溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python如何批量操作Excel文件,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
OS的全稱是Operation System,指操作系統。在Python里面OS模塊中主要提供了與操作系統即電腦系統之間進行交互的一些功能。我們很多的自動化操作都會依賴于該模塊的功能。
我們在最開始Python基礎知識那一章節給講了如何安裝Anaconda以及如何利用Jupyter notebook寫代碼。可是你們知道你們寫在Jupyter notebook里面的代碼存儲在電腦的哪里嗎?
是不是很多同學不知道?想要知道也很簡單,只需要在Jupyter notebook中輸入如下代碼,然后運行:
import os os.getcwd()
運行上面代碼會得到如下結果:
'C:\\Users\\zhangjunhong\\python庫\\Python報表自動化'
上面這個文件路徑就是此時notebook代碼文件所在的路徑,你的代碼存儲在哪個文件路徑下,運行就會得到對應結果。
我們經常會將電腦本地的文件導入到Python中來處理,在導入之前需要知道文件的存儲路徑以及文件名。如果只有一兩個文件的話還好,我們直接把文件名和文件路徑手動輸入即可,但是有的時候需要導入的文件會有很多。這個時候手動輸入效率就會比較低,就需要借助代碼來提高效率。
如下文件夾中有四個Excel文件:
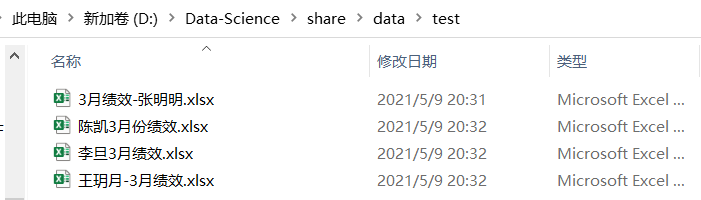
我們可以使用os.listdir(path)來獲取path路徑下所有的文件名。具體實現代碼如下:
import os
os.listdir('D:/Data-Science/share/data/test')運行上面代碼會得到如下結果:
['3月績效-張明明.xlsx', '李旦3月績效.xlsx', '王玥月-3月績效.xlsx', '陳凱3月份績效.xlsx']
對文件進行重命名也是比較高頻的一種需求,我們可以利用os.rename('old_name','new_name')來對文件進行重命名。old_name就是舊文件名,new_name就是新文件名。
我們先在test文件夾下面新建一個名為test_old的文件,然后再利用如下代碼,就可以把test_old文件名改成test_new:
os.rename('D:/Data-Science/share/data/test/test_old.xlsx'
,'D:/Data-Science/share/data/test/test_new.xlsx')運行上面代碼以后,再到test文件夾下面,就可以看到test_old文件已經不存在了,只有test_new。
當我們想要在指定路徑下創建一個新的文件夾時,可以選擇手動新建文件夾,也可以利用os.mkdir(path)進行新建,只需要指明具體的路徑(path)即可。
如下所示,當我們運行下面代碼,就表示在D:/Data-Science/share/data路徑下新建一個名為test11的文件夾:
os.mkdir('D:/Data-Science/share/data/test11')
刪除文件夾與創建文件夾是相對應的,當然了,我們也可以選擇手動刪除一個文件夾,也可以利用os.removedirs(path)進行刪除,指明要刪除的路徑(path)。
如下所示,當我們運行如下代碼,就表示把剛剛創建的test11文件夾刪除了:
os.removedirs('D:/Data-Science/share/data/test11')刪除文件時刪除一個具體的文件,而刪除文件夾是將一整個文件夾,包含文件夾中的所有文件進行刪除。刪除文件利用的是os.remove(path),指明文件所在的路徑(path)。
如下所示,當我們運行如下代碼,就表示將test文件夾中test_new文件進行刪除:
os.remove('D:/Data-Science/share/data/test/test_new.xlsx')有的時候一個文件夾下面會包含多個相類似的文件,比如一個部門不同人的績效文件,我們需要把這些文件批量讀取到Python里面中,然后進行處理。
我們在前面學過,如何讀取一個文件,可以用load_work,也可以用read_excel,不管用哪種方式,都只需要指明要讀取文件的路徑即可。
那如何批量讀取呢?先獲取該文件下的所有文件名,然后再遍歷讀取每一個文件。具體實現代碼如下所示:
import pandas as pd
#獲取文件夾下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for循環遍歷讀取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
print('{}讀取完成!'.format(i))如果要對讀取進來的文件進行數據操作的時候,把具體的操作實現代碼放置在讀取代碼之后即可。比如我們要對每一個讀取進來的文件進行刪除重復值處理,實現代碼如下:
