溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Java集合框架中如何掌握Map和Set 的使用,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
在學習編程時,我們常見的搜索方式有:
直接遍歷:時間復雜度為 O(N),元素如果比較多效率會非常慢
二分查找:時間復雜度為 O(logN),搜索前必須要求序列有序
但是上述排序比較適合靜態類型的查找,即一般不會對區間進行插入和刪除操作。
而現實中的查找如:
根據姓名查詢考試成績
通訊錄(根據姓名查詢聯系方式)
可能在查找時需要進行一些插入和刪除操作,即動態查找。因此上述排序的方式就不太適合。
一般會把要搜索的數據稱為關鍵字(Key),和關鍵字對應的稱為值(Value),這兩者又能組合成為 Key-Value 的鍵值對。
因此動態查找的模型有下面兩種:
純 Key 模型: Set 的存儲模式,比如:
有一個英文詞典,快速查找一個單詞是否在詞典中
快速查找某個名字在不在通訊錄中
Key-Value 模型: Map 的存儲模式,比如:
統計文件中每個單詞出現的次數,統計結果是每個單詞都有與其對應的次數:<單詞, 單詞出現的次數>
梁山好漢的江湖綽號,每個好漢都有自己的江湖綽號:<好漢, 江湖綽號>
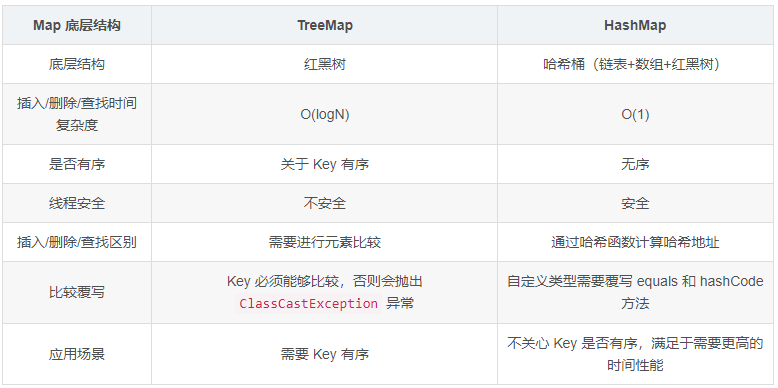
簡單介紹:
Map 是一個接口類,沒有繼承自 Collection。該類中存儲的是 <K, V> 結構的鍵值對,并且 K 一定是唯一的,不能重復
注意:
Map 接口位于 java.util 包中,使用前需要引入它
Map 是一個接口類,故不能直接實例化對象。如果要實例化對象只能實例化其實現類 TreeMap 或 HashMap
Map 中存放的鍵值對的 Key 是唯一的,Value 是可以重復的
文檔信息:

簡單介紹:
Map.Entry<K, V> 是 Map 內部實現的用來存放 <Key, Value> 鍵值對映射關系的內部類。該內部類中主要提供了 <Key, Value> 的獲取,Value 的設置以及 Key 的比較方式
常用方法:
| 方法 | 說明 |
|---|---|
| K getKey() | 返回 entry 中的 key |
| V getValue() | 返回 entry 中的 value |
| V setValue(V value) | 將鍵值對中的 value 替換為指定的 value |
注意:
Map.Entry<K, V> 并沒有提供設置 Key 的方法
文檔信息:


注意:
往 Map 中存儲數據時,會先根據 key 做出一系列的運算,再存儲到 Map 中
如果 key 一樣,那么新插入的 key 的 value,會覆蓋原來 key 的 value
在 Map 中插入鍵值對時,key 和 value 都可以為 null
Map 中的 key 可以全部分離出來,存儲到 Set 中來進行訪問(因為 key 是不能重復的)
Map 中的 value 可以全部分離出來,存儲到 Collection 的任何一個子集中(注意 value 可能有重復)
Map 中的鍵值對的 key 不能直接修改,value 可以修改。如果要修改 key,只能先將 key 刪掉,然后再進行重新插入(或者直接覆蓋)
簡單介紹:
HashMap 是一個散列表,它存儲的內容是鍵值對(key-value)映射
HashMap 實現了 Map 接口,根據鍵的 HashCode 值存儲數據,具有很快的訪問速度,最多允許一條記錄的鍵為 null,不支持線程同步
HashMap 是無序的,即不會記錄插入的順序
HashMap 繼承于 AbstractMap,實現了 Map、Cloneable、java.io.Serializable 接口
注意:
HashMap 類位于 java.util 包中,使用前需要引入它
文檔信息:

