溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“pandas實現按行選擇的方法”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1.自定義行索引
2. 按普通索引選擇數據
2.1 按普通索引選擇單行數據
2.2 按行索引選擇多行數據
3.按位置索引選擇數據
3.2 按位置索引選擇多行數據
4.選擇連續多行數據
5.選擇滿足條件的行
5.1單個條件選擇
5.2 多個條件選擇
5.2.1 多個條件是且的關系
5.2.2 多個條件是或的關系
本文所用到的Excel表格內容如下:
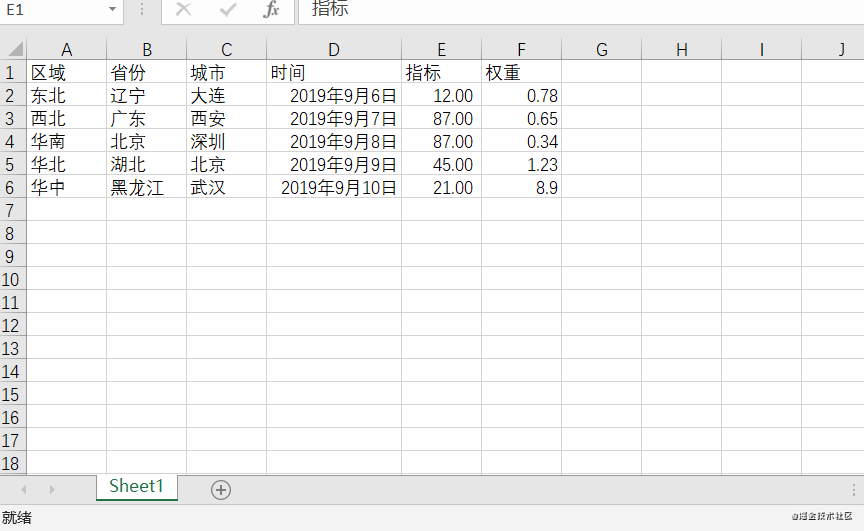
dataframe讀取Excel表格時是由自定義行索引的。這里為了展示效果,先進行自定義行索引的操作
import pandas as pd
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
print('設置索引前:')
print(df)
print('設置索引后:')
df.index = ['一', '二', '三', '四', '五']
print(df)result:
設置索引前:
區域 省份 城市 時間 指標 地址 權重 字符
0 東北 遼寧 大連 2019-09-06 12 “123“ 0.78 u"123"
1 西北 廣東 西安 2019-09-07 87 “124“ 0.65 u"124"
2 華南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
3 華北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
4 華中 黑龍江 武漢 2019-09-10 21 “127“ 8.90 u"127"
設置索引后:
區域 省份 城市 時間 指標 地址 權重 字符
一 東北 遼寧 大連 2019-09-06 12 “123“ 0.78 u"123"
二 西北 廣東 西安 2019-09-07 87 “124“ 0.65 u"124"
三 華南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
四 華北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
五 華中 黑龍江 武漢 2019-09-10 21 “127“ 8.90 u"127"
這里說一下,行普通索引實際上就是行名。為了行文方便,后續一律稱普通索引。
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') df.index = ['一', '二', '三', '四', '五'] print(df.loc['一'])
result:
區域 東北
省份 遼寧
城市 大連
時間 2019-09-06 00:00:00
指標 12
地址 “123“
權重 0.78
字符 u"123"
Name: 一, dtype: object
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') df.index = ['一', '二', '三', '四', '五'] print(df.loc[['一', '三', '四']])
result:
區域 省份 城市 時間 指標 地址 權重 字符
一 東北 遼寧 大連 2019-09-06 12 “123“ 0.78 u"123"
三 華南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
四 華北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
注:選擇單列數據是參數為字符串類型,多列數據時參數為列表類型
3.1 按位置索引選擇單行數據
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') df.index = ['一', '二', '三', '四', '五'] print(df.iloc[0])
result:
區域 東北
省份 遼寧
城市 大連
時間 2019-09-06 00:00:00
指標 12
地址 “123“
權重 0.78
字符 u"123"
Name: 一, dtype: object
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') df.index = ['一', '二', '三', '四', '五'] print(df.iloc[[0, 1]])
result:
區域 省份 城市 時間 指標 地址 權重 字符
一 東北 遼寧 大連 2019-09-06 12 “123“ 0.78 u"123"
二 西北 廣東 西安 2019-09-07 87 “124“ 0.65 u"124"
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') df.index = ['一', '二', '三', '四', '五'] print(df.iloc[0:2])
result:
區域 省份 城市 時間 指標 地址 權重 字符
一 東北 遼寧 大連 2019-09-06 12 “123“ 0.78 u"123"
二 西北 廣東 西安 2019-09-07 87 “124“ 0.65 u"124"
表示獲取所有行第1列到第3列的數據。選擇連續多列數據時語法類似于切片語法,所以也稱之為切片索引。
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') print(df[df['指標'] < 50])
result:
區域 省份 城市 時間 指標 權重
0 東北 遼寧 大連 2019-09-06 12 0.78
3 華北 湖北 北京 2019-09-09 45 1.23
4 華中 黑龍江 武漢 2019-09-10 21 8.90
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') print(df[(df['指標'] < 50) & (df['權重'] < 1)])
result:
區域 省份 城市 時間 指標 權重
0 東北 遼寧 大連 2019-09-06 12 0.78
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx') print(df[(df['指標'] < 50) | (df['權重'] < 1)])
result:
區域 省份 城市 時間 指標 權重
0 東北 遼寧 大連 2019-09-06 12 0.78
1 西北 廣東 西安 2019-09-07 87 0.65
2 華南 北京 深圳 2019-09-08 87 0.34
3 華北 湖北 北京 2019-09-09 45 1.23
4 華中 黑龍江 武漢 2019-09-10 21 8.90
“pandas實現按行選擇的方法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





