溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關C語言自定義類型的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
當我們想要描述一個復雜變量——學生,可以這樣聲明。
??代碼展示:
struct Stu
{
char name[20];//名字
int age;//年齡
char sex[5];//性別
char id[20];//學號
}s1;//分號不能丟
int main()
{
struct Stu s2;
return 0;
}?解釋說明:
struct是結構體的關鍵字
Stu是結構體標簽名
struct Stu是結構體的類型
大括號內包圍的是結構體成員變量的列表
變量s1是類型為struct Stu的全局變量,變量s2是該類型的局部變量
在聲明結構時,也有特殊的聲明,比如不完全聲明——匿名結構體類型,省略掉了結構體標簽。
??代碼展示:
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], *p;那么,此時,問題來了!
在上面的代碼基礎上,p = &x,這樣的代碼合理嗎?

而且,像這樣的匿名結構體類型只能使用一次,因為沒有標簽名。
眾所周知,函數可以自己調用自己,叫做函數的遞歸,那么結構體是否也有自己引用自己呢?如果有又是如何實現的呢?
??代碼展示:
//代碼一:
struct N
{
int data;
struct N next;
};
//代碼二:
struct Node
{
int data;
struct Node* next;
};
//代碼三:
typedef struct
{
int data;
Node* next;
}Node;
//代碼四:
typedef struct Node
{
int data;
struct Node* next;
}Node;?解釋說明:
代碼一:
這樣自引用是不正確的。當想要計算struct N類型所占空間大小時,就會出現瘋狂套娃現象,無法計算結果,因此是不可取的
代碼二:
這才是自引用的正確打開方式。data中存放的數據,next中存放著下一個struct Node類型數據的地址
代碼三:
該代碼想要實現匿名結構體的自引用,但這樣做是不可取的。因為需要完整的定義了該結構體才可以重新命名為Node。然而定義的成員列表中又有Node*,先后問題產生了。
代碼四:
可以通過這種重定義方式實現自引用。
既然已經有了結構體類型,那么對其定義和初始化就變得非常的簡單
??代碼展示:
struct Point
{
int x;
int y;
}p1; //聲明類型的同時定義變量p1
struct Point p2; //定義結構體變量p2
//初始化:定義變量的同時賦初值。
struct Point p3 = {x, y};
struct Stu //類型聲明
{
char name[15];//名字
int age; //年齡
};
struct Stu s = {"zhangsan", 20};//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = {10, {4,5}, NULL}; //結構體嵌套初始化
struct Node n2 = {20, {5, 6}, NULL};//結構體嵌套初始化掌握了結構體的基本使用,還應當重點了解結構體內存對齊問題從而計算結構體的大小,這是一個關于結構體的重點考點