簡單介紹:
TreeMap 是一個能比較元素大小的 Map 集合,會對傳入的 key 進行大小排序。其中可以使用元素的自然順序,也可以使用集合中自定義的比較器來進行排序。
不同于 HashMap 的哈希映射,TreeMap 底層實現了樹形結構,即紅黑樹的結構。
注意:
TreeMap 類位于 java.util 包中,使用前需要引入它
文檔信息:

注意:Map 是一個接口類,故不能直接實例化對象,以下以 HashMap 作為實現類為例
示例一: 創建一個 Map 實例
Map<String,String> map=new HashMap<>();
示例二: 插入 key 及其對應值為 value
map.put("惠城","法師");
map.put("曉","刺客");
map.put("喵班長","盜劍客");
System.out.println(map);
// 結果為:{惠城=法師, 曉=刺客, 喵班長=盜劍客}示例三: 返回 key 的對應 value
String str1=map.get("曉");
System.out.println(str1);
// 結果為:刺客示例四: 返回 key 對應的 value,若 key 不存在,則返回默認值 defaultValue
String str2=map.getOrDefault("彌惠","冒險者");
System.out.println(str2);
// 結果為:冒險者示例五: 刪除 key 對應的映射關系
String str3=map.remove("喵班長");
System.out.println(str3);
System.out.println(map);
// 結果為:盜劍客 和 {惠城=法師, 曉=刺客}示例六: 除了上述直接打印 map,也可以通過 Set<Map.Entry<K, V>> entrySet() 這個方法進行遍歷打印
Set<Map.Entry<String,String>> set=map.entrySet();
for(Map.Entry<String,String> str: set){
System.out.println("Key="+str.getKey()+" Value="+str.getValue());
}
/** 結果為:
Key=惠城 Value=法師
Key=曉 Value=刺客
Key=喵班長 Value=盜劍客
*/示例七: 判斷是否包含 key
System.out.println(map.containsKey("惠城"));
// 結果為:true簡單介紹:
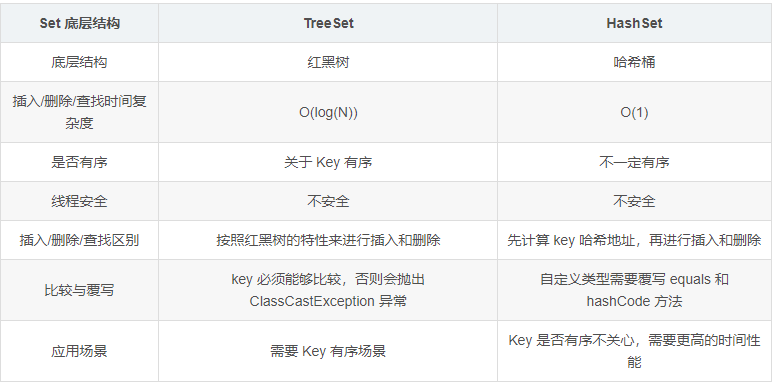
Set 是一個繼承于 Collection 的接口,是一個不允許出現重復元素,并且無序的集合,主要有 HashSet 和 TreeSet 兩大實現類。
注意:
Set 接口位于 java.util 包中,使用前需要引入它
文檔信息:

注意:
Set 中只繼承了 Key,并且要求 Key 唯一
Set 的底層是使用 Map 來實現的,其使用 Key 與 Object 的一個默認對象作為鍵值對插入插入到 Map 中
Set 的最大功能就是對集合中的元素進行去重
實現 Set 接口的常用類有 TreeSet 和 HashSet,還有一個 LinkedHashSet,LinkedHashSet 是在 HashSet 的基礎上維護了一個雙向鏈表來記錄元素的插入次序
Set 中的 Key 不能修改,如果修改,要先將原來的刪除
Set 中可以插入 null
簡單介紹:
TreeSet 實現類 Set 接口,基于 Map 實現,其底層結構為紅黑樹
注意:
TreeSet 類位于 java.util 包中,使用前需要引入它
文檔信息:
簡單介紹:
HashSet 實現了 Set 接口,底層由 HashMap 實現,是一個哈希表結構
新增元素時,新增的元素,相當于 HashMap 的 key,value 則默認為一個固定的 Object
注意:
HashSet 類位于 java.util 包中,使用前需要引入它
文檔信息:

