溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python數據分析的案例,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
前言
對于每個從事和數據科學有關的人來說,前期的數據清洗和探索一定是個花費時間的工作。毫不夸張的說,80%的時間我們都花在了前期的數據工作中,包括清洗、處理、EDA(Exploratory Data Analysis,探索性數據分析)等。前期的工作不僅關乎數據的質量,也關乎最終模型預測效果的好壞。
每當我們手上出現一份新的數據時,我們都需要事先通過人為地觀察、字段釋義等方式預先對數據進行熟悉與理解。在清洗、處理完數據之后才會開始真正的 EDA 過程。
這個過程最通用的操作無非就是對現有的數據做基本性的統計、描述,包括平均值、方差、最大值與最小值、頻數、分位數、分布等。實際上往往都是比較固定且機械的。
在 R 語言中 skimr 包提供了豐富的數據探索性統計信息,比 Pandas 中的 describe() 基本統計信息更為豐富一些。
01-skmir
但在 Python 社區中,我們同樣也可以實現 skmir 的功能,甚至比 skmir 有過之而無不及。那就是使用 pandas-profiling 庫來幫助我們搞定前期的數據探索工作。
通過 pip install pandas-profiling 之后我們就可以直接導入并使用了。我們只需要通過其一行核心代碼 ProfileReport(df, **kwargs) 即可實現:
import pandas as pd
import seaborn as sns
from pandas_profiling import ProfileReport
titanic = sns.load_dataset("Titanic")
ProfileReport(titanic, title = "The EDA of Titanic Dataset")如果我們是在 Jupyter Notebook 中使用,則會在 Jupyter Notebook 中渲染最后直接輸出到單元格中。
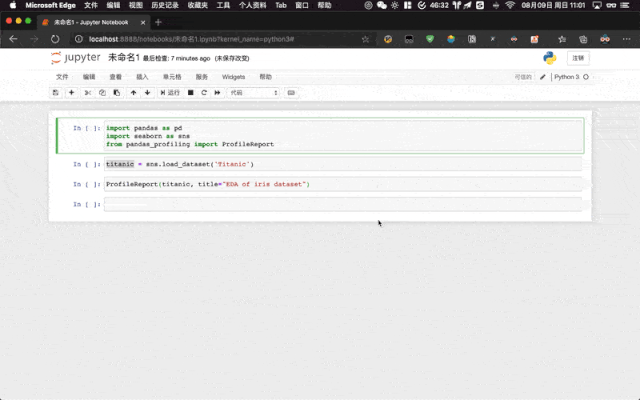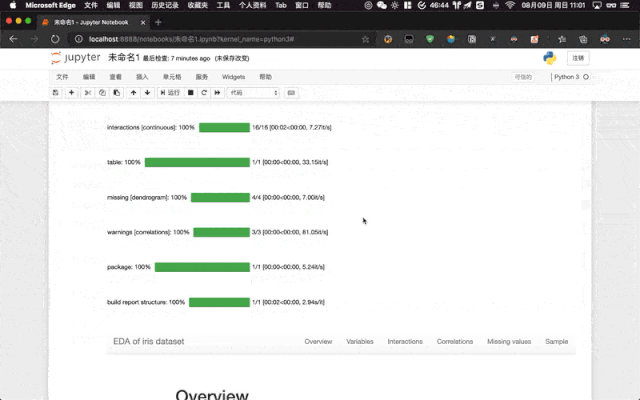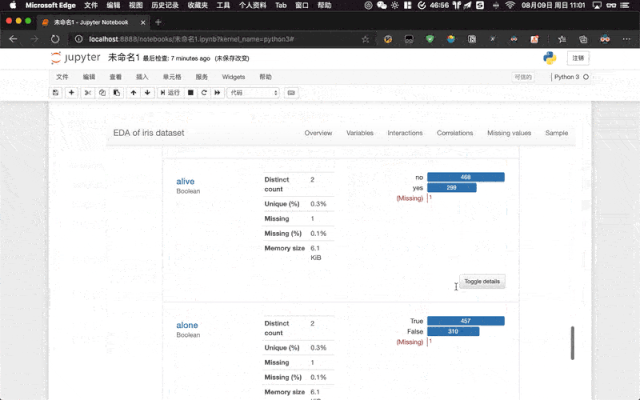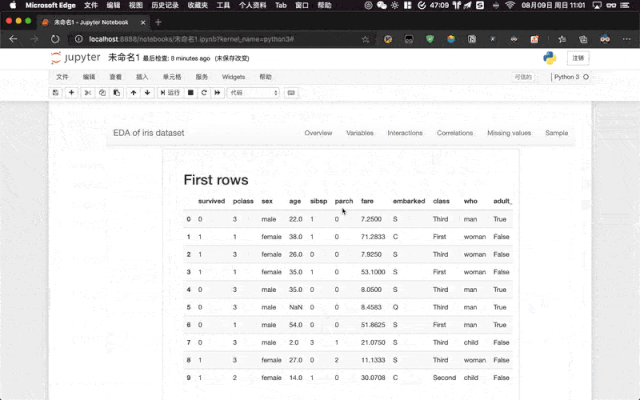
02-profile
pandas-profiling 庫也擴展了 DataFrame 對象方法,這意味著我們也可以通過像調用方法一樣使用 DataFrame.profile_report() 來實現和上述一樣的效果。
無論使用哪種方式,最后都是生成一個 ProfileReport 對象;如果要進一步貼合 Jupyter Notebook,可以直接調用 to_widgets() 和 to_notebook_iframe() 來分別生成掛架或對應的組件,在展示效果上會更加美觀,而不是在輸出欄進行展示。
03-widgets
如果不在 Jupyter Notebook 中直接使用,而是使用其他 IDE,那么我們可以通過 to_file() 方法來直接將報告輸出,需要注意的是最后保存的文件名需要加上擴展名 .html。
另外,Pandas-profiling 還和多個框架、云上平臺等進行了集成,能夠讓我們方便的進行調用,詳情見官網(https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/integrations.html)。
雖然生成的探索性報告基本上已經能滿足我們了解數據的簡單需求,但是當中輸出的信息也有些不足或是冗余。好在 pandas-profiling 也給我們提供了自己定制的可能。這些定制的配置最終會寫入到 yaml 文件中。
在官方文檔中列出了幾個我們能夠進一步調整的部分,分別對應了報告 Tab 欄的各部分標簽:
vars:主要用于調整數據中字段或變量在報告中的呈現的統計指標
