溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python中北京高考分數線統計的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
前言:
為了幫助廣大考生和家長了解高考歷年的錄取情況,很多網站都匯總了各省市的錄取控制分數線,為廣大考生填報志愿提供參考。因受多種因素影響,每年的分數線或多或少會有一些變動。采集北京2006-2019年的信息。使用Python的Pandas庫完成以下數據分析。
包含三部分內容:從哪里爬取,如何爬取,爬取的結果
代碼:
import pandas as pd
import numpy as np
data=pd.read_excel("scores.xlsx",header=1)
print(data)運行結果:
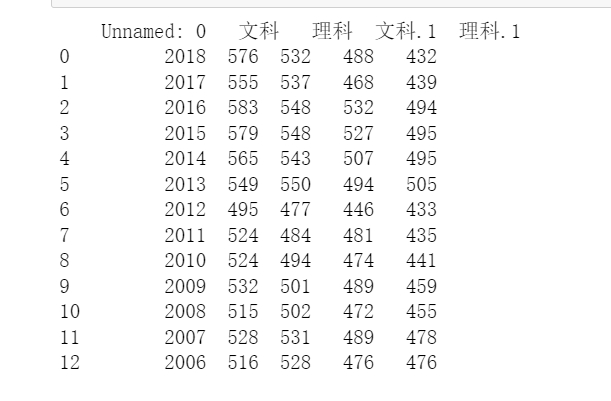
分析:我是讀取的本地的數據文件進行的數據分析。
有興趣的話可以從網站上面下載相關的數據或者是自己使用爬蟲爬取相關的數據源。進行數據分析
這個數據的分析部分我主要是采用的是Pandas numpy做數據的預處理。
和matplotlib進行數據的可視化展示。
mindata= data.groupby(['文科','理科'], as_index=False).min(axis=1) maxdata= data.groupby(['文科','理科'], as_index=False).max(axis=2) print(data.min()) print(data.max())
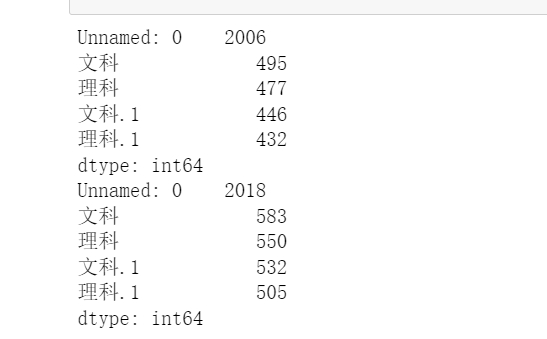
進行數據的處理,最高分最低分統計,因為有兩個不同的年份的成績,并且分了文科和理科所以就有2個文科2個理科
我們使用groupby按照文理科進行分組
然后使用max()和min()求最大值和最小值‘
經過分析處理可以看到打印出來的最大值和最小值
代碼:
s1math=data["一本分數線","理科"] print(s1math) print(s1math[0]-s1math[2]) s1c=data["一本分數線","文科"] print(s1c[0]-s1c[2]) s2math=data["二本分數線","理科"] print(s2math[0]-s2math[2]) s2c=data["二本分數線","文科"] print(s2math[0]-s2math[2])
運行結果:
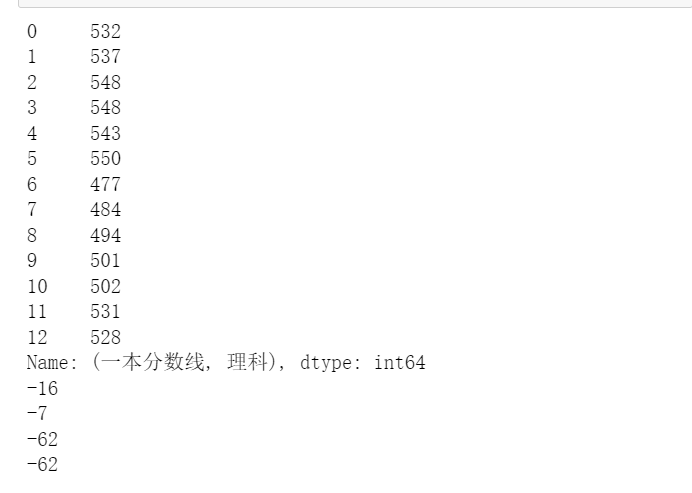
注意:
首先我們取出相應的文理科一本以及二本的成績,然后再進行相關的極差的計算就是使用前一個數減去后面的一個數就OK。
print(s1math[0]-s1math[2])
代碼:
# 2006—2019年近14年每科分數線的平均值統計 data1=data[data['Unnamed: 0'].between(2006, 2014, inclusive=True)].groupby(['Unnamed: 0']).mean() print(data1)
運行結果:
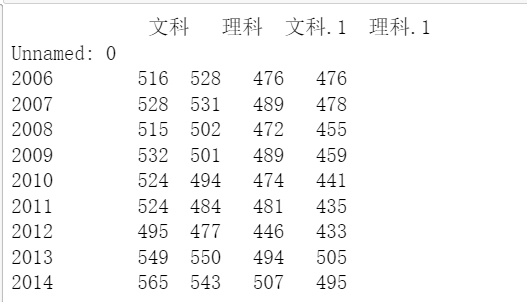
首先是進行數據的提取,然后進行平均值的求取。在這里我算的麻煩了,因為本來就是一個年份對應的是一個成績。不是一對多的關系,所以下面的方法要更好一些。
也可以使用mean方法進行相關的平均值求取。
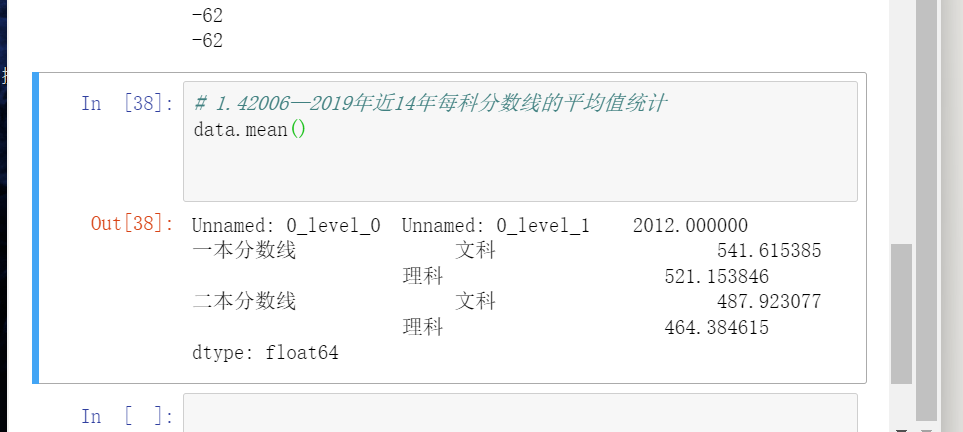
是一個成績。不是一對多的關系,所以下面的方法要更好一些。
也可以使用mean方法進行相關的平均值求取。
以上是“Python中北京高考分數線統計的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