注意:Set 是一個接口類,故不能直接實例化對象,以下以 HashSet 作為實現類為例
示例一: 創建一個 Set 實例
Set<Integer> set=new HashSet<>();
示例二: 添加元素(重復元素無法添加成功)
set.add(1); set.add(2); set.add(3); set.add(4); set.add(5); System.out.println(set); // 結果為:[1, 2, 3, 4, 5]
示例三: 判斷 1 是否在集合中
System.out.println(set.contains(1)); // 結果為:true
示例四: 刪除集合中的元素
System.out.println(set.remove(3)); // 結果為:true
示例五: 返回 set 中集合的個數
System.out.println(set.size()); // 結果為:4
示例六: 檢測 set 是否為空
System.out.println(set.isEmpty()); // 結果為:false
示例七: 返回迭代器,進行遍歷
Iterator<Integer> it=set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
// 結果為:1 2 4 5hashNext() 方法是判斷當前元素是否還有下一個元素,next() 是獲取當前元素,并且指向下一個元素
示例八: 清空集合
set.clear(); System.out.println(set); // 結果為:[]
題目:
從一些數據中,打印出第一個重復數據
代碼:
public static void findNum(int[] array){
Set<Integer> set=new HashSet<>();
for(int i=0;i<array.length;i++){
if(set.contains(array[i])){
System.out.println(array[i]);
break;
}
set.add(array[i]);
}
}題目:
去除一些數據當中重復的數據
代碼:
public static int[] removeSample(int[] array){
Set<Integer> set=new HashSet<>();
for(int i=0;i<array.length;i++){
set.add(array[i]);
}
Object[] arr=set.toArray();
return array;
}題目:
統計重復的數據出現的次數
代碼:
public static Map count(int[] array){
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<array.length;i++){
if(map.containsKey(array[i])){
int val=map.get(array[i]);
map.remove(array[i]);
map.put(array[i],val+1);
}else {
map.put(array[i], 1);
}
}
return map;
}題目(OJ 鏈接):
給定一個非空整數數組,除了某個元素只出現一次以外,其余每個元素均出現兩次。找出那個只出現了一次的元素
代碼1: 異或法
public int singleNumber(int[] nums) {
int sum=0;
for(int i=0;i<nums.length;i++){
sum=sum^nums[i];
}
return sum;
}代碼2: 使用 HashSet
public int singleNumber(int[] nums) {
Set<Integer> set=new HashSet<>();
for(int val: nums){
if(set.contains(val)){
set.remove(val);
}else{
set.add(val);
}
}
for(int val: nums){
if(set.contains(val)){
return val;
}
}
return -1;
}題目(OJ 鏈接):
給你一個長度為 n 的鏈表,每個節點包含一個額外增加的隨機指針 random ,該指針可以指向鏈表中的任何節點或空節點。
