溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行基于spark之上的卓越性能分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
為探索性分析與即席分析而設計
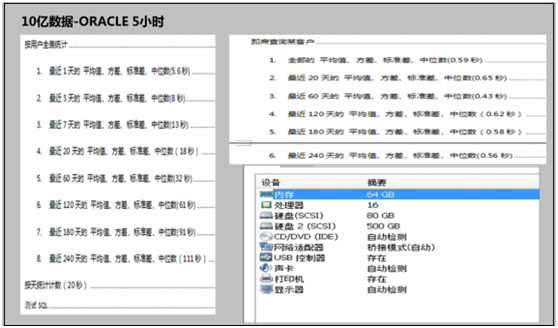
YDB全稱延云YDB:是一個基于Hadoop分布式架構下的實時的、多維的、交互式的查詢、統計、分析引擎,具有萬億數據規模下的秒級性能表現,并具備企業級的穩定可靠表現。
YDB是一個細粒度的索引:精確粒度的索引。數據即時導入,索引即時生成,通過索引高效定位到相關數據。YDB與Spark深度集成,Spark直接對YDB檢索結果集分析計算,同樣場景讓Spark性能加快百倍。

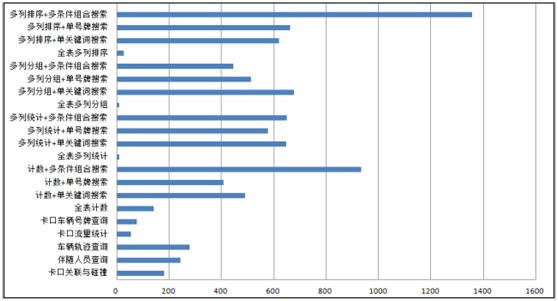
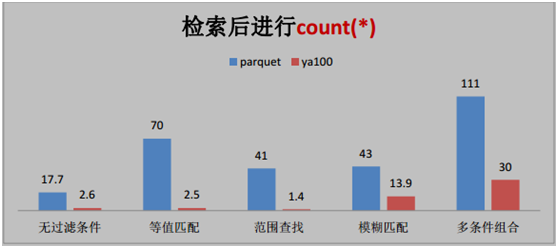
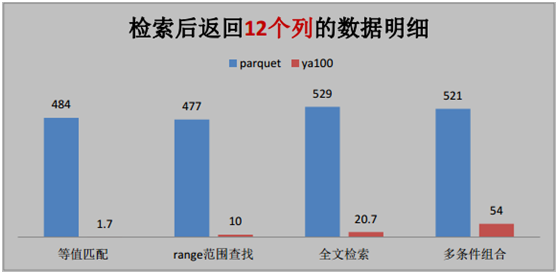
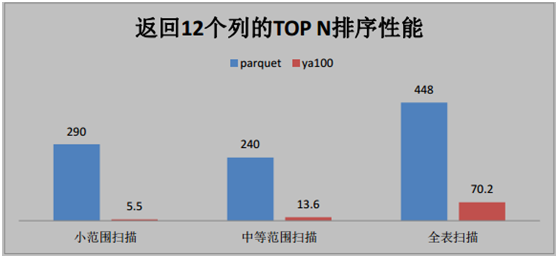
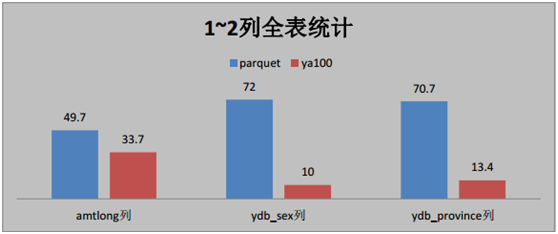
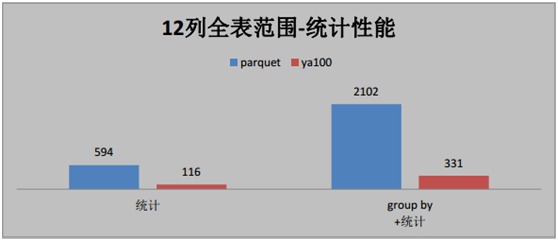
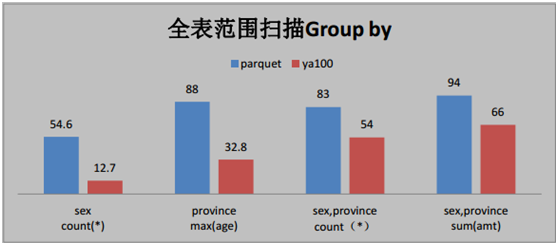
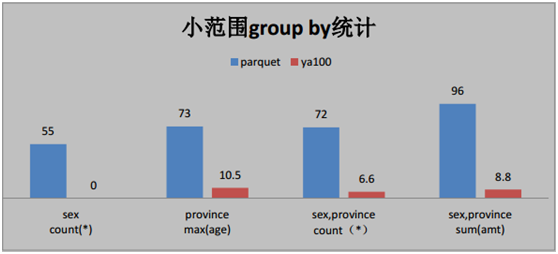
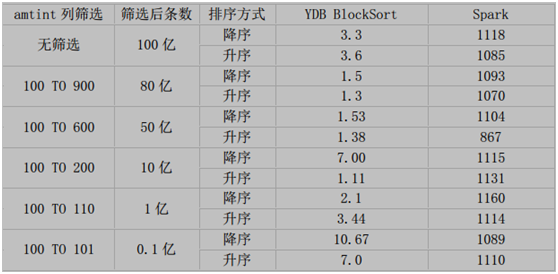
按照時間逆序排序可以說是很多日志系統的硬指標。在延云 YDB 系統中,我們改變了傳統的暴力排序方式,通過索引技術,可以超快對數據進行單列排序,不需要全表暴力掃描,這個技術我們稱之為 BlockSort,目前支持 tlong、 tdouble、 tint、 tfloat 四種數據類型。
由于 BlockSort 是借助搜索的索引來實現的,所以采用 BlockSort 的排序,不需要暴力掃描,性能有大幅度的提升。
BlockSort 的排序,并非是預計算的方式,可以進行全表進行排序,也可以基于任意的過濾篩選條件進行過濾排序。
詳細測試地址: http://blog.csdn.net/qq_33160722/article/details/54447022
300億條數據的排序演示視頻 http://blog.csdn.net/qq_33160722/article/details/54834896
看完上述內容,你們掌握如何進行基于spark之上的卓越性能分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





