溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark 于 2009 年誕生于加州大學伯克利分校 AMPLab,2013 年被捐贈給 Apache 軟件基金會,2014 年 2 月成為 Apache 的頂級項目。相對于 MapReduce 的批處理計算,Spark 可以帶來上百倍的性能提升,因此它成為繼 MapReduce 之后,最為廣泛使用的分布式計算框架。
Apache Spark 具有以下特點:
| Term(術語) | Meaning(含義) |
|---|---|
| Application | Spark 應用程序,由集群上的一個 Driver 節點和多個 Executor 節點組成。 |
| Driver program | 主運用程序,該進程運行應用的 main() 方法并且創建 SparkContext |
| Cluster manager | 集群資源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 執行計算任務的工作節點 |
| Executor | 位于工作節點上的應用進程,負責執行計算任務并且將輸出數據保存到內存或者磁盤中 |
| Task | 被發送到 Executor 中的工作單元 |

執行過程:
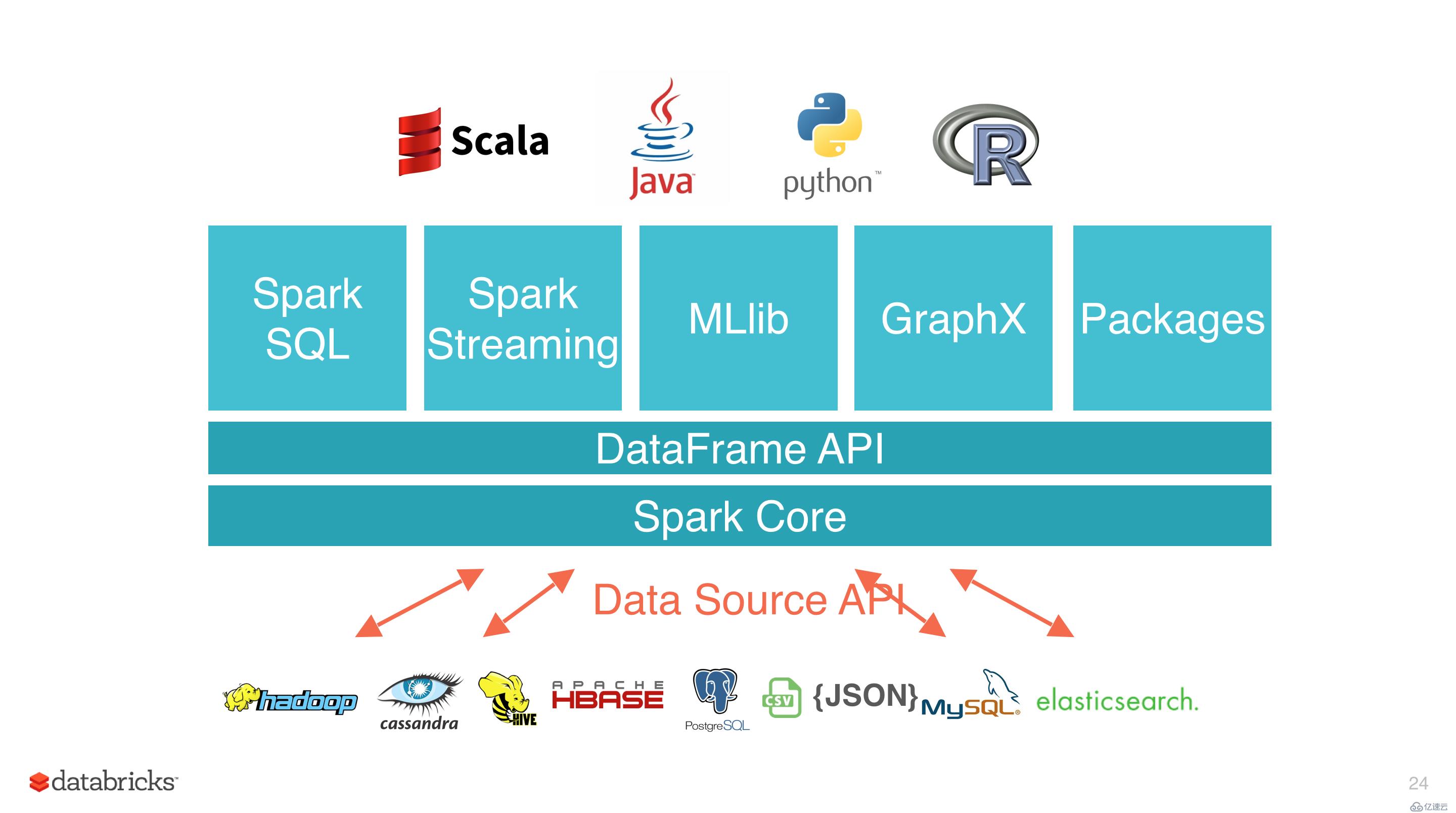
Spark 基于 Spark Core 擴展了四個核心組件,分別用于滿足不同領域的計算需求。

Spark SQL 主要用于結構化數據的處理。其具有以下特點:
Spark Streaming 主要用于快速構建可擴展,高吞吐量,高容錯的流處理程序。支持從 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 讀取數據,并進行處理。

Spark Streaming 的本質是微批處理,它將數據流進行極小粒度的拆分,拆分為多個批處理,從而達到接近于流處理的效果。
MLlib 是 Spark 的機器學習庫。其設計目標是使得機器學習變得簡單且可擴展。它提供了以下工具:
GraphX 是 Spark 中用于圖形計算和圖形并行計算的新組件。在高層次上,GraphX 通過引入一個新的圖形抽象來擴展 RDD(一種具有附加到每個頂點和邊緣的屬性的定向多重圖形)。為了支持圖計算,GraphX 提供了一組基本運算符(如: subgraph,joinVertices 和 aggregateMessages)以及優化后的 Pregel API。此外,GraphX 還包括越來越多的圖形算法和構建器,以簡化圖形分析任務。
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





