溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了SOFAJRaft | SOFAChannel#8 的示例分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Raft 是一種共識算法,其特點是讓多個參與者針對某一件事達成完全一致:一件事,一個結論。同時對已達成一致的結論,是不可推翻的。可以舉一個銀行賬戶的例子來解釋共識算法:假如由一批服務器組成一個集群來維護銀行賬戶系統,如果有一個 Client 向集群發出“存 100 元”的指令,那么當集群返回成功應答之后,Client 再向集群發起查詢時,一定能夠查到被存儲成功的這 100 元錢,就算有機器出現不可用情況,這 100 元的賬也不可篡改。這就是共識算法要達到的效果。
Raft 算法和其他的共識算法相比,又有了如下幾個不同的特性:
Strong leader:Raft 集群中最多只能有一個 Leader,日志只能從 Leader 復制到 Follower 上;
Leader election:Raft 算法采用隨機選舉超時時間觸發選舉來避免選票被瓜分的情況,保證選舉的順利完成;
Membership changes:通過兩階段的方式應對集群內成員的加入或者退出情況,在此期間并不影響集群對外的服務;
共識算法有一個很典型的應用場景就是復制狀態機。Client 向復制狀態機發送一系列能夠在狀態機上執行的命令,共識算法負責將這些命令以 Log 的形式復制給其他的狀態機,這樣不同的狀態機只要按照完全一樣的順序來執行這些命令,就能得到一樣的輸出結果。所以這就需要利用共識算法保證被復制日志的內容和順序一致。
cdn.nlark.com/yuque/0/2019/jpeg/307286/1567322241949-064625c5-2919-4853-8c2a-b9b8a62ff688.jpeg"> 圖1 - 復制狀態機
