溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Go語言如何實現并發爬蟲,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
定義一個用戶
var Client http.Client
主函數
func main() {
url := "http://localhost:3000/api/v1/products"
start := time.Now()
for i := 0; i < 10; i++ {
Spider(url, i)
}
elapsed := time.Since(start)
fmt.Printf("Time %s", elapsed)
}爬取函數
func Spider(url string, i int) {
reqSpider, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatal(err)
}
reqSpider.Header.Set("content-length", "0")
reqSpider.Header.Set("accept", "*/*")
reqSpider.Header.Set("x-requested-with", "XMLHttpRequest")
respSpider, err := Client.Do(reqSpider)
if err != nil {
log.Fatal(err)
}
bodyText, _ := ioutil.ReadAll(respSpider.Body)
var result Result
_ = json.Unmarshal(bodyText, &result)
fmt.Println(i,result.Data)
}運行時間為:651.8207ms

我們構造一個無緩沖的通道,來阻塞主進程,等待子進程的執行。
func main() {
url := "http://localhost:3000/api/v1/products"
ch := make(chan bool)
start := time.Now()
for i := 0; i < 10; i++ {
go Spider(url, ch, i)
}
for i := 0; i < 10; i++ {
<-ch
}
elapsed := time.Since(start)
fmt.Printf("Time %s", elapsed)
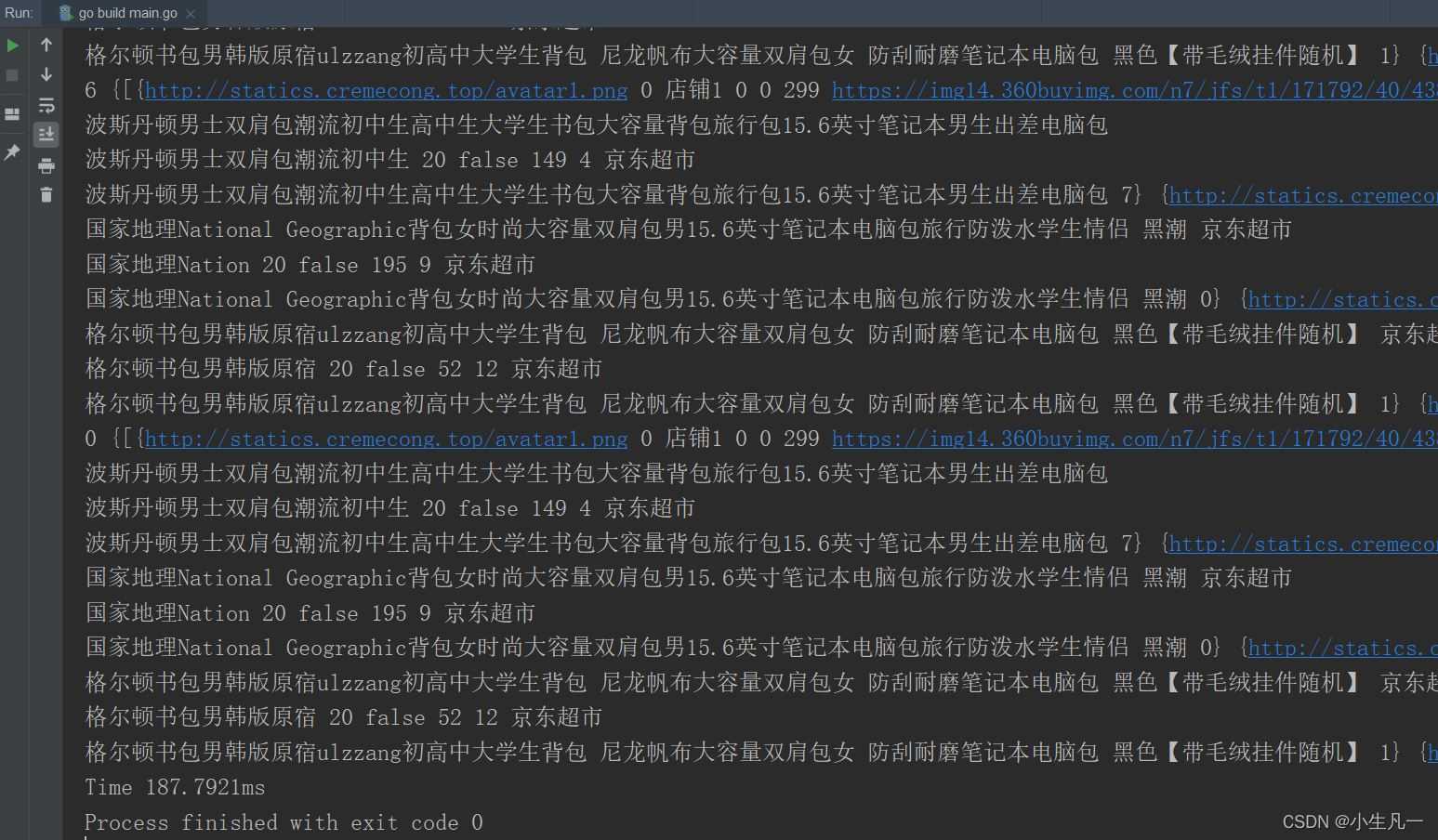
}最后記得在爬蟲的結束的時候,把值寫入到通道中,不然會一直阻塞主進程

運行時間:187.7921ms 比之前快了非常多。
定義一個進程組并加10個進程
var wg sync.WaitGroup wg.Add(10)
開辟十個goruntime
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
SpiderWaitGroup(url,i)
}(i)
}阻塞主進程
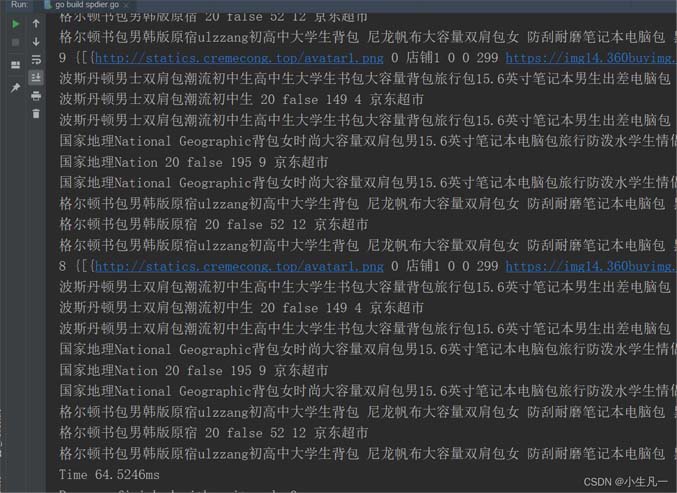
wg.Wait()
結果:64.5246ms
GitHub地址:https://github.com/CocaineCong/Go-Spider-Demo
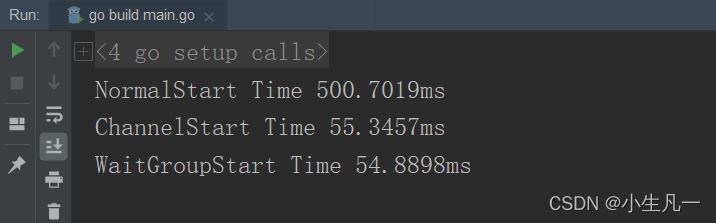
NormalStart(url) // 單線程爬蟲 ChannelStart(url) // Channel多線程爬蟲 WaitGroupStart(url) // Wait 多線程爬蟲
其實多線程的兩種都差不多的,只是有時候會因為機器的原因而導致一些誤差。
關于“Go語言如何實現并發爬蟲”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





