍵(例如“q”)時停止視頻播放。
以下是必要的代碼:
fps_time = 0
while True:
ret_val, image = cap.read()
humans = e.inference(image,
resize_to_default=(w > 0 and h > 0),
upsample_size=4.0)
if not showBG:
image = np.zeros(image.shape)
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
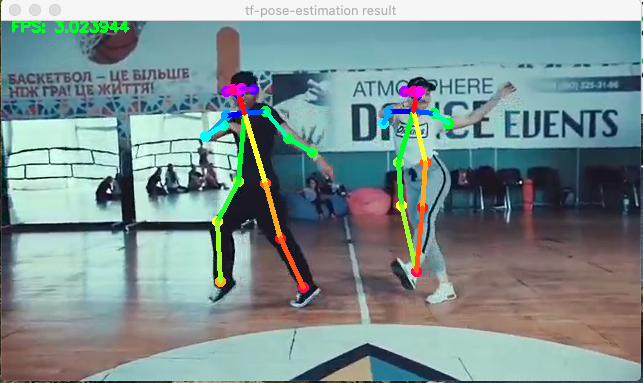
結果很好,但是有點慢。這部電影最初的幀數為每秒30幀,將在“慢攝影機”中運行,大約每秒3幀。
建議你按照本節內容,嘗試復制Jupyter Notebook:30_Pose_Estimation_Camera(https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/30_Pose_Estimation_Camera.ipynb)。
運行實時攝像機所需的代碼與視頻所用的代碼幾乎相同,只是OpenCV videoCapture()方法將接收一個整數作為輸入參數,該整數表示實際使用的攝像機。例如,內部攝影機使用“0”和外部攝影機“1”。此外,相機也應設置為捕捉模型使用的“432x368”幀。
參數初始化:
camera = 1 resize = '432x368' # 處理圖像之前調整圖像大小 resize_out_ratio = 4.0 # 在熱圖進行后期處理之前調整其大小 model = 'mobilenet_thin' show_process = False tensorrt = False # for tensorrt process cam = cv2.VideoCapture(camera) cam.set(3, w) cam.set(4, h)
代碼的循環部分應與視頻中使用的非常相似:
while True:
ret_val, image = cam.read()
humans = e.inference(image,
resize_to_default=(w > 0 and h > 0),
upsample_size=resize_out_ratio)
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cam.release()
cv2.destroyAllWindows()
同樣,當使用該算法時,30 FPS的標準視頻捕獲降低約到10%。
看完上述內容,你們掌握基于TensorFlow2.x的實時多人二維姿勢估計是怎樣的的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