import pandas as pd
#獲取文件夾下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for循環遍歷讀取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
df = df.drop_duplicates() #刪除重復值處理
print('{}讀取完成!'.format(i))有的時候我們需要根據特定的主題來創建特定的文件夾,比如需要根據月份創建12個文件夾。我們前面學過如何創建單個文件夾,要批量創建多個文件夾,只需要遍歷執行單個文件夾的語句即可。具體實現代碼如下:
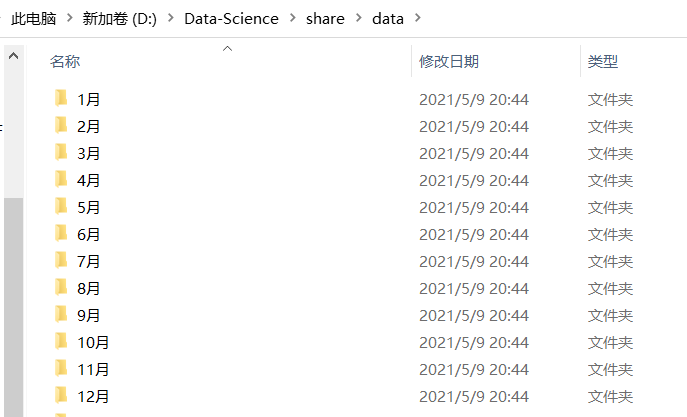
month_num = ['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月']
for i in month_num:
os.mkdir('D:/Data-Science/share/data/' + i)
print('{}創建完成!'.format(i))運行上面代碼以后就會在該文件路徑下新建了12個文件夾:
有的時候我們有好多相同主題的文件,但是這些文件的文件名比較混亂,比如下面這些文件,是各個員工的3月績效情況,但是命名格式都不太一樣,我們要將其統一成名字+3月績效這樣的格式。要達到這種效果,可以通過前面學到的對文件進行重命名操作來實現,前面只講了對單一文件的操作,那如何同時對多個文件進行批量操作呢?
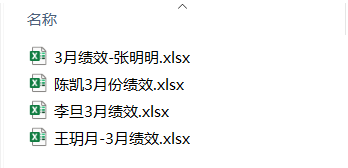
具體實現代碼如下:
import os
#獲取指定文件下所有文件名
old_name = os.listdir('D:/Data-Science/share/data/test')
name = ["張明明","李旦","王玥月","陳凱"]
#遍歷每一個姓名
for n in name:
#遍歷每一個舊文件名
for o in old_name:
#判斷舊文件名中是否包含特定的姓名
#如果包含就進行重命名
if n in o:
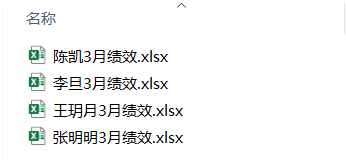
os.rename('D:/Data-Science/share/data/test/' + o, 'D:/Data-Science/share/data/test/' + n +"3月績效.xlsx")運行上面代碼以后可以看到文件下的原文件名全部已被重命名完成。
如下所示,該文件夾下面有1-6月的分月銷售日報,已知這些日報的結構是相同的,只有日期和銷量兩列,現在我們想要把這些不同月份的日報合并成一份。
將分月銷售日報合并成一份文件的具體實現代碼如下:
import os
import pandas as pd
#獲取指定文件下所有文件名
name_list = os.listdir('D:/Data-Science/share/data/sale_data')
#創建一個相同結構的空DataFrame
df_o = pd.DataFrame({'日期':[],'銷量':[]})
#遍歷讀取每一個文件
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/sale_data/' + i)
#進行縱向拼接
df_v = pd.concat([df_o,df])
#把拼接后的結果賦值給df_o
df_o = df_v
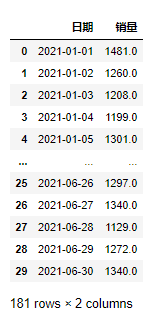
df_o運行上面代碼就會得到合并后的文件df_o,如下所示:
上面講了如何批量合并多個文件,我們也有合并多個文件逆需求,即按照指定列將一個文件拆分成多個文件。
還是上面的數據集,假設我們現在拿到了一份1-6月份的文件,這份文件除了日期和銷量兩列以外,還多了一列月份,現在我們需要做的就是根據月份這一列將這一份文件拆分成多個文件,每個月份單獨存儲為一個文件。
具體實現代碼如下:
#生成一列新的月份列 df_o['月份'] = df_o['日期'].apply(lambda x:x.month) #遍歷每一個月份值 for m in df_o['月份'].unique(): #將特定月份值的數據篩選出來 df_month = df_o[df_o['月份'] == m] #將篩選出來的數據進行保存 df_month.to_csv(r'D:/Data-Science/share/data/split_data/' + str(m) + '月銷售日報_拆分后.csv')
運行上面代碼我們就可以在目標路徑下看到拆分后的多個文件:
看完了這篇文章,相信你對“Python如何批量操作Excel文件”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