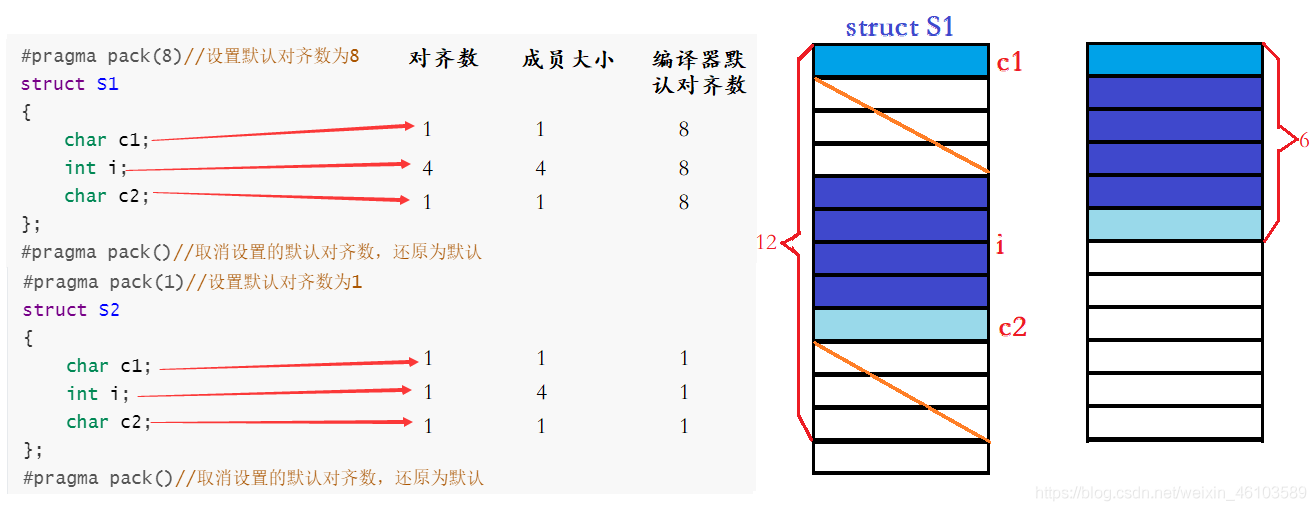
結構體的對齊規則:
第一個成員在與結構體變量偏移量為0的地址處。
其他成員變量需要對齊到對齊數的整數倍的地址處。
對齊數 = 編譯器默認的一個對齊數與該成員大小的較小值。
VS中默認的值為8,Linux沒有默認對齊數結構體總大小為最大對齊數的整數倍。
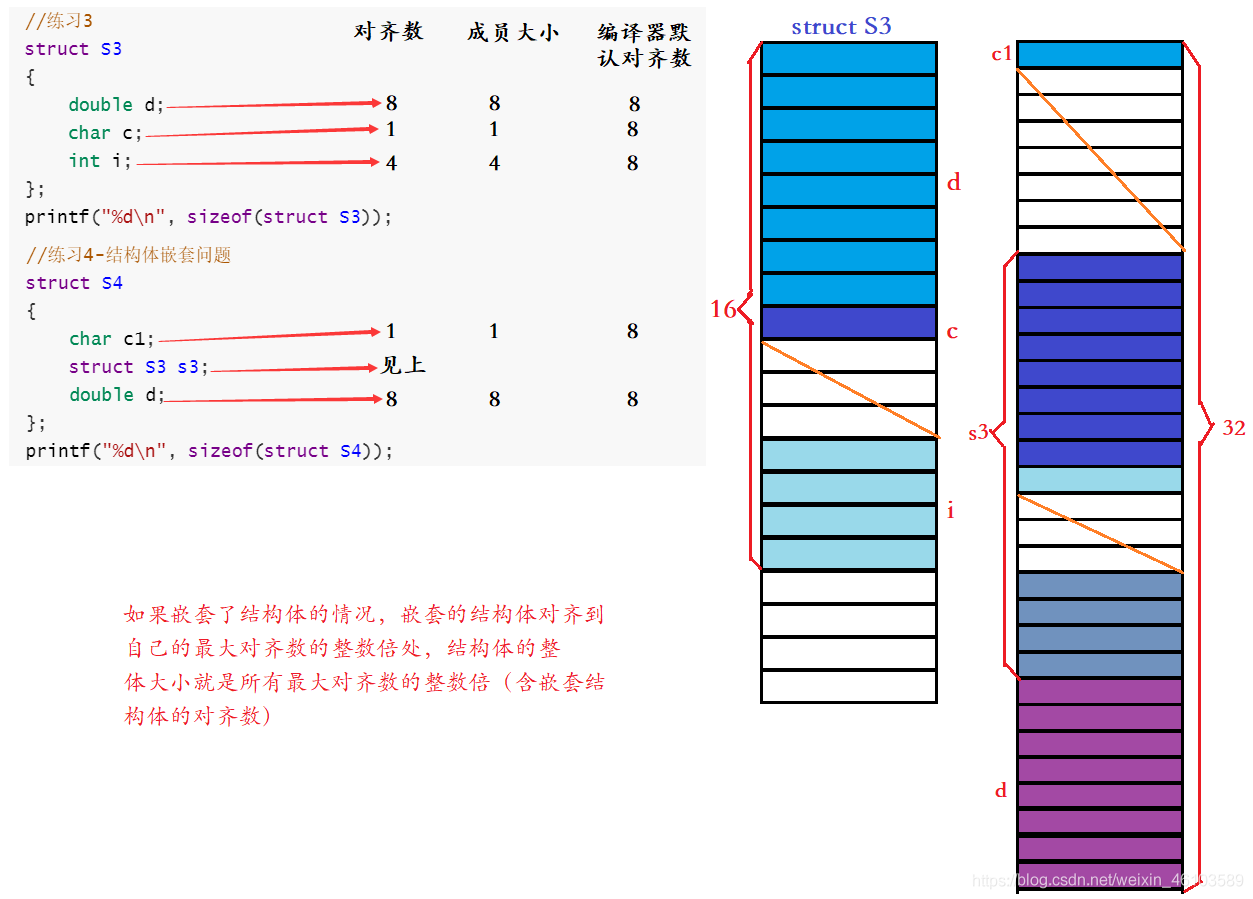
當嵌套結構體時,嵌套的結構體對齊需要到自己的最大對齊數的整數倍處,結構體的整體大小就是所有最大對齊數的整數倍(包含嵌套結構體的對齊數)。
??代碼展示:
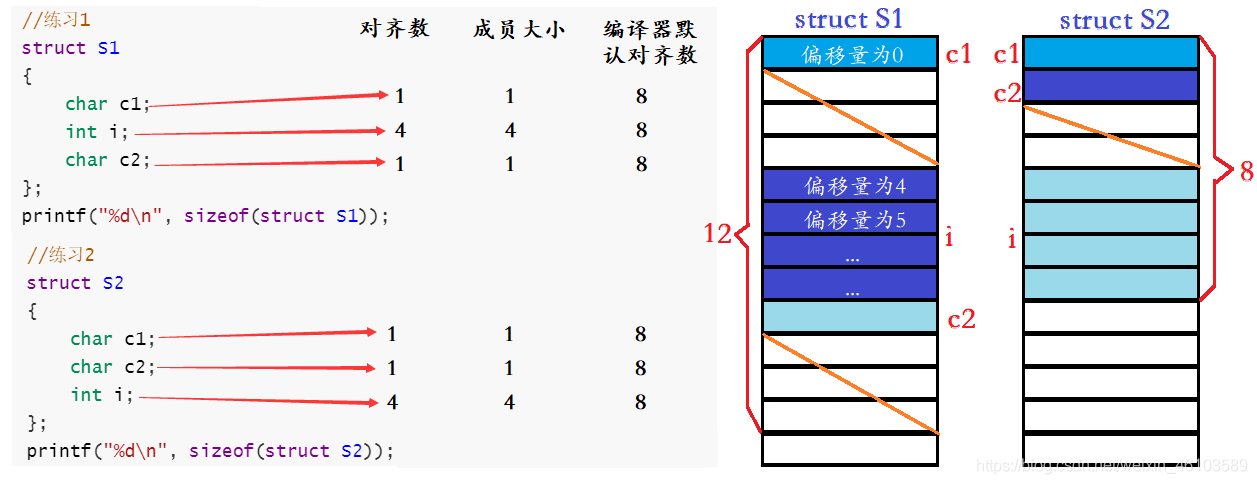
//練習1
struct S1
{
char c1;
int i;
char c2;
};
printf("%d\n", sizeof(struct S1));
//練習2
struct S2
{
char c1;
char c2;
int i;
};
printf("%d\n", sizeof(struct S2));
//練習3
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));
//練習4-結構體嵌套問題
struct S4
{
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));?效果展示:
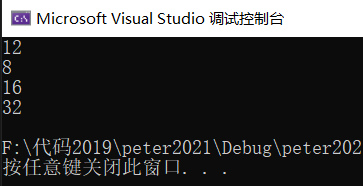
?解釋說明:
結構體類型struct S1和struct S2兩者的成員組成是一樣的,但是定義順序有所差別,后者與前者相比將占用空間小的變量集中在了一起,導致兩者在遵循結構體對齊條件下,所占內存大小不一樣。做個對比吧!