SOFAJRaft 是基于 Raft 算法的生產級高性能 Java 實現,支持 MULTI-RAFT-GROUP。應用場景有 Leader 選舉、分布式鎖服務、高可靠的元信息管理、分布式存儲系統。
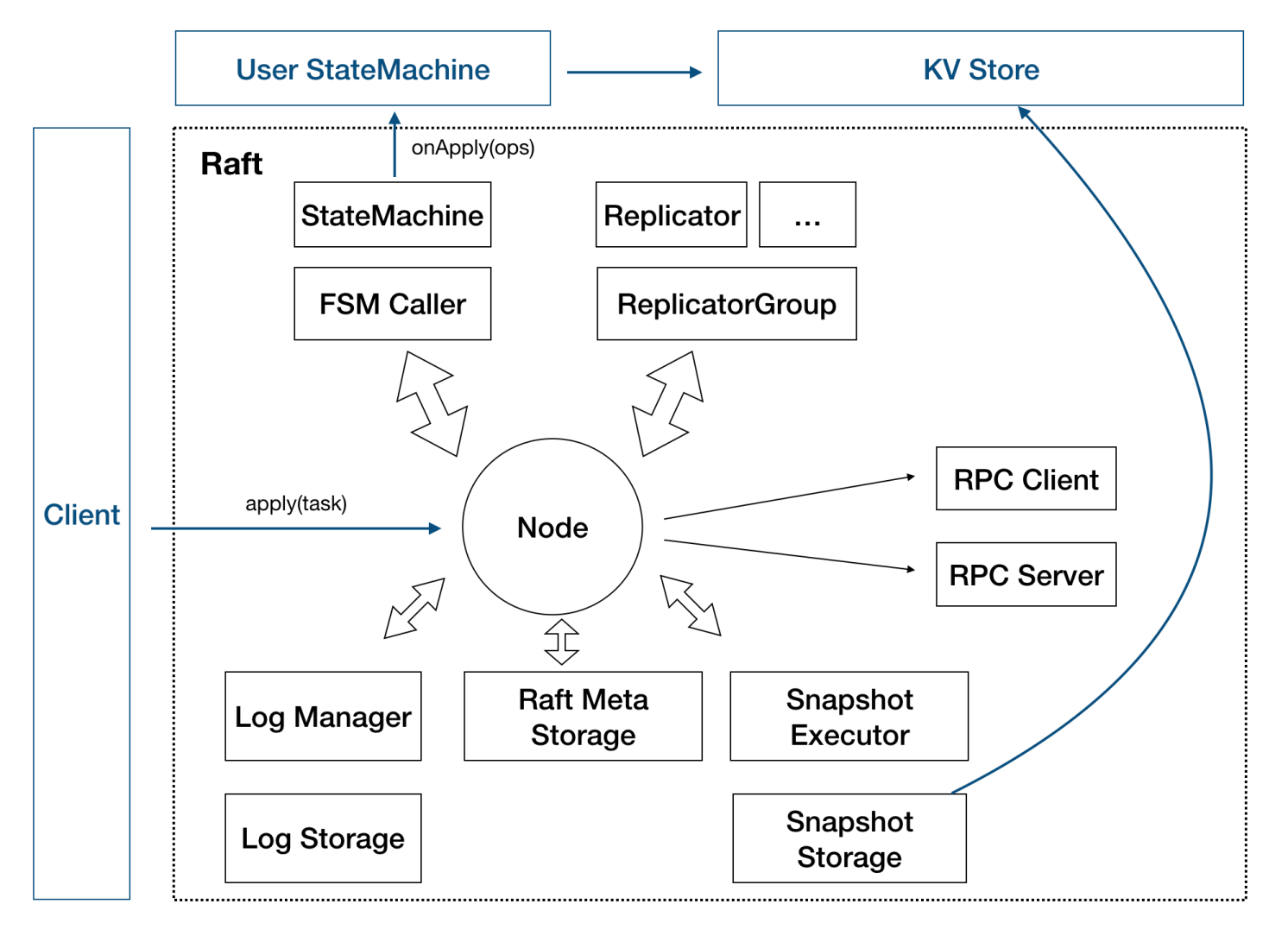 圖2 - SOFAJRaft 結構
圖2 - SOFAJRaft 結構
這張圖就是 SOFAJRaft 的設計圖,Node 代表了一個 SOFAJRaft Server 節點,這些方框代表他內部的各個模塊,我們依然用之前的銀行賬戶系統舉例來說明 SOFAJRaft 的各模塊是如何工作的。
當 Client 向 SOFAJRaft 發來一個“存 100 元”的命令之后,Node 的 Log 存儲模塊首先將這個命令以 Log 的形式存儲到本地,同時 Replicator 會把這個 Log 復制給其他的 Node,Replicator 是有多個的,集群中有多少個 Follower 就會有多少個 Replicator,這樣就能實現并發的日志復制。當 Node 收到集群中半數以上的 Follower 返回的“復制成功” 的響應之后,就可以把這條 Log 以及之前的 Log 有序的送到狀態機里去執行了。狀態機是由用戶來實現的,比如我們現在舉的例子是銀行賬戶系統,所以狀態機執行的就是賬戶金額的借貸操作。如果 SOFAJRaft 在別的場景中使用,狀態機就會有其他的執行方式。
Snapshot 是快照,所謂快照就是對數據當前值的一個記錄,Leader 生成快照有這么幾個作用:
當有新的 Node 加入集群的時候,不用只靠日志復制、回放去和 Leader 保持數據一致,而是通過安裝 Leader 的快照來跳過早期大量日志的回放;
Leader 用快照替代 Log 復制可以減少網絡上的數據量;
用快照替代早期的 Log 可以節省存儲空間;
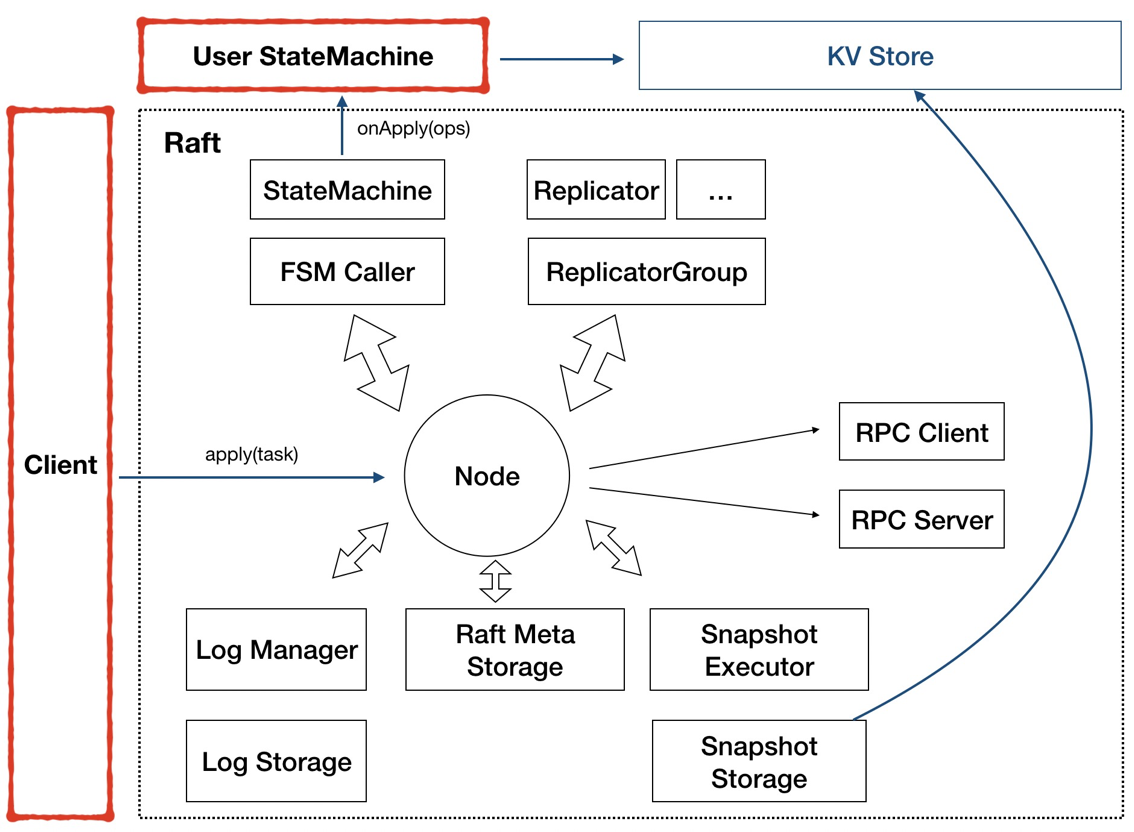 圖3 - 需要用戶實現:StateMachine、Client