代碼:
public static Node copyRandomList(Node head) {
Map<Node,Node> map=new HashMap<>();
Node cur=head;
while(cur!=null){
Node node=new Node(cur.val);
map.put(cur,node);
cur=cur.next;
}
cur=head;
while(cur!=null){
Node node=map.get(cur);
node.next=map.get(cur.next);
node.random=map.get(cur.random);
cur=cur.next;
}
return map.get(head);
}題目(OJ 鏈接):
給你一個字符串 jewels 代表石頭中寶石的類型,另有一個字符串 stones 代表你擁有的石頭。 stones 中每個字符代表了一種你擁有的石頭的類型,你想知道你擁有的石頭中有多少是寶石。
字母區分大小寫,因此 “a” 和 “A” 是不同類型的石頭。
代碼:
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set=new HashSet<>();
for(int i=0;i<jewels.length();i++){
set.add(jewels.charAt(i));
}
int count=0;
for(int i=0;i<stones.length();i++){
if(set.contains(stones.charAt(i))){
count++;
}
}
return count;
}題目(OJ 鏈接):
舊鍵盤上壞了幾個鍵,于是在敲一段文字的時候,對應的字符就不會出現。現在給出應該輸入的一段文字、以及實際被輸入的文字,請你列出
肯定壞掉的那些鍵。
代碼:
import java.util.*;
public class Main{
public static void main(String[] args){
Set<Character> set=new HashSet<>();
List<Character> list=new ArrayList<>();
Scanner scanner=new Scanner(System.in);
String str1=scanner.next();
String str2=scanner.next();
char[] s1=str1.toUpperCase().toCharArray();
char[] s2=str2.toUpperCase().toCharArray();
for(int i=0;i<s2.length;i++){
set.add(s2[i]);
}
for(int i=0;i<s1.length;i++){
if(!set.contains(s1[i])){
set.add(s1[i]);
System.out.print(s1[i]);
}
}
}
}題目(OJ 鏈接):
給一非空的單詞列表,返回前 k 個出現次數最多的單詞。返回的答案應該按單詞出現頻率由高到低排序。如果不同的單詞有相同出現頻率,按字母順序排序。
代碼:
public List<String> topKFrequent(String[] words, int k) {
Map<String,Integer> map=new HashMap<>();
for(String s: words){
if(map.containsKey(s)){
map.put(s,map.get(s)+1);
}else{
map.put(s,1);
}
}
PriorityQueue<Map.Entry<String,Integer>> minHeap=new PriorityQueue<>(new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Map.Entry<String,Integer> s1, Map.Entry<String,Integer> s2){
if(s1.getValue().compareTo(s2.getValue())==0){
return s2.getKey().compareTo(s1.getKey());
}