結構體類型struct S3和struct S4是另外兩個典型例子,后者嵌套前者。
簡而言之,該做法就是為了拿空間換取時間
如果。。。

另外。。。
結構在對齊方式不合適的時候,我么可以自己更改默認對齊數。
這里我們將使用預處理指令#pragma來改變默認對齊數
??代碼展示:
#include <stdio.h>
#pragma pack(8)//設置默認對齊數為8
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消設置的默認對齊數,還原為默認
#pragma pack(1)//設置默認對齊數為1
struct S2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消設置的默認對齊數,還原為默認
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}?效果展示:
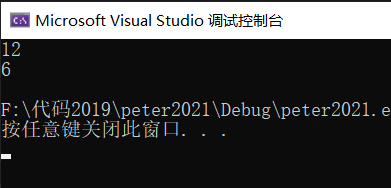
?解釋說明:
??代碼展示:
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//結構體傳參
void print1(struct S s)
{
printf("%d\n", s.num);
}
//結構體地址傳參
void print2(struct S* ps)
{
printf("%d\n", ps->data[2]);
}
int main()
{
print1(s); //傳結構體
print2(&s); //傳地址
return 0;
}?效果展示:
?解釋說明:
函數傳參的時候,參數是需要壓棧,會有時間和空間上的系統開銷。
如果傳遞一個結構體對象的時候,結構體過大,參數壓棧的的系統開銷比較大,導致性能的下降。比如在這里,如果直接傳值s的話,由于結構體中創建了一個很大的數組data,導致結構體過大,傳參時浪費的內存空間很大,效率低下。但是如果傳址&s的話,作為一個指針,占四個字節,極大提高了運行效率。
簡而言之,結構體傳參時,傳結構體的地址更好
位段,C語言允許在一個結構體中以位為單位來指定其成員所占內存長度,這種以位為單位的成員稱為“位段”或稱“位域” 。利用位段能夠用較少的位數存儲數據。
位段的聲明和結構是類似的,有兩個不同:
位段的成員必須是 int、unsigned int 、signed int、char 。
位段的成員名后邊有一個冒號和一個數字(指該成員占的比特位)。
??代碼展示:
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};位段的內存分配規則:
位段的成員可以是 int、unsigned int、signed int或者char (屬于整形家族)類型
位段的空間上是按照需要以==4個字節( int )或者1個字節( char )==的方式來開辟的。
位段涉及很多不確定因素,位段是不跨平臺的,注重可移植的程序應該避免使用位段。
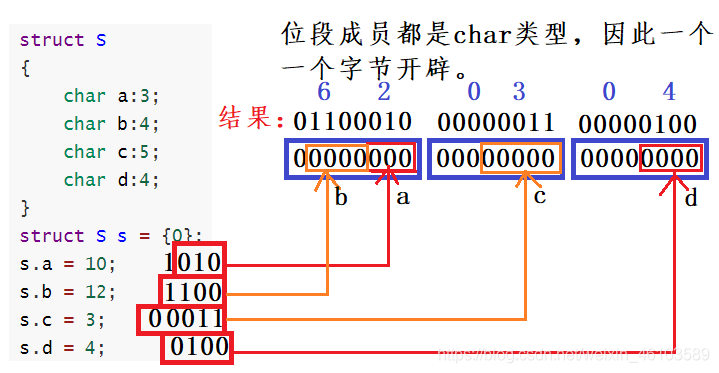
??代碼展示:
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
}
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;?解釋說明:
在VS編譯器中開辟了空間以后,先使用低地址再使用高地址。并且剩余的比特位不夠下一個變量存儲時,那這一片空間將會被浪費。
簡而言之,跟結構相比,位段可以達到同樣的效果,但是可以很好的節省空間,但是有跨平臺的問題存在。
?解釋說明:
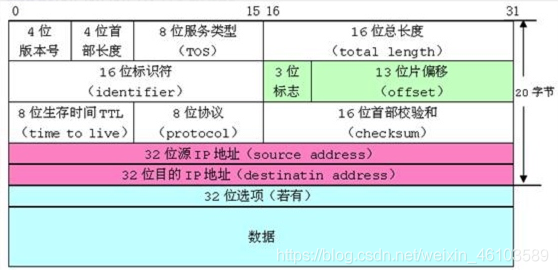
上圖是網絡上IP數據包的格式,當你想要在網絡上發一條消息給你的好友,信息是需要進行分裝的,消息作為數據只是傳輸的一部分,還有一部分傳輸的是分裝中的其他信息。比如4位版本號,4位首部長度,這些信息只需要4個bit,如若不使用位段,直接每個部分一個整形的給空間,就會造成空間的大量浪費。
在數學和計算機科學理論中,一個集的枚舉是列出某些有窮序列集的所有成員的程序,或者是一種特定類型對象的計數。這兩種類型經常(但不總是)重疊。枚舉在日常生活中很常見,例如表示星期的SUNDAY、MONDAY、TUESDAY、WEDNESDAY、THURSDAY、FRIDAY、SATURDAY就是一個枚舉。
枚舉的優點:
代碼的可讀性變高和可維護性變強
和#define定義的標識符相比較枚舉更加嚴謹,因為有類型檢查。
防止命名污染的現象
方便調試,且使用方便,可以一下子定義很多常量
枚舉的說明與結構和聯合相似, 其形式為:
enum 枚舉名
{
標識符[=整型常數],
標識符[=整型常數],
...