圖3 - 需要用戶實現:StateMachine、Client
SOFAJRaft 需要用戶去實現兩部分:StateMachine 和 Client。
因為 SOFAJRaft 只是一個工具,他的目的是幫助我們在集群內達成共識,而具體要對什么業務邏輯達成共識是需要用戶自己去定義的,我們將用戶需要去實現的部分定義為 StateMachine 接口。比如賬務系統和分布式存儲這兩種業務就需要用戶去實現不同的 StateMachine 邏輯。而 Client 也很好理解,根據業務的不同,用戶需要去定義不同的消息類型和客戶端的處理邏輯。
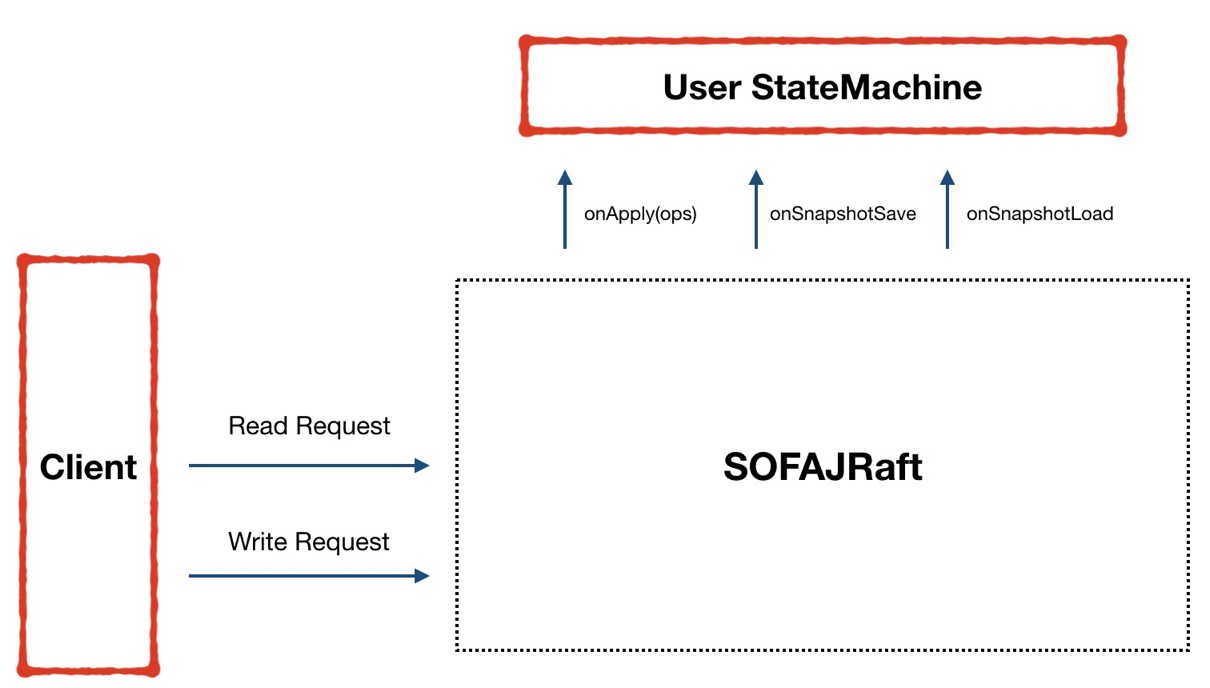 圖4 - 需要用戶實現一些接口
圖4 - 需要用戶實現一些接口
前面介紹了這么多,我們引出今天的主題:如何用 SOFAJRaft 實現一個分布式計數器?
我們的需求其實很簡單,用一句話來說就是:提供一個 Counter,Client 每次計數時可以指定步幅,也可以隨時發起查詢。
我們對這個需求稍作分析后,將它翻譯成具體的功能點,主要有三部分:
實現:Counter server,具備計數功能,具體運算公式為:Cn = Cn-1 + delta;
提供寫服務,寫入 delta 觸發計數器運算;
提供讀服務,讀取當前 Cn 值;
除此之外,我們還有一個可用性的可選需求,需要有備份機器,讀寫服務不能不可用。
根據剛才分析出來的功能需求,我們設計出 1.0 的架構,這個架構很簡單,一個節點 Counter Server 提供計數功能,接收客戶端發起的計數請求和查詢請求。
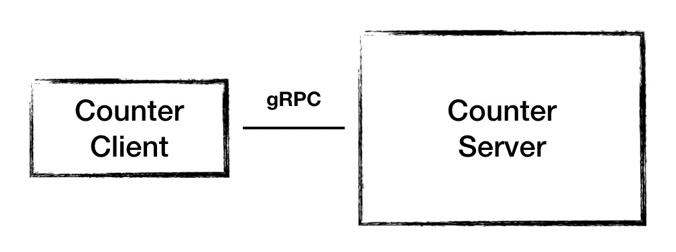 圖5 - 架構 1.0
圖5 - 架構 1.0
但是這樣的架構設計存在這樣兩個問題:一是 Server 是一個單點,一旦 Server 節點故障服務就不可用了;二是運算結果都存儲在內存當中,節點故障會導致數據丟失。
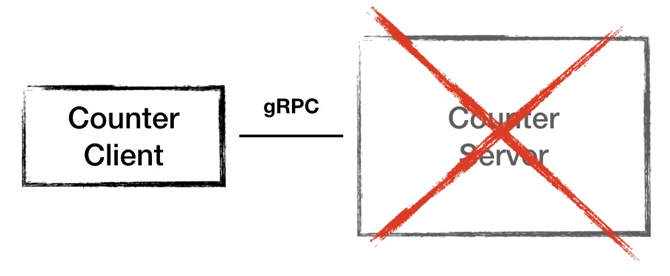 圖6 - 架構 1.0 的不足:單點