missing_diagrams:主要涉及到關于缺失值字段的可視化展示
correlations:顧名思義即調整有關各字段或變量之間相關關系的部分,包括是否計算相關系數、以及相關的閾值等
interactions:主要涉及兩兩字段或變量之前的相關關系圖呈現
samples:分別對應了 Pandas 中 head() 和 tail() 方法,即預覽前后多少條數據
這些部分還有許多可以指定的參數,感興趣的朋友可以直接參考官方文檔https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/pages/advanced_usage.html
于是我們可以直接在代碼中手動寫入并進行調整,就像這樣:
profile_config = {
"progress_bar": False,
"sort": "ascending",
"vars": {
"num": {"chi_squared_threshold": 0.95},
"cat": {"n_obs": 10}
},
"missing_diagrams": {
'heatmap': False,
'dendrogram': False,
}
}
profile = titanic.profile_report(**profile_config)
profile.to_file("titanic-EDA-report.html")將所有配置的信息寫在一個字典變量中,再通過 **variable 的形式將鍵值對進行解包使其能夠根據鍵來對應到相應的參數中。
除了代碼中的配置寫法外,如果你稍微了解一點 yaml 配置文件的寫法,那么我們也無需在代碼中逐個寫入,而是可以通過在 yaml 文件中修改。修改的不僅官方文檔中所列出的配置選項,還能修改未列出的參數。由于配置文件過長,這里我只放出基于官方默認配置文件 config_default.yaml 自己做出修改的部分:
# profile_config.yml vars: num: quantiles: - 0.25 - 0.5 - 0.75 skewness_threshold: 10 low_categorical_threshold: 5 chi_squared_threshold: 0.95 cat: length: True unicode: True cardinality_threshold: 50 n_obs: 5 chi_squared_threshold: 0.95 coerce_str_to_date: False bool: n_obs: 3 file: active: False image: active: False exif: True hash: True sort: "desceding"
修改完 yaml 文件之后,我們只需在生成報告時通過 config_file 參數指定配置文件所在的路徑即可,就像這樣:
df.profile_report(config_file = "你的文件路徑.yml")
通過將配置文件與核心代碼相分離,以提高我們代碼的簡潔性與可讀性。
pandas-profiling 庫為我們提供了一種方便、快捷的數據探索方式,提供了比基本統計信息更為豐富的一些信息(如缺失值相關圖、相關關系圖等),能夠為我們前期的數據探索工作節省出大量的時間。
不過由于 pandas-profiling 生成的報告維度相對來說比較固定和模板化,所以對于想讓報告更加豐富的朋友來說你可能需要自己再去做一些額外的工作了;同時,需要注意的是,pandas-profiling 比較適合在中小數據集中使用。隨著數據量的增加,報告渲染的速度會大幅度變慢且生成報告會耗時更多。
如果你仍有對大數據集進行 EDA 的需要,那么像官方文檔說的那樣你最好是通過抽樣或者采樣的方式來在不影響數據分布的情況下減少樣本量。官方也有表示會在以后的版本中使用 modin、spark 和 dask 等高性能的庫或框架作為可擴展的后端,到那時也許生成大數據集的 EDA 報告時可能就不是問題了。
關于“Python數據分析的案例”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





