溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
進行數據分區將會極大的提高數據查詢的效率,尤其是對于當下大數據的運用,是一門不可或缺的知識。那么數據怎么創建分區呢?數據怎樣加載到分區呢?
Impala/Hive按State分區Accounts
(1)示例:accounts是非分區表

通過以上方式創建的話,數據就存放在accounts目錄里面。那么,如果Loudacre大部分對customer表的分析是按state來完成的?比如:

這種情況下如果數據量很大,為了避免全表掃描的發生,我們可以去創建分區。如果不創建分區的話,它會默認所有查詢不得不掃描目錄的所有文件。創建分區按state將數據存儲到不同的子目錄,當按照“NY”的條件進行查詢的時候,它只會掃描到子目錄,下面我具體來看一下分區創建。
二、分區創建
(1)使用PARTITIONED BY來創建分區表
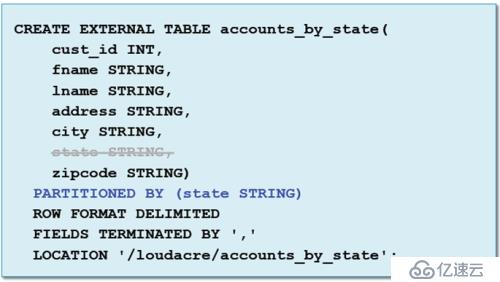
在這里注意state是被刪除掉的,因為它作為分區字段,我們知道分區數據是不會出現在實際的文件當中的,所以state作為分區字段是不會出現在列當中的。換句話說,分區鍵就是一個虛列,它是不會存在列當中的。那么,如何去查看我們分區的列呢?它會出現在我們的結構當中嗎?會的。
三、查看分區列
使用DESCRIBE顯示分區列,它會出現在結構最后一列,它是一個虛列,并不是真實在數據中存在的列。

我們創建單個分區,但有時候會有嵌套分區,如何來處理呢?
四、創建嵌套分區:
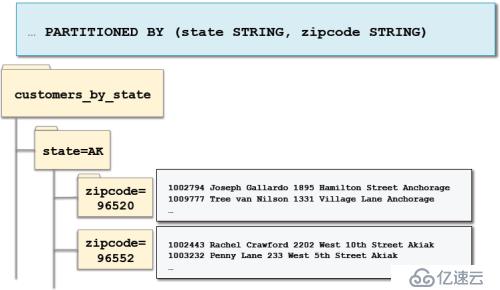
創建好了分區,我們怎么加載數據到分區呢?有兩種方式動態分區和靜態分區。動態分區是指Impala/Hive在加載的時候自動添加新的分區,數據基于列值存儲到正確的分區(子目錄)。而靜態分區需要我們通過ADD PARTITION提前去定義分區的名稱,當加載數據的時候,指定存儲數據到哪個分區。那么動態分區和靜態分區各有什么特征呢?后續為大家接著分享。
對于大數據,我們應該積極主動的去迎合和學習,因為它沒有成熟的體系,還在發展上升,只有不斷學習提升才可以趕上發展的步伐。建議在平時大家多學習交流,我在平常喜歡關注“大數據cn”這個微信公眾號,對于我個人而言,很不錯,推薦圍觀。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