return s1.getValue()-s2.getValue();
}
});
for(Map.Entry<String,Integer> entry: map.entrySet()){
if(minHeap.size()<k){
minHeap.add(entry);
}else{
if(entry.getValue().compareTo(minHeap.peek().getValue())>0){
minHeap.poll();
minHeap.offer(entry);
}else if(entry.getValue().compareTo(minHeap.peek().getValue())==0){
if(entry.getKey().compareTo(minHeap.peek().getKey())<0){
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
List<String> list=new ArrayList<>();
for(int i=0;i<k;i++){
Map.Entry<String,Integer> top=minHeap.poll();
list.add(top.getKey());
}
Collections.reverse(list);
return list;
}簡單介紹:
哈希表(也叫做散列表),是根據關鍵碼(Key Value)而直接進行訪問的數據結構。它通過把關鍵碼映射到表中的一個位置來訪問記錄,以加快查找的速度。這個映射函數叫做哈希函數(也叫做散列函數),存放記錄的數組叫做哈希表(也叫散列表)
在之前講解的數據結構中,元素關鍵碼及其存儲位置之間沒有對應的關系,因此在查找一個元素時,必須要經過關鍵碼的多次比較,搜索的效率取決于搜索過程中元素的比較次數。例如:
順序查找的時間復雜度為:O(N)
二分查找的時間復雜度為:O(log(N))
我們希望有一種理想的搜索方法,它可以不經過任何比較,能直接從表中得到要搜索的元素。因此就有了哈希表,它的原理就是:通過某種函數使元素的存儲位置與它的關鍵碼之間能夠建立一一映射的關系,例如:
插入元素:
根據待插入元素的關鍵碼,以某個函數計算出該元素的存儲位置,并按此位置進行存放
搜索元素:
用該函數對元素的關鍵碼進行計算,把求得的函數值當作元素的存儲位置,在此結構中按此位置取元素與要搜索的元素進行比較,若關鍵碼相等,則搜索成功
上述的方法就叫做哈希方法(也叫散列方法),其中哈希方法中使用的轉換函數稱為哈希函數(也叫做散列函數),構造出來的結構稱為哈希表(也叫散列表)
示例: 當我們將哈希函數設置為:hash(key) = key % capacity 時,我們往一個數組中存放以下幾個元素,存放形式如下
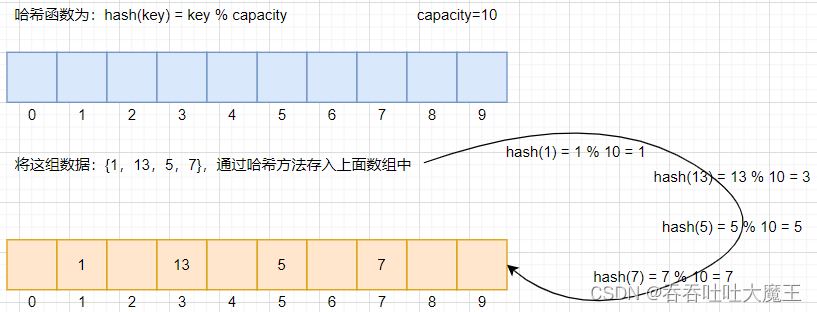
但是使用哈希方法會出現一個問題:哈希沖突
簡單介紹:
哈希沖突(也叫做哈希碰撞),是指對于兩個數據元素的關鍵字 ki 和 kj (i != j),雖然 ki != kj,但是存在:Hash(ki) == Hash(kj),即不同關鍵字通過相同哈希函數,可能會計算出相同的哈希地址
示例: 當我們將哈希函數設置為:hash(key) = key % capacity 時,元素 3 和 13 通過該哈希函數計算出的存放位置是一樣的
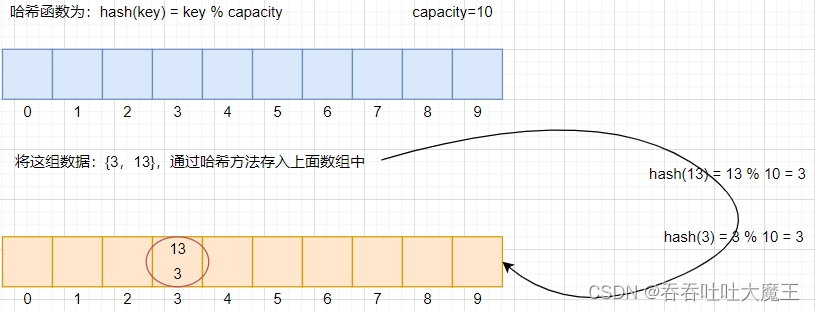
由于哈希表底層數組的容量往往是小于實際要存儲的關鍵字的數量的,這就導致,哈希沖突的發生是必然的。并且哈希沖突不能根本上消除,為此我們就要
在哈希沖突發生前:盡量避免
在哈希沖突發生后:重點解決
引起哈希沖突的一個原因可能是:哈希函數設計不合理
哈希函數的設計原則:
哈希函數的定義域必須包括需要存儲的全部關鍵碼,而如果散列表允許有m個地址時,其值域必須在0到 m-1 之間
哈希函數計算出來的地址能夠均勻分布在整個空間中
哈希函數應該比較簡單
常見哈希函數:
直接定制法(常用)
思路:取關鍵字的某個線性函數為散列地址:Hash(Key) = A * Key + B
優點:簡單、均勻
缺點:需要事先知道關鍵字的分布情況
使用場景:適合查找比較小且連續的情況
除留余數法(常用)
思路:設散列表中允許的地址數為m,取一個不大于m,但最接近或者等于m的質數p作為除數,按照哈希函數:Hash(Key) = Key % p (p<=m) 將關鍵碼轉換成哈希地址