圖6 - 架構 1.0 的不足:單點
針對第二個問題,我們優化一下,加一個本地文件存儲。這樣每次計數器完成運算之后都將數據落盤,當節點故障之時,我們要新起一臺備用機器,將文件數據拷貝過來,然后接替故障機器對外提供服務。這樣就解決了數據丟失的風險,但是同時也引來另外的問題:磁盤 IO 很頻繁,同時這種冷備的模式也依然會導致一段時間的服務不可用。
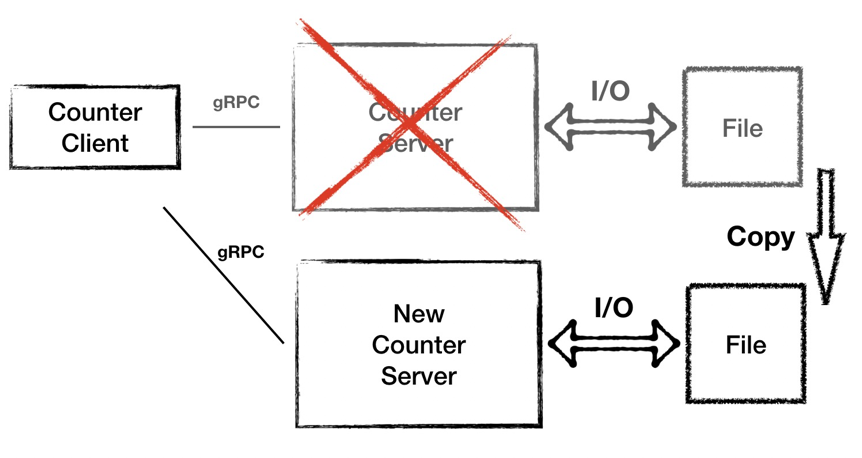 圖7 - 架構 1.0 的不足:冷備
圖7 - 架構 1.0 的不足:冷備
所以我們提出架構 2.0,采用集群的模式提供服務。我們用三個節點組成集群,由一個節點對外提供服務,當 Server 接收到 Client 發來的寫請求之后,Server 運算出結果,然后將結果復制給另外兩臺機器,當收到其他所有節點的成功響應之后,Server 向 Client 返回運算結果。
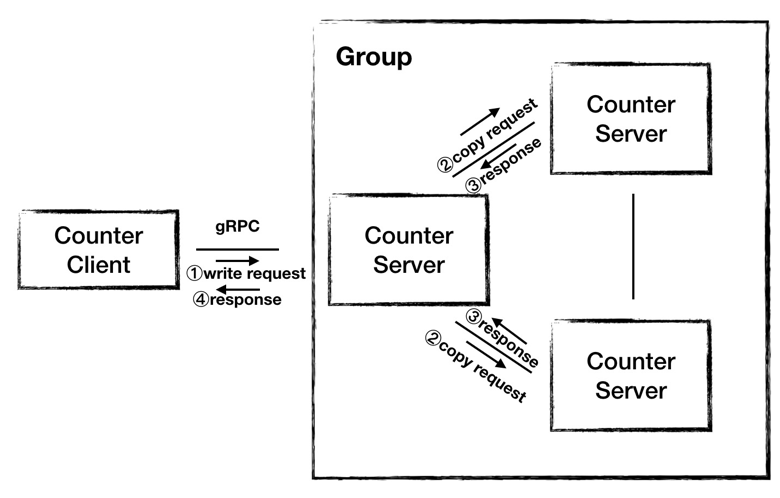 圖8 - 架構 2.0
圖8 - 架構 2.0
但是這樣的架構也存在這問題:
我們選擇哪一臺 Server 扮演 Leader 的角色對外提供服務;
當 Leader 不可用之后,選擇哪一臺接替它;
Leader 處理寫請求的時候需要等到所有節點都響應之后才能響應 Client;
也是比較重要的,我們無法保證 Leader 向 Follower 復制數據是有序的,所以任一時刻三個節點的數據都可能是不一樣的;
保證復制數據的順序和內容,這就有了共識算法的用武之地,所以在接下來的 3.0 架構里,我們使用 SOFAJRaft 來助力集群的實現。
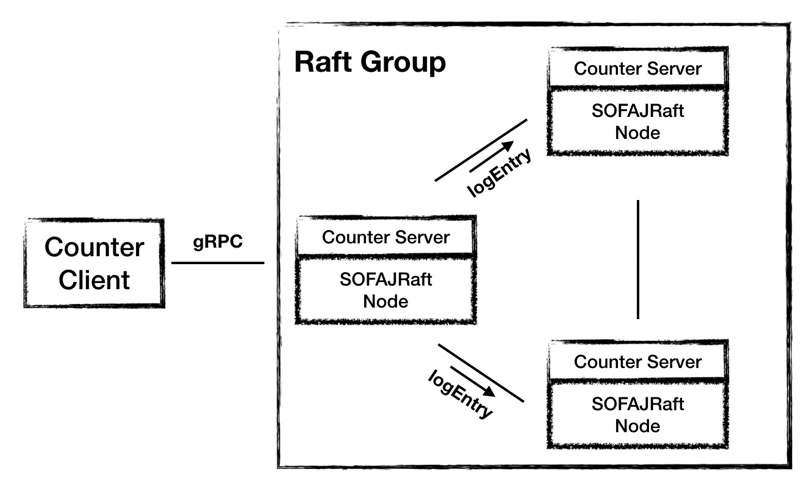 圖8 - 架構 3.0:使用 SOFAJRaft
圖8 - 架構 3.0:使用 SOFAJRaft
