溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關pandas如何實現數據的合并與拼接,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
Pandas包的merge、join、concat方法可以完成數據的合并和拼接,merge方法主要基于兩個dataframe的共同列進行合并,join方法主要基于兩個dataframe的索引進行合并,concat方法是對series或dataframe進行行拼接或列拼接。
pandas的merge方法是基于共同列,將兩個dataframe連接起來。merge方法的主要參數:
left/right:左/右位置的dataframe。
how:數據合并的方式。left:基于左dataframe列的數據合并;right:基于右dataframe列的數據合并;outer:基于列的數據外合并(取并集);inner:基于列的數據內合并(取交集);默認為'inner'。
on:用來合并的列名,這個參數需要保證兩個dataframe有相同的列名。
left_on/right_on:左/右dataframe合并的列名,也可為索引,數組和列表。
left_index/right_index:是否以index作為數據合并的列名,True表示是。
sort:根據dataframe合并的keys排序,默認是。
suffixes:若有相同列且該列沒有作為合并的列,可通過suffixes設置該列的后綴名,一般為元組和列表類型。
merges通過設置how參數選擇兩個dataframe的連接方式,有內連接,外連接,左連接,右連接,下面通過例子介紹連接的含義。
how='inner',dataframe的鏈接方式為內連接,我們可以理解基于共同列的交集進行連接,參數on設置連接的共有列名。
# 單列的內連接
# 定義df1
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# print(df1)
# print(df2)
# 基于共同列alpha的內連接
df3 = pd.merge(df1,df2,how='inner',on='alpha')
df3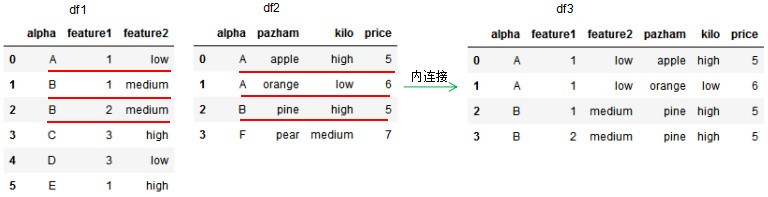
取共同列alpha值的交集進行連接。
how='outer',dataframe的鏈接方式為外連接,我們可以理解基于共同列的并集進行連接,參數on設置連接的共有列名。
# 單列的外連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的內連接
df4 = pd.merge(df1,df2,how='outer',on='alpha')
df4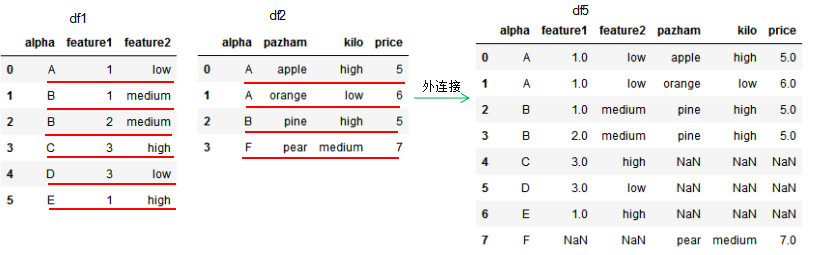
若兩個dataframe間除了on設置的連接列外并無相同列,則該列的值置為NaN。
how='left',dataframe的鏈接方式為左連接,我們可以理解基于左邊位置dataframe的列進行連接,參數on設置連接的共有列名。
# 單列的左連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的左連接
df5 = pd.merge(df1,df2,how='left',on='alpha')
df5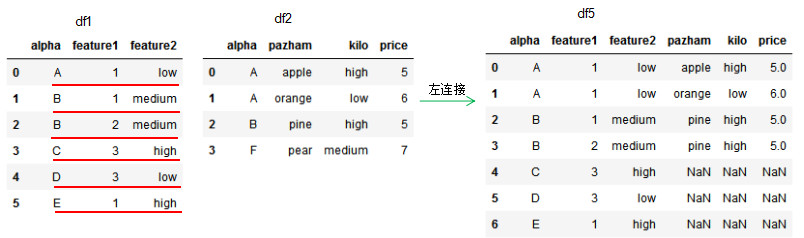
因為df2的連接列alpha有兩個'A'值,所以左連接的df5有兩個'A'值,若兩個dataframe間除了on設置的連接列外并無相同列,則該列的值置為NaN。
how='right',dataframe的鏈接方式為左連接,我們可以理解基于右邊位置dataframe的列進行連接,參數on設置連接的共有列名。
# 單列的右連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha的右連接
df6 = pd.merge(df1,df2,how='right',on='alpha')
df6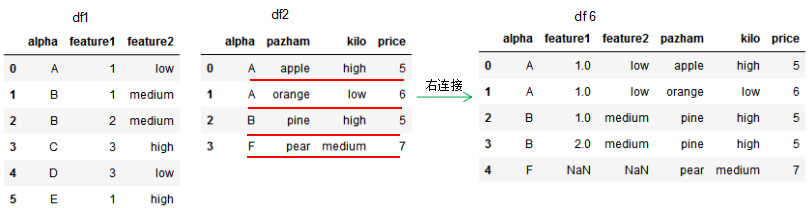
因為df1的連接列alpha有兩個'B'值,所以右連接的df6有兩個'B'值。若兩個dataframe間除了on設置的連接列外并無相同列,則該列的值置為NaN。
多列連接的算法與單列連接一致,本節只介紹基于多列的內連接和右連接,讀者可自己編碼并按照本文給出的圖解方式去理解外連接和左連接。
多列的內連接:
# 多列的內連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# 基于共同列alpha和beta的內連接
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner')
df7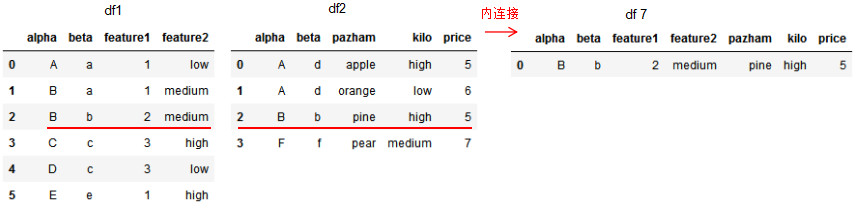
多列的右連接:
# 多列的右連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'beta':['d','d','b','f'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
print(df1)