平方取中法(了解)
思路:假設關鍵字為1234,對它去平方就是1522756,抽取中間的3位數227作為哈希地址。再比如關鍵字為3241,它的平方就是18671041,抽取中間的3位671作為哈希地址
使用場景:不知道關鍵字的分布,而位數又不是很大的情況
折疊法(了解)
思路:將關鍵字從左到右分割成位數相等的及部分(最后一部分位數可以短些),然后將這幾部分疊加求和,并按散列表表長,取后幾位作為散列地址
使用場景:事先不需要知道關鍵字的分布,且關鍵字位數比較多的情況
隨機數法(了解)
思路:選擇一個隨機函數,取關鍵字的隨機函數值為它的哈希地址,即 Hash(Key) = random(Key) (random 為隨機函數)
使用場景:通常應用于關鍵字長度不等時的情況
數學分析法(了解)
思路:設有n個d位數,每一位可能有r種不同的符號,這r種不同的符號在各位上出現的頻率不一定相同,可能在某些位上分布比較均勻,每種符號出現的機會均等,在某些位上分布不均勻的只有某幾種符號。可跟據散列表的大小,選擇其中各種符號分布均勻的若干位作為散列地址
使用場景:適合處理關鍵字位數比較大的情況,如果事先知道關鍵字的分布且關鍵字的若干位分布較均與的情況
負載因子定義:
散列表的載荷因子定義為:α = 填入表中的元素個數 / 散列表的長度
α 是散列表裝滿程度的標志因子。由于表長是定值,α 與填入表中的元素個數成正比,所以 α 越大,表明填入表中的元素越多,產生沖突的可能性就越大;反之 α 越小,表名填入表中的元素越少,產生沖突的可能性就越小
一些采用開放定址法的 hash 庫,如 Java 的系統庫限制了載荷因子為0.75,超過此值將 resize 散列表
負載因子和沖突率的關系粗略演示圖:
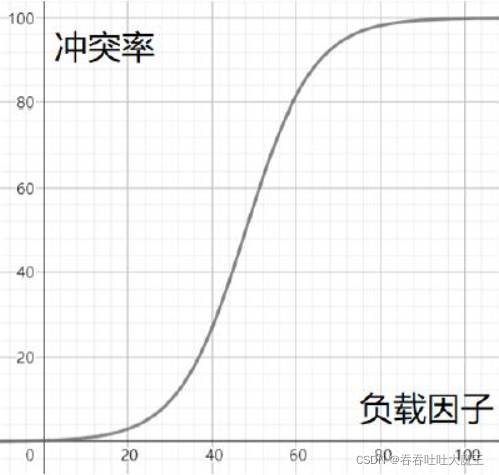
通過演示圖我們可以很直觀的了解,當沖突率越大時,我們需要通過降低負載因子來變相降低沖突率。而填入表中的元素個數已成定局,我們不能夠修改,因此需要調整哈希表中的數組大小,即調整散列表長度
解決哈希沖突兩種常見的方法:
閉散列
開散列
簡單介紹:
閉散列:也叫開放定址法,當發生哈希沖突時,如果哈希表未被裝滿,說明哈希表中必然還有空位置,那么可以把 Key 存放到沖突位置的下一個空位置中去
尋找沖突位置下一個空位置的方法:
線性探測
方法:從發生沖突的位置開始,依次向后探測,直到尋找到下一個空位置為止,如果后面的位置都滿了,則會從頭開始尋找
缺點:會將所有沖突元素都堆積在一起
二次探測
方法:Hi = (H0 + i2) % m 或者 Hi = (H0 - i2) % m(i = 1,2,3…),H0 是通過散列函數 Hash(x) 對元素的關鍵碼 key 進行計算得到的位置,m是表的大小,Hi 是尋找到的空位置
缺點:空間利用率較低,這也是哈希表的缺陷
簡單介紹:
開散列:也叫做鏈地址法或開鏈法或哈希桶,首先對關鍵碼集合用散列函數計算散列地址,具有相同地址的關鍵碼歸于同一子集合,每一個子集合稱為一個桶,各個桶的元素通過一個單鏈表連接起來,各個鏈表的頭節點存儲在哈希表中
補充:
HashMap 的底層就是一個開散列
可以認為開散列是把一個在大集合中的搜索問題轉化為在小集合中做搜索
由于會盡量避免沖突,所以沖突率其實會有保障,因此當在單鏈表中做搜索時,其實很快,時間復雜度接近:O(1)
但是當沖突很嚴重時,那么在單鏈表這個小集合中做搜索其實性能就會大大降低,因此單鏈表就不太適合做小集合的結構
沖突嚴重時的解決辦法:
將哈希桶的結構替換成另一個哈希表
將哈希桶的結構替換成搜索樹
補充: Hash表的平均查找長度(ASL)包括查找成功時的平均查找長度和查找失敗時的平均查找長度
查找成功的平均查找長度=表中每個元素查找成功時的比較次數之和/表中元素個數
查找不成功的平均查找長度=該位置如果查找一個元素失敗的次數/表的長度
題目:
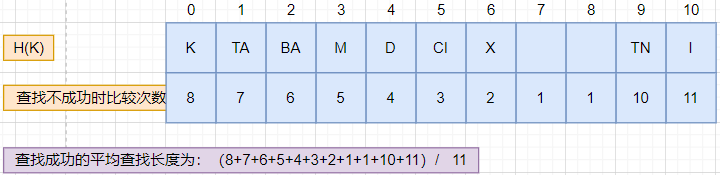
設哈希表長度為11,哈希函數 H(K) = (K的第一個字母在字母表中的序號) % 11,若輸入順序為(D、BA、TN、M、CI、I、K、X、TA),采用閉散列處理沖突方法為線性探測,要求構造哈希表,在等概率的情況下查找成功的平均查找長度為( ),查找不成功的平均查找長度為( )
查找成功的平均查找長度為:20/9