3.0 架構中,Counter Server 使用 SOFAJRaft 來組成一個集群,Leader 的選舉和數據的復制都交給 SOFAJRaft 來完成。在時序圖中我們可以看到,Counter 的業務邏輯重新變得像架構 1.0 中一樣簡潔,維護數據一致的工作都交給 SOFAJRaft 來完成,所以圖中灰色的部分對業務就不感知了。
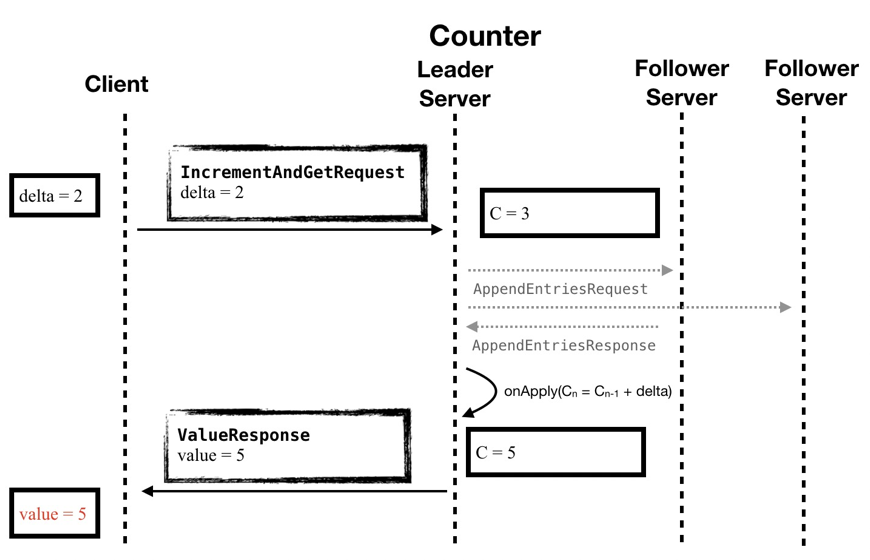 圖9 - 架構 3.0:時序圖
圖9 - 架構 3.0:時序圖
在使用 SOFAJRaft 的 3.0 架構中,SOFAJRaft 幫我們完成了 Leader 選舉、節點間數據同步的工作,除此之外,SOFAJRaft 只需要半數以上節點響應即可,不再需要集群所有節點的應答,這樣可以進一步提高寫請求的處理效率。
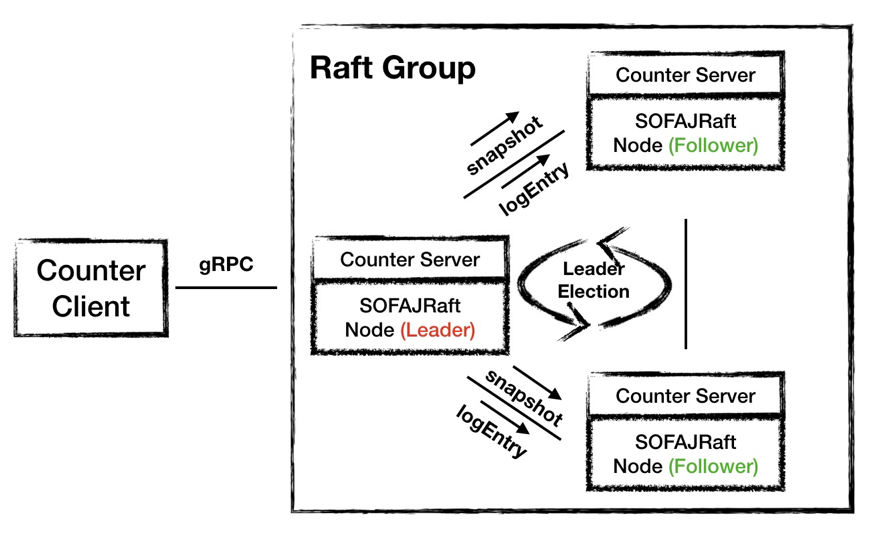 圖10 - 架構 3.0:SOFAJRaft 實現 Leader 選舉、日志復制
圖10 - 架構 3.0:SOFAJRaft 實現 Leader 選舉、日志復制
那么怎么使用 SOFAJRaft 呢?我們之前說過,SOFAJRaft 主要暴露了兩個地方給我們去實現,一是 Cilent,另一個是 StateMachine,所以我們的計數器也就是要去做這兩部分。
在 Client 上,我們要定義具體的消息類型,針對不同的消息類型,還需要去實現消息的 Processor 來處理這些消息,接下來這些消息就交給 SOFAJRaft 去完成集群內部的數據同步。
在 StateMachine 上,我們要去實現狀態機暴露給我們待實現的幾個接口,最重要的是 onApply 接口,要在這個接口里將 Cilent 的請求指令進行運算,轉換成具體的計數器值。而 onSnapshotSave 和 onSnapshotLoad 接口則是負責快照的生成和加載。
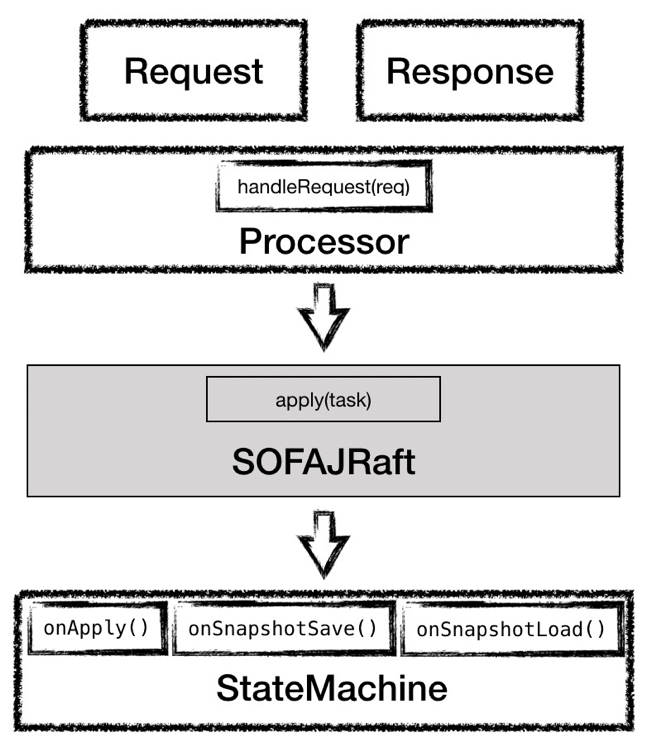 圖11 - 模塊關系
圖11 - 模塊關系
