溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
什么是HDFS:
HDFS的設計目標:
HDFS官方文檔地址如下:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS是主/從式的架構。一個HDFS集群會有一個NameNode(簡稱NN),也就是命名節點,該節點作為主服務器存在(master server)。NameNode用于管理文件系統的命名空間以及調節客戶訪問文件。此外,還會有多個DataNode(簡稱DN),也就是數據節點,數據節點作為從節點存在(slave server)。通常每一個集群中的DataNode,都會被NameNode所管理,DataNode用于存儲數據。
HDFS公開了文件系統名稱空間,允許用戶將數據存儲在文件中,就好比我們平時使用操作系統中的文件系統一樣,用戶無需關心底層是如何存儲數據的。而在底層,一個文件會被分成一個或多個數據塊,這些數據塊會被存儲在一組數據節點中。在CDH中數據塊的默認大小是128M,這個大小我們可以通過配置文件進行調節。在NameNode上我們可以執行文件系統的命名空間操作,例如打開,關閉,重命名文件等。這也決定了數據塊到數據節點的映射。
我們可以來看看HDFS的架構圖: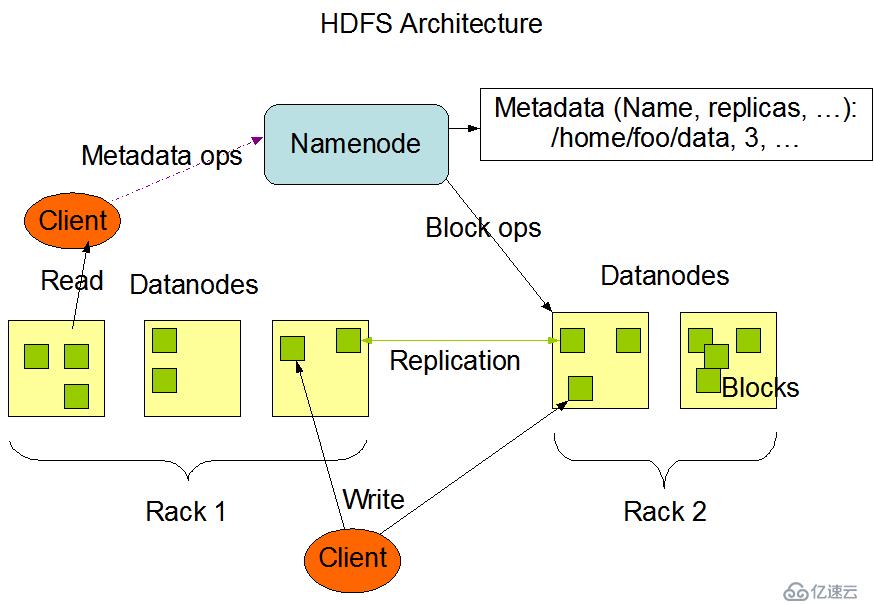
HDFS被設計為可以運行在普通的廉價機器上,而這些機器通常運行著一個Linux操作系統。HDFS是使用java語言編寫的,任何支持java的機器都可以運行HDFS。使用高度可移植的java語言編寫的HDFS,意味著可以部署在廣泛的機器上。一個典型的HDFS集群部署會有一個專門的機器只能運行NameNode,而其他集群中的機器各自運行一個DataNode實例。雖然一臺機器上也可以運行多個節點,但是并不建議這么做,除非是學習環境。
總結:
NN:
DN:
在HDFS中,一個文件會被拆分為一個或多個數據塊。默認情況下,每個數據塊都會有三個副本。每個副本都會被存放在不同的機器上,而且每一個副本都有自己唯一的編號。
如下圖: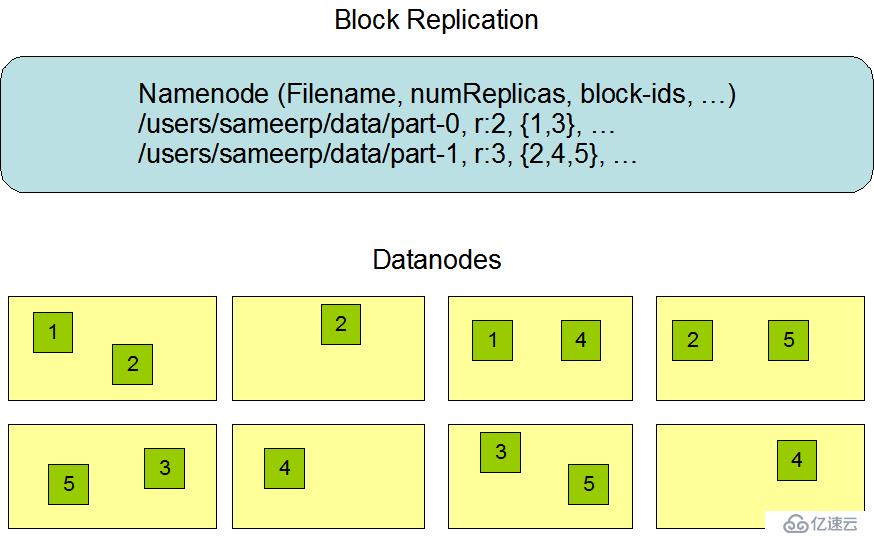
NameNode節點選擇一個DataNode節點去存儲block副本得過程就叫做副本存放,這個過程的策略其實就是在可靠性和讀寫帶寬間得權衡。
《Hadoop權威指南》中的默認方式:
如下圖: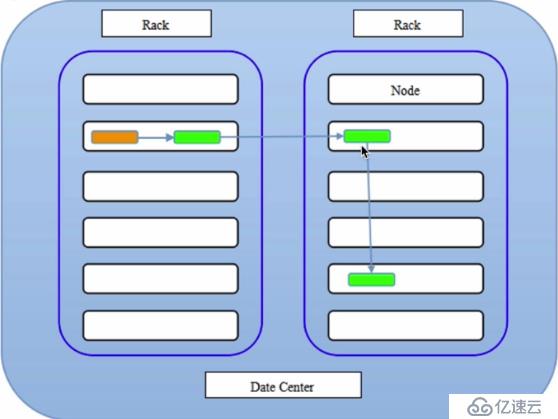
可以看出這個方案比較合理:
官方安裝文檔地址如下:
http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0/hadoop-project-dist/hadoop-common/SingleCluster.html
環境描述:
下載Hadoop 2.6.0-cdh6.7.0的tar.gz包并解壓:
[root@localhost ~]# cd /usr/local/src/
[root@localhost /usr/local/src]# wget http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0.tar.gz
[root@localhost /usr/local/src]# tar -zxvf hadoop-2.6.0-cdh6.7.0.tar.gz -C /usr/local/注:如果在Linux上下載得很慢的話,可以在windows的迅雷上使用這個鏈接進行下載。然后再上傳到Linux中,這樣就會快一些。
解壓完后,進入到解壓后的目錄下,可以看到hadoop的目錄結構如下:
[root@localhost /usr/local/src]# cd /usr/local/hadoop-2.6.0-cdh6.7.0/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]# ls
bin cloudera examples include libexec NOTICE.txt sbin src
bin-mapreduce1 etc examples-mapreduce1 lib LICENSE.txt README.txt share
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]#簡單說明一下其中幾個目錄存放的東西:
以上就算是把hadoop給安裝好了,接下來就是編輯配置文件,把JAVA_HOME配置一下:
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]# cd etc/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc]# cd hadoop
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8/ # 根據你的環境變量進行修改由于我們要進行的是單節點偽分布式環境的搭建,所以還需要配置兩個配置文件,分別是core-site.xml以及hdfs-site.xml,如下:
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim core-site.xml # 增加如下內容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.77.130:8020</value> # 指定默認的訪問地址以及端口號
</property>
<property>
<name>hadoop.tmp.dir</name> # 指定臨時文件所存放的目錄
<value>/data/tmp/</value>
</property>
</configuration>
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# mkdir /data/tmp/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim hdfs-site.xml # 增加如下內容
