溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python人工智能中波士頓房價數據分析的案例”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python人工智能中波士頓房價數據分析的案例”這篇文章吧。
本次提供:
train.csv,訓練集;
test.csv,測試集;
submission.csv 真實房價文件;
訓練集404行數據,14列,每行數據表示房屋以及房屋周圍的詳細信息,已給出對應的自住房平均房價。要求預測102條測試數據的房價。
通過學習房屋以及房屋周圍的詳細信息,其中包含城鎮犯罪率,一氧化氮濃度,住宅平均房間數,到中心區域的加權距離以及自住房平均房價等等,訓練模型,通過某個地區的房屋以及房屋周圍的詳細信息,預測該地區的自住房平均房價。
回歸問題,提交測試集每條數據對應的自住房平均房價。評估指標為均方誤差mse。
數據集:波士頓房間訓練集.csv (404條數據)
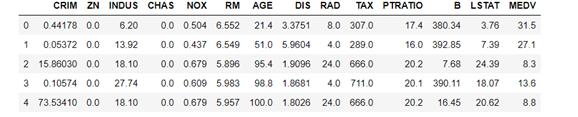
數據集字段如下:
CRIM:城鎮人均犯罪率。
ZN:住宅用地超過 25000 sq.ft. 的比例。
INDUS:城鎮非零售商用土地的比例。
CHAS:查理斯河空變量(如果邊界是河流,則為1;否則為0)。
NOX:一氧化氮濃度。
RM:住宅平均房間數。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士頓五個中心區域的加權距離。
RAD:輻射性公路的接近指數。
TAX:每 10000 美元的全值財產稅率。
PTRATIO:城鎮師生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城鎮中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房價,以千美元計。
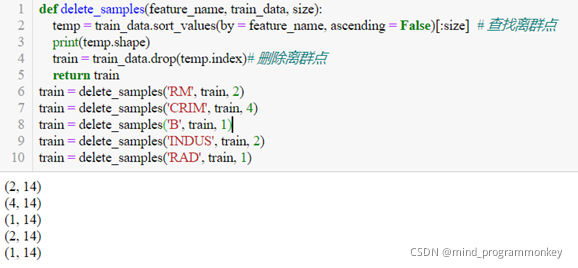
首先對訓練集進行拆分為子訓練集與子測試集,利用train_data.sort_values對訓練集進行排序,依次刪除每個特征對應的離群樣本,利用子訓練集與子測試集對模型進行訓練與測試并確定該特征下所需刪除樣本的最佳個數。
利用sklearn.preprocessing. StandardScaler對數據集與標簽分別進行標準化處理。

利用隨機森林特征選擇算法剔除不敏感特征。

使用GradientBoostingRegressor集成回歸模型。
Gradient Boosting 在迭代的時候選擇梯度下降的方向來保證最后的結果最好。損失函數用來描述模型的“靠譜”程度,假設模型沒有過擬合,損失函數越大,模型的錯誤率越高
如果我們的模型能夠讓損失函數持續的下降,則說明我們的模型在不停的改進,而最好的方式就是讓損失函數在其梯度方向上下降。


采用均方誤差(MSE)評分標準,MSE: Mean Squared Error 。均方誤差是指參數估計值與參數真值之差平方的期望值;
MSE可以評價數據的變化程度,MSE的值越小,說明預測模型描述實驗數據具有更好的精確度。計算公式如下:
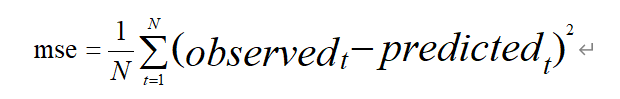
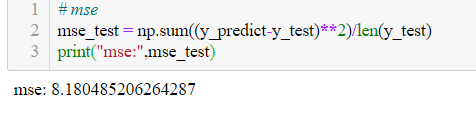
其在測試集上的MSE值為:
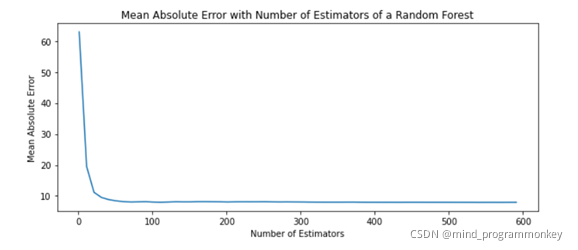
對n_ n_estimators的參數進行調參:
以上是“Python人工智能中波士頓房價數據分析的案例”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