下面這張圖是最終實現的模塊關系圖,其實他已經是代碼實現之后的產物了,在這里并沒有貼出具體的代碼,因為代碼已經隨我們的項目一起開源了。我們實現了兩種消息類型 IncrementAndGetRequest 和 GetValueRequest,分別對應寫請求和讀請求,因為兩種請求的響應都是計數器的值,所以同用一個 ValueResponse。兩種請求,所以對應兩種 Processor:IncrementAndGetRequestProcessor 和 GetValueRequestProcessor,狀態機 CounterStateMachine 實現了之前提到的三個接口,除此之外還實現了 onLeaderStart 和 onLeaderStop,用來在節點成為 leader 和失去 leader 資格時做一些處理。這個地方在寫請求的處理中使用了 IncrementAndAddClosure ,這樣就可以通過 callback 的方式來實現響應。
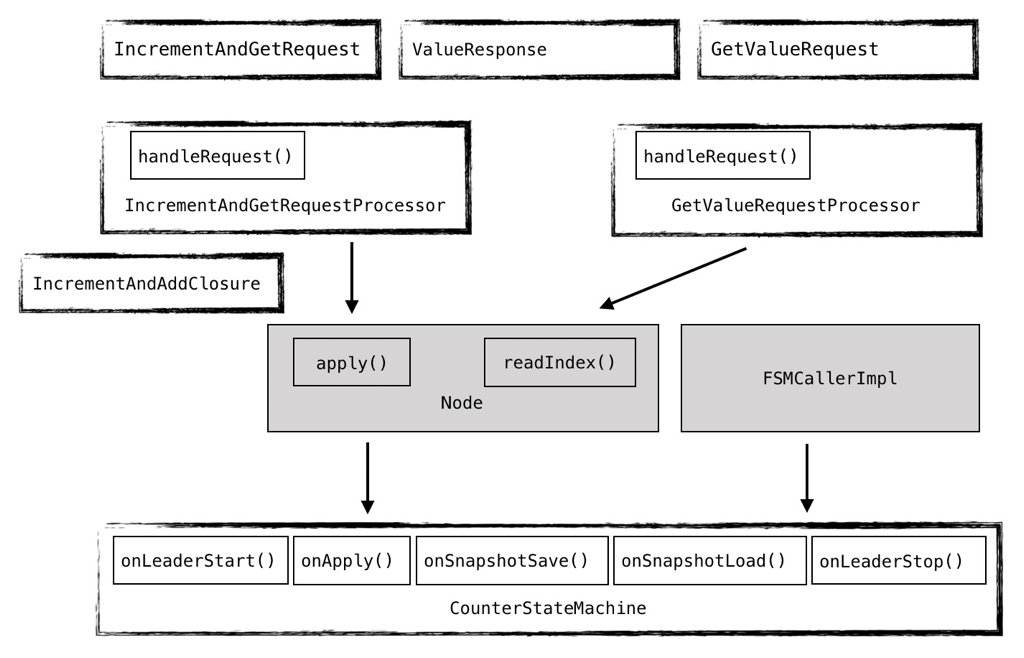 圖12 - 類關系圖
圖12 - 類關系圖
來看看整個的啟動過程。首先來看 Follower 節點的啟動 (當然,在啟動之前,我們并不知道哪個節點會是 Leader),Counter 在本地起三個進程用來模擬三個節點,它們分別使用 8081、8082、8083 三個端口,標記其為 A、B、C 節點。
A 節點率先啟動,然后開始向 B 和 C 發送 preVote 請求,但是這時候另外兩個節點都尚未啟動,所以 A 節點通信失敗,然后等待,再重試,如此往復。在 A 節點某次通信失敗后的等待之中,它突然收到了 B 節點發來的 preVote 請求,在經過一系列 check 之后,它認可了這個 preVote 請求,并且返回成功響應,隨后又對 B 節點發來的 vote 請求成功響應,然后我們可以看到,B 節點成功當選 Leader。這就是 Follower A 的啟動、投票過程。
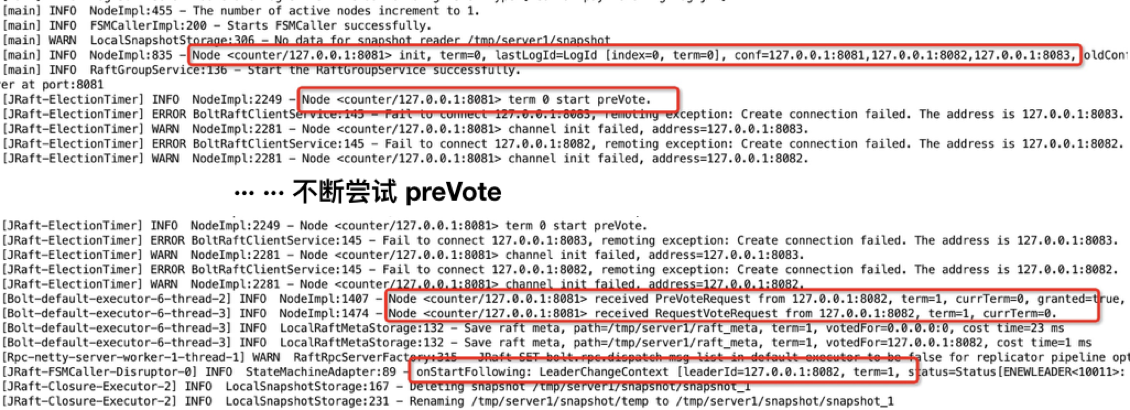 圖13 - Follower 啟動日志