查找不成功的平均查找長度為:58/11
雖然哈希表一直在和沖突做斗爭,但在實際使用過程中,哈希表的沖突率是不高的,沖突個數是可控的,也就是每個桶中的鏈表的長度是一個常數。
因此,通常意義下我們認為哈希表的插入、刪除、查找時間復雜度為:O(1)
HashMap 底層是:數組+單鏈表
我們可以先定義一個最基礎的哈希表,讓他可以實現整形的存值、取值等(哈希函數設定為:Hash(Key) = Key % capacity)
class HashBuck{
static class Node{
public int key;
public int value;
public Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
public Node[] array;
public int usedSize;
public HashBuck(){
this.array=new Node[8];
}
// 獲取 key 對應的 value
public int get(int key){
int index=key%this.array.length;
Node cur=this.array[index];
while(cur!=null){
if(cur.key==key){
return cur.value;
}
cur=cur.next;
}
return -1; // 這里先用 -1 返回,也可以拋異常
}
// 新增元素
public void put(int key, int val){
int index=key%this.array.length;
Node cur=this.array[index];
Node node=new Node(key,val);
if(cur==null){
this.array[index]=node;
}else{
while(cur.next!=null){
if(cur.key==key){
cur.value=val;
break;
}
cur=cur.next;
}
cur.next=node;
}
this.usedSize++;
if(loadFactor()>=0.75){
resize();
}
}
// 計算負載因子
public double loadFactor(){
return this.usedSize*1.0/this.array.length;
}
// 擴容后,重新構造哈希
public void resize(){
Node[] oldArray=this.array;
this.array=new Node[2*oldArray.length];
this.usedSize=0;
for(int i=0;i<oldArray.length;i++){
Node cur=oldArray[i];
while(cur!=null){
put(cur.key,cur.value);
cur=cur.next;
}
}
}
} 當我們實現了對整形的部分哈希表的實現后,如果要實現其它類型是有問題的,因為我們設計的哈希函數為:Hash(Key) = Key % capacity,而其它類型都不能取模,因此我們需要能夠對 Key 進行數字轉換的方法。而在 Object 類有一個 hashCode() 方法,它能將傳過來的對象,轉換成一個合法的數字,以此來找到合適的位置,因此使用它就能解決我們上述的麻煩。除此之外,上述代碼中的一些==需要修改為 equals() 方法,因為 equals 它能夠判斷傳入的對象的實例是否相等
通過上面一部分的分析,最終可以得到如下代碼:
class HashBuck<K,V>{
static class Node<K,V>{
public K key;
public V val;
public Node<K,V> next;
public Node(K key,V val){
this.key=key;
this.val=val;
}
}
public Node<K,V>[] array=new Node[8];
public int usedSize;
public void put(K key,V val){
int hash=key.hashCode();
int index=hash%this.array.length;
Node<K,V> cur=this.array[index];
Node<K,V> node=new Node<K,V>(key,val);
if(cur==null){
this.array[index]=node;
}else{
while(cur.next!=null){
if(cur.key.equals(key)){
cur.val=val;
break;
}
cur=cur.next;
}
cur.next=node;
}
this.usedSize++;
if(loadFactor()>=0.75){
resize();
}
}
public V get(K key){
int hash=key.hashCode();
int index=hash%this.array.length;
Node<K,V> cur=this.array[index];
while(cur!=null){
if(cur.key.equals(key)){
return cur.val;
}
cur=cur.next;
}
return null;
}
// 計算負載因子
public double loadFactor(){
return this.usedSize*1.0/this.array.length;
}
// 重新哈希
public void resize(){
Node<K,V>[] oldArray=this.array;
this.array=(Node<K, V>[]) new Node[2*oldArray.length];
this.usedSize=0;
for(int i=0;i<oldArray.length;i++){
Node<K,V> cur=oldArray[i];
while(cur!=null){
put(cur.key,cur.val);
cur=cur.next;
}
}
}
}如果 hashCode 一樣,那么 equals 會一樣嗎?
equals 不一定一樣,因為 hashCode 是確定在數組中存儲的位置是不是一樣,但不能確定在哈希桶中,存放的 key 是不是一樣,即不能確定 equals 的結果是不是一樣
如果 equals 一樣,那么 hashCode 一樣嗎?
hashCode 一定一樣,因為 equals 一樣了,那么在數組中存儲的位置是肯定一樣的
HashMap 和 HashSet 即 Java 中利用哈希表實現的 Map 和 Set
Java 中會使用哈希桶解決哈希沖突
Java 會在沖突鏈表長度大于一定閾值后,將鏈表轉變為搜索樹(紅黑樹)。具體數值為當前鏈表的長度超過8且當前桶的個數大于等于64時,就會將當前長度超過8的鏈表變為紅黑樹
Java 中計算哈希值實際上是調用 Object 類的 hashCode 方法,進行 Key 的相等性比較是調用的 equals 方法
自定義類如果需要作為 HashMap 的 Key 或者 HashSet 的值,必須重寫 hashCode 和 equals 方法
HashMap 的默認容量是:16

