溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Parquet是面向分析型業務的列式存儲格式,由Twitter和Cloudera合作開發,2015年5月從Apache的孵化器里畢業成為Apache頂級項目
http://parquet.apache.org/
這里我們使用的版本為spark2.0.1,是2016年10月3日發布的最新版本。
Spark可以很好的使用和生成Parquet 文件。下面的截圖來自官方文檔。
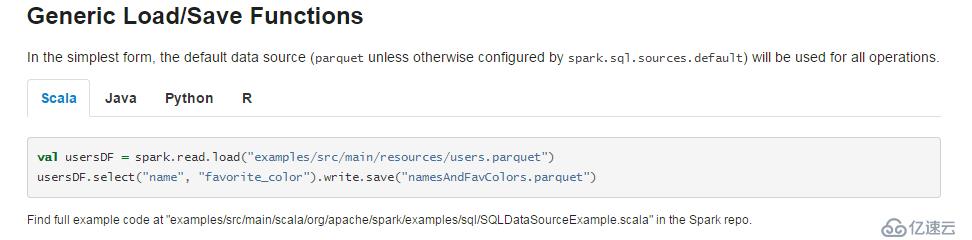
上圖的例子中spark讀取了一個位于examples/src/main/resources/users.parquet文件夾下的Parquet文件,并對數據進行了篩選后保存在了namesAndFavColors.parquet文件夾中,注意一下,官方文檔路徑取名加了.parquet,可能會被誤解成是一個文件,其實是文件夾,這里自己試一下就可以證實。
Spark也支持將jdbc的數據轉換成Parquet文件,下面的例子我們將SQLserver中的測試表1轉換成Parquet文件。代碼如下

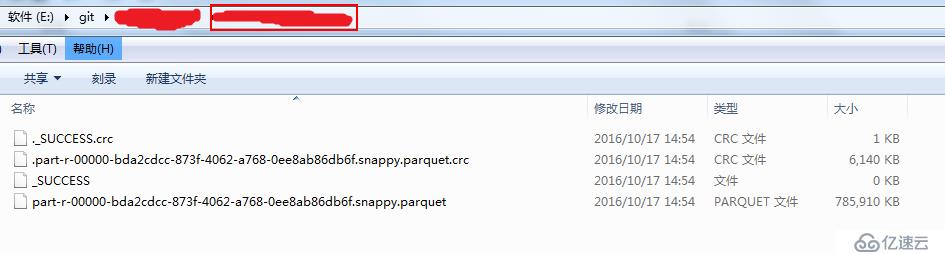
生成好了的文件如下圖所示,這里的實驗環境為Windows,spark local模式,可以看到,文件名格式為*.snappy.parquet,這里的snappy表示的是壓縮的方式,當然,這個壓縮方式也是有很多種選擇的,不過spark在這里選擇了用snappy的壓縮方式壓縮成parquet文件作為默認策略。
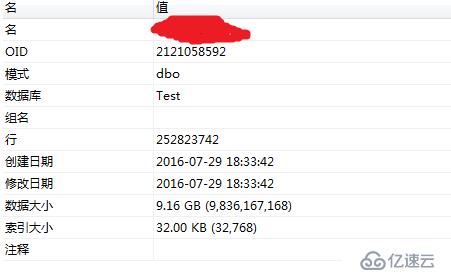
我們看下測試表1在SQLserver中的信息,如下圖所示:

可以看到這是一張7000w級別的表,表大小為6.5G,壓縮過后的大小為768M,壓縮后的大小為原文件大小的11%,節約了89%的空間。整個壓縮時間耗時約11min,對于大數據平臺來說,存儲空間也是很重要的資源,而且對于網絡傳輸有很大提升,在分布式計算中,網絡傳輸有時會成為性能瓶頸。
我們再用另外一張測試表2做實驗
這是一張2.5億級別的表,表大小為9G,壓縮后的大小為3.99G,節約了56%的空間,耗時約17min這是因為列存儲格式文件大小不僅和行數有關,也和具體數據有關,不同的數據會有不同的壓縮率。
Spark Sql支持直接在sql語句中讀取Parquet文件,如下圖所示
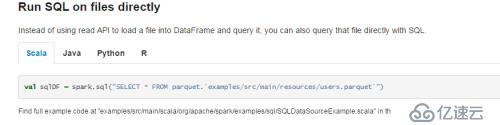
注意,這個語法是spark2.0開始才支持的新特性,利用這個特性,我們可以跳過建表這個過程直接讀取文件的數據。
下面我們介紹一下性能。
我們使用三個場景來測試Parquet的性能,這里我們并沒有直接去取parquet文件,而是用createOrReplaceTempView方法將其創建為一個view。測試結果如下。
SELECT YEAR(LOGOUT_DT) YR , MONTH(LOGOUT_DT) MTH,Modename,sum(WinCount+LoseCount+DrawCount) GameCount,sum(GameTime) GameTime,sum(GameTime) / sum(WinCount+LoseCount+DrawCount) Avg_GameTime FROM 測試表1 WHERE LOGOUT_DT BETWEEN '2015-01-01' AND '2016-01-01' GROUP BY YEAR(LOGOUT_DT) ,MONTH(LOGOUT_DT) ,Modename limit 1000;
我們再看一下一個對比試驗:
Phoenix(poc環境,10臺阿里云,集群環境) | 110s |
spark local(8G,4核,i3-4170,單機模式) | 52s |
spark 3node(8G,4核,i3-4170,集群環境) | 12s |
spark 5node (8G,4核,i3-4170,集群環境) | 12s |
hive 普通存儲5node (8G,4核,i3-4170,集群環境) | 133s |
hive 列存儲5node(parquet)(8G,4核,i3-4170,集群環境) | 43s |
Parquet不僅可以提高spark的查詢速度,也可以提高hive的查詢速度
集群的計算速度大于單機的計算速度(機器配置相同)
增加計算節點不一定會提高計算速度
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