標識符[=整型常數]
} 枚舉變量;如果枚舉沒有初始化,即省掉"=整型常數"時, 則從第一個標識符開始,順次賦給標識符0, 1, 2, …但當枚舉中的某個成員賦值后,其后的成員按依次加1的規則確定其值。
??代碼展示:
//代碼1
enum Num1
{
x1,
x2,
x3,
x4
}x;
//代碼2
enum Num2
{
y1,
y2 = 0,
y3 = 50,
y4
};
int main()
{
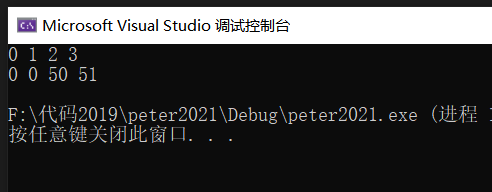
printf("%d %d %d %d\n", x1, x2, x3, x4);
printf("%d %d %d %d\n", y1, y2, y3, y4);
return 0;
}?效果展示:
注意:
枚舉中每個成員(標識符)結束符是==","== 不是";", 最后一個成員可省略","。
初始化時可以賦負數, 以后的標識符仍依次加1。
枚舉變量只能取枚舉說明結構中的某個標識符常量。
枚舉值是常量,不是變量,不能在程序中用賦值語句再對它賦值(比如上面的代碼出現y3 = 3; ?)。
只能把枚舉值賦予枚舉變量,不能把元素的數值直接賦予枚舉變量,除非進行了強制類型轉換(比如上面的代碼出現x = x2?? x = 1?x = (enum Num1)1??)
需要使幾種不同類型的變量存放到同一段內存單元中。也就是使用覆蓋技術,幾個變量互相覆蓋。這種幾個不同的變量共同占用一段內存的結構,在C語言中,被稱作“共用體”類型結構,簡稱共用體,也叫聯合體。
聯合的成員是共用同一塊內存空間的,一個聯合變量的大小,至少是最大成員的大小(因為聯合至少得有能力保存最大的那個成員)
??代碼展示:
//聯合類型的聲明
union Un
{
char c;
int i;
};
//聯合變量的定義
union Un un;
int main()
{
//例①
printf("%p\n", &(un.i));
printf("%p\n", &(un.c));
//例②
un.i = 0x11223344;
un.c = 0x55;
printf("%x\n", un.i);
return 0;
}?效果展示:
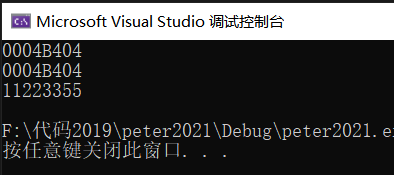
?解釋說明:
通過例①的結果,我們可以直觀發現成員變量c和成員變量i共用地址
例②更加證實這一點,由于大小端存儲,變量i是以44 33 22 11這樣的順序存儲的,因為變量c與其公用地址,因此55將44覆蓋,在內存中變量i為55 33 22 11,打印出來為11 22 33 55
聯合體的相關應用:
在之前我們已經學會了判斷計算機大小端的方法,這里可以通過共用體的特點來實現
#include <stdio.h>union Un{ char c; int i;}num;int main(){ num.i = 1; if(num.c == 1) { printf("小端存儲") } else { printf("大端存儲") } return 0;}向成員變量i中存放一個1,查看成員變量c的值,由于該變量是char類型,因此只訪問了第一個字節。
聯合體大小計算規則:
聯合的大小至少是最大成員的大小。當最大成員大小不是最大對齊數的整數倍的時候,就要對齊到最大對齊數的整數倍。
??代碼展示:
#include <stdio.h>
union Un
{
char c;
int i;
}num;
int main()
{
num.i = 1;
if(num.c == 1)
{
printf("小端存儲")
}
else
{
printf("大端存儲")
}
return 0;
}?效果展示:
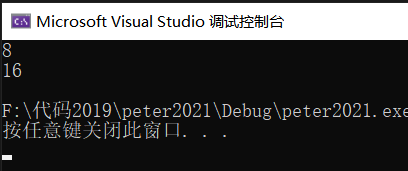
關于“C語言自定義類型的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