print(df2)
# 基于共同列alpha和beta的右連接
df8 = pd.merge(df1,df2,on=['alpha','beta'],how='right')
df8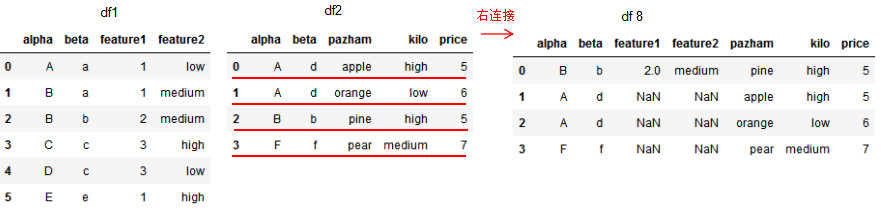
前面介紹了基于column的連接方法,merge方法亦可基于index連接dataframe。
# 基于column和index的右連接
# 定義df1
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'beta':['a','a','b','c','c','e'],
'feature1':[1,1,2,3,3,1],'feature2':['low','medium','medium','high','low','high']})
# 定義df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])},index=['d','d','b','f'])
print(df1)
print(df2)
# 基于df1的beta列和df2的index連接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True)
df9圖解index和column的內連接方法:
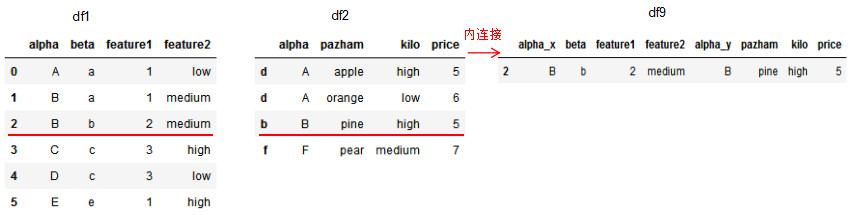
設置參數suffixes以修改除連接列外相同列的后綴名。
# 基于df1的alpha列和df2的index內連接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True,suffixes=('_df1','_df2'))
df9
join方法是基于index連接dataframe,merge方法是基于column連接,連接方法有內連接,外連接,左連接和右連接,與merge一致。
index與index的連接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)print(other)# lsuffix和rsuffix設置連接的后綴名
caller.join(other,lsuffix='_caller', rsuffix='_other',how='inner')
join也可以基于列進行連接:
caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)
print(other)
# 基于key列進行連接
caller.set_index('key').join(other.set_index('key'),how='inner')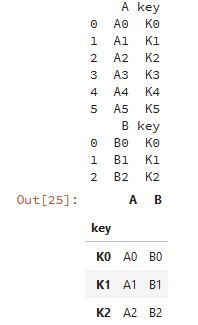
因此,join和merge的連接方法類似,這里就不展開join方法了,建議用merge方法。
concat方法是拼接函數,有行拼接和列拼接,默認是行拼接,拼接方法默認是外拼接(并集),拼接的對象是pandas數據類型。
行拼接:
df1 = pd.Series([1.1,2.2,3.3],index=['i1','i2','i3']) df2 = pd.Series([4.4,5.5,6.6],index=['i2','i3','i4']) print(df1) print(df2) # 行拼接 pd.concat([df1,df2])
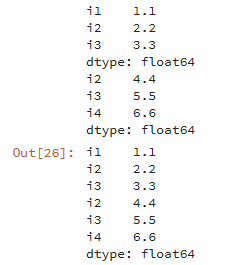
行拼接若有相同的索引,為了區分索引,我們在最外層定義了索引的分組情況。
# 對行拼接分組 pd.concat([df1,df2],keys=['fea1','fea2'])

列拼接:
默認以并集的方式拼接:
# 列拼接,默認是并集 pd.concat([df1,df2],axis=1)

以交集的方式拼接:
# 列拼接的內連接(交) pd.concat([df1,df2],axis=1,join='inner')

設置列拼接的列名:
# 列拼接的內連接(交) pd.concat([df1,df2],axis=1,join='inner',keys=['fea1','fea2'])

對指定的索引拼接:
# 指定索引[i1,i2,i3]的列拼接 pd.concat([df1,df2],axis=1,join_axes=[['i1','i2','i3']])

行拼接:
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(df1)
print(df2)
# 行拼接
pd.concat([df1,df2])
列拼接:
# 列拼接 pd.concat([df1,df2],axis=1)
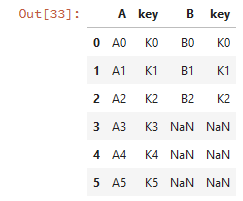
若列拼接或行拼接有重復的列名和行名,則報錯:
# 判斷是否有重復的列名,若有則報錯 pd.concat([df1,df2],axis=1,verify_integrity = True)
ValueError: Indexes have overlapping values: ['key']
關于“pandas如何實現數據的合并與拼接”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