圖13 - Follower 啟動日志
我們再看看 B 節點的啟動,B 節點在啟動之后,剛好處于 A 節點的一次等待間隙之中,所以它沒有收到其他節點發來的 preVote 請求,因此它向另外兩個節點發起了 preVote 請求,試圖競選。接下來它收到了 A 節點發來的確認響應,接著 B 節點又發起了 vote 請求,依然收到了 A 節點的響應。這樣 B 節點就收到了超過集群半數以上的投票并成功當選 (A 節點和 B 節點自己,達到 2/3) 。在此過程中,C 節點一直沒有啟動,但是由于 A 和 B 構成半數以上,所以共識算法已經可以正常 work。
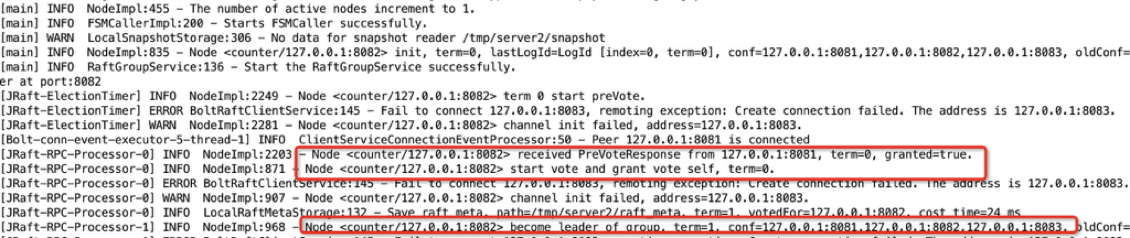 圖14 - Leader 啟動日志
圖14 - Leader 啟動日志
在剛才的過程中,我們提到了兩個關鍵詞:preVote 和 vote,這是選舉中的兩個階段,之所以要設置 preVote,是為了應對網絡分區的情況。關于 SOFAJRaft 的選舉,我們有專門的文章去解析 ,大家可以進一步了解。在這里我們將選舉的評選原則粗略的描述為:哪個節點保存的日志最新最完整,它就更有資格成為 leader。
接下來我們看看 Client 發起的一次寫請求。Client 共發起了三次寫請求,分別是 "+0"、"+1"、"+2"。從日志上我們可以看到,Leader 在收到這些請求之后,先把他們以日志的形式發送給其他節點 (并且是批量的),當它收到其他節點對日志復制的成功響應之后,再更新 committedIndex,最后調用 onApply 接口,執行 counter 的計數運算,將 client 發來的指令加到計數器當中。在這個過程中,可以看到 Leader 在處理寫請求的時候一個很重要的步驟就是將日志復制給其他節點。來詳細看下這個過程,以及當中提到的 committedIndex。
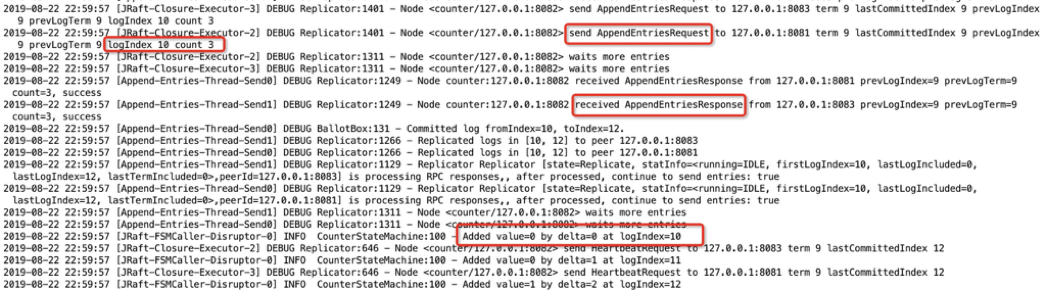 圖15 - Leader 處理寫請求
