溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Hive中的分區就是分目錄,把一個大的數據集根據業務需要分割成更小的數據集。那么在Hive中如何進行數據分區呢?分區時應該注意什么樣的問題呢?它的分區數如何進行限制呢?
一、Hive only:加載分區數據的快捷方法
如果指定的分區不存在Hive將創建新的分區

這個命令將:
(1)如果不存在的話添加分區到表的元數據;
(2)如果存在的話,創建子目錄:/user/hive/warehouse/call_logs/call_date=2014-10-02
(3)移動HDFS文件call-20141002.log到分區子目錄
二、查看、添加和移除分區
(1)查看當前表分區

(2)使用ALTER TABLE添加或刪除分區
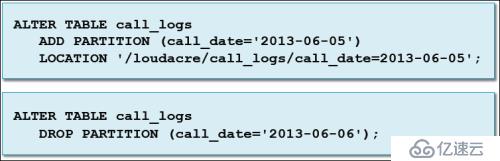
從已存在的分區目錄創建分區
(1)HDFS的分區目錄可以在Hive或Impala之外進行創建和數據,比如:通過Spark或MapReduce應用
(2) Hive中使用MSCK REPAIR TABLE命令來為已存在的表創建分區

四、什么時候使用分區
下列情況使用分區
(1)讀取整個數據集需要花費很長時間
(2)查詢幾乎只對分區字段進行過濾
(3)分區列有合理數量的不同的值
(4)數據生成或ETL過程是按文件或目錄名來分段數據的
(5)分區列值不在數據本身
五、什么時候不使用分區
(1)避免把數據分區到很多小數據文件
–不要對有太多惟一值的列進行分區
(2)注意:當使用動態分區時容易發生
–比如:按照fname來分區客戶表會產生上千個分區
Hive進行分區
在舊的Hive版本中,動態分區默認沒有啟用 ,通過設置這兩個屬性啟用:

但是在hive分區中我們應該注意一些問題,比如:
(1)注意:Beeline設置的Hive變量只在當前會話有效,系統管理員可以設置永久生效
(2)注意:如果分區列有很多唯一值,將會創建很多分區
另外,我們可以給Hive配置參數來限制分區數 :
(1)hive.exec.max.dynamic.partitions.pernode
查詢在某個節點上可以創建的最大動態分區數,默認100
(2)hive.exec.max.dynamic.partitions
一個HiveQL語句可以創建的最大動態分區數 ,默認1000
(3)hive.exec.max.created.files
一個查詢總共可以創建的最大動態分區數,默認1000000
以上就是對Hive中進行數據分區做的分享。平時要多去掌握和了解,它對于大數據學習有著至關重要的作用。這里推薦“大數據cn”微信訂閱號,對于大數據的一些介紹還不錯,可以關注一下。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