HashMap 的最大容量為:1 << 30(必須為2的倍數)

HashMap 默認負載因子為:0.75

HashMap 中的單鏈表變為紅黑樹的條件,該值將在 putVal 方法中出現

HashMap 有四種構造方法
方法一: 沒有參數,則哈希表容量為:0,負載因子為:0.75

方法二: 傳入一個 Map 參數,則哈希表負載因子為:0.75
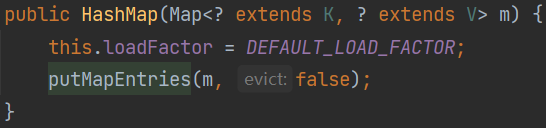
方法三: 傳一個容量參數 initialCapacity,則哈希表容量為:initialCapacity,負載因子為:0.75

方法四: 傳兩個參數,容量參數 initialCapacity,負載因子參數 loadFactor,則哈希表負載因子為:loadFactor
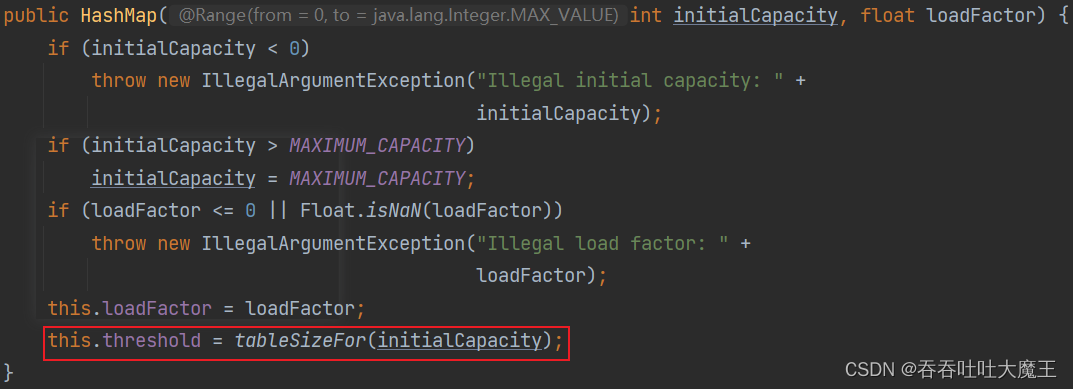
但是哈希表容量在這里不能確定,它有一個 tableSizeFor 的方法,為此我們轉到它的源碼
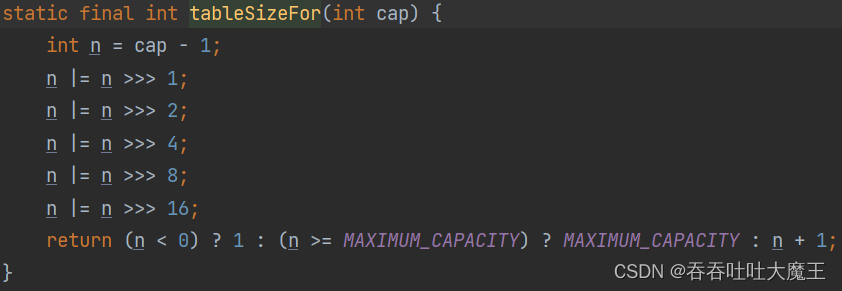
這個方法的意思是返回一個最近接傳入的 initialCapacity 參數的向上取整的2的次方的數字,例如傳入的參數為18,那么哈希表的容量就為32,傳入的參數為1000,那么哈希表的容量就為1024
put 方法的實現

hash 方法的實現,由于 hashCode 被 native 修飾,故無法看到具體源碼

putVal 方法的實現(代碼太長,就直接了,個人在下面代碼中做了注釋)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 當哈希表的大小為 0 時,進行 resize 調整
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// ((n - 1) & hash) 其實等價于 (n % 數組長度) 但是前提條件是,n是2的次冪
// 如果為 null 就是第一次插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 如果不為 null,就進行尾插法
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 當單鏈表的長度大于8時,轉換為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}resize 方法的實現(以2倍的方式進行擴容)
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}問題一:如果 new HashMap(19),那么 bucket 數組有多大?
32,原因在第9大節的構造方法四中
問題二:HashMap 什么時候開辟 bucket 數組占用內存?
第一次 put 的時候
問題三:HashMap 何時擴容?
當填入的元素/容量大于負載因子的時候,進行擴容,jdk1.8 負載因子默認為0.75
問題四:當兩個對象的 hashCode 相同時會發生什么?
會發生哈希沖突
問題五:如果兩個鍵的 hashCode 相同,你如何獲取值對象?
遍歷當前位置的鏈表,通過 equals 返回和要查詢的 Key 值一樣的 Key 的 Value
問題六:你了解重新調整 HashMap 大小存在什么問題嗎?
重新調整大小一定要進行重新哈希
關于Java集合框架中如何掌握Map和Set 的使用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