圖15 - Leader 處理寫請求
CommittedIndex 標志了一個位點,它標志在此之前的所有日志都已經復制到了集群半數以上的節點之中。圖中可以看到,committedIndex 初始指在 "3" 這個位置上,表示 "0-3" 的日志都已經復制到了半數以上節點之中 (在 Follower 上我們也已經看到),接下來 Leader 又把 "4"、"5" 兩條日志批量的復制到了 Follower 上,這是就可以把 committedIndex 右滑動到 "5" 的位置,表示 "0-5" 的日志都已經復制到了半數以上節點之中。
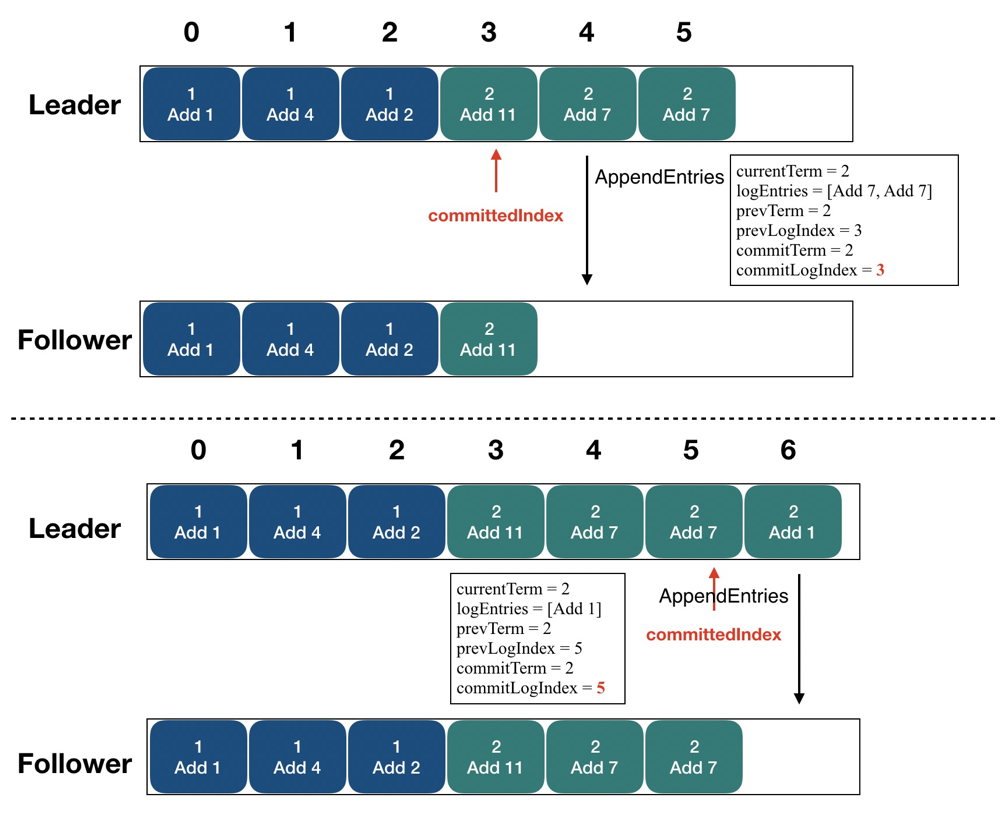 圖16 - 日志復制
圖16 - 日志復制
這時又產生了另一個問題:我們如何知道 StateMachine 執行到哪一條日志了?通過 committedIndex 我們可以知道哪些日志已經成功復制到集群其他節點之中了,但是 StateMachine 中此刻的狀態代表哪一條日志執行之后的結果呢?這就要用 applyIndex 來表示。在圖中,applyIndex 指向 "3",這表示:"0-3" 的日志代表的指令都已經被 StateMachine 執行,狀態機此刻的狀態代表 "3" 日志執行完畢之后的結果,當 committedIndex 向右滑動之后,applyIndex 就可以伴隨狀態機的執行繼續向右滑動了。ApplyIndex 和 committedIndex 就可以支持線性一致性讀,關于這個概念,我們也已經有文章去專門解析了,可以在文末鏈接中了解。
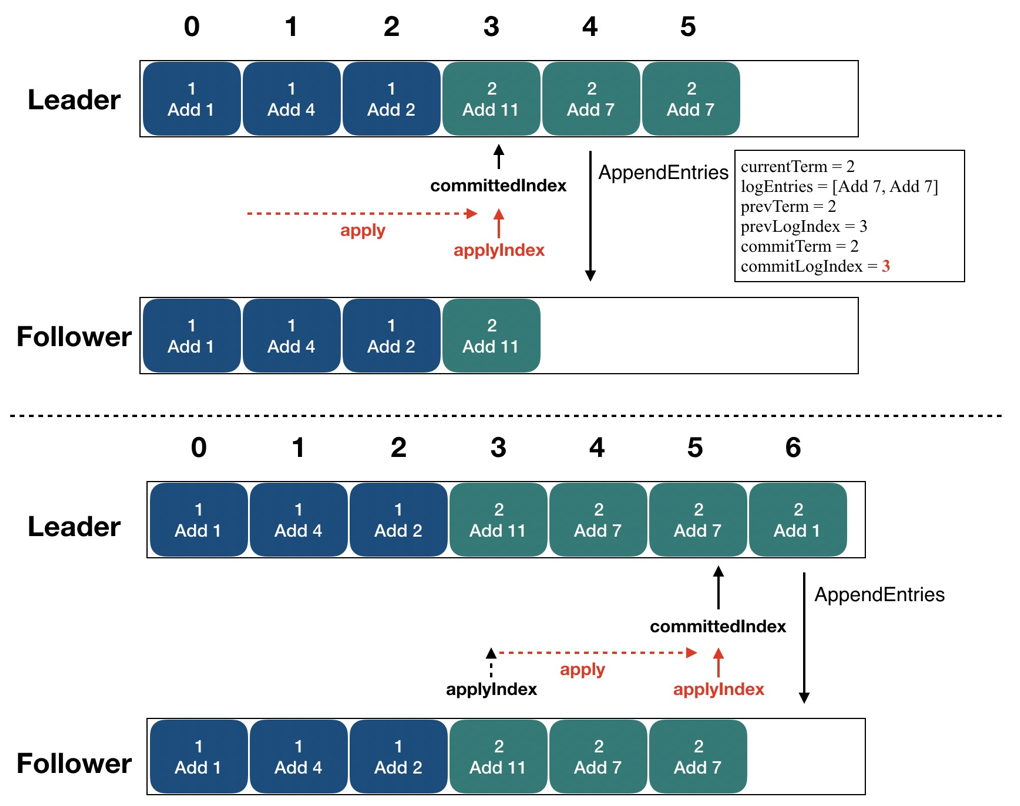 圖17 - ApplyIndex 更新
圖17 - ApplyIndex 更新
上述內容就是SOFAJRaft | SOFAChannel#8 的示例分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