<configuration>
<property>
<name>dfs.replication</name> # 指定只產生一個副本
<value>1</value>
</property>
</configuration>然后配置一下密鑰對,設置本地免密登錄,搭建偽分布式的話這一步是必須的:
[root@localhost ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
c2:41:89:65:bd:04:9e:3e:3f:f9:a7:51:cd:e9:cf:1e root@localhost
The key's randomart image is:
+--[ DSA 1024]----+
| o=+ |
| .+..o |
| +. . |
| o .. o . |
| = S . + |
| + . . . |
| + . .E |
| o .. o.|
| oo .+|
+-----------------+
[root@localhost ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@localhost ~]# ssh localhost
ssh_exchange_identification: read: Connection reset by peer
[root@localhost ~]# 如上,測試本地免密登錄的時候報了個ssh_exchange_identification: read: Connection reset by peer錯誤,于是著手排查錯誤,發現是/etc/hosts.allow文件里限制了IP,于是修改一下該配置文件即可,如下:
[root@localhost ~]# vim /etc/hosts.allow # 修改為 sshd: ALL
[root@localhost ~]# service sshd restart
[root@localhost ~]# ssh localhost # 測試登錄成功
Last login: Sat Mar 24 21:56:38 2018 from localhost
[root@localhost ~]# logout
Connection to localhost closed.
[root@localhost ~]# 接下來就可以啟動HDFS了,不過在啟動之前需要先格式化文件系統:
[root@localhost ~]# /usr/local/hadoop-2.6.0-cdh6.7.0/bin/hdfs namenode -format注:只有第一次啟動才需要格式化
使用服務啟動腳本啟動服務:
[root@localhost ~]# /usr/local/hadoop-2.6.0-cdh6.7.0/sbin/start-dfs.sh
18/03/24 21:59:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [192.168.77.130]
192.168.77.130: namenode running as process 8928. Stop it first.
localhost: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh6.7.0/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 63:74:14:e8:15:4c:45:13:9e:16:56:92:6a:8c:1a:84.
Are you sure you want to continue connecting (yes/no)? yes # 第一次啟動會詢問是否連接節點
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0-cdh6.7.0/logs/hadoop-root-secondarynamenode-localhost.out
18/03/24 21:59:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@localhost ~]# jps # 檢查是否有以下幾個進程,如果少了一個都是不成功的
8928 NameNode
9875 Jps
9578 DataNode
9757 SecondaryNameNode
[root@localhost ~]# netstat -lntp |grep java # 檢查端口
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 9757/java
tcp 0 0 192.168.77.130:8020 0.0.0.0:* LISTEN 8928/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 8928/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 9578/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 9578/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 9578/java
tcp 0 0 127.0.0.1:53703 0.0.0.0:* LISTEN 9578/java
[root@localhost ~]# 然后將Hadoop的安裝目錄配置到環境變量中,方便之后使用它的命令:
[root@localhost ~]# vim ~/.bash_profile # 增加以下內容
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh6.7.0/
export PATH=$HADOOP_HOME/bin:$PATH
[root@localhost ~]# source !$
source ~/.bash_profile
[root@localhost ~]#確認服務啟動成功后,使用瀏覽器訪問192.168.77.130:50070,會訪問到如下頁面: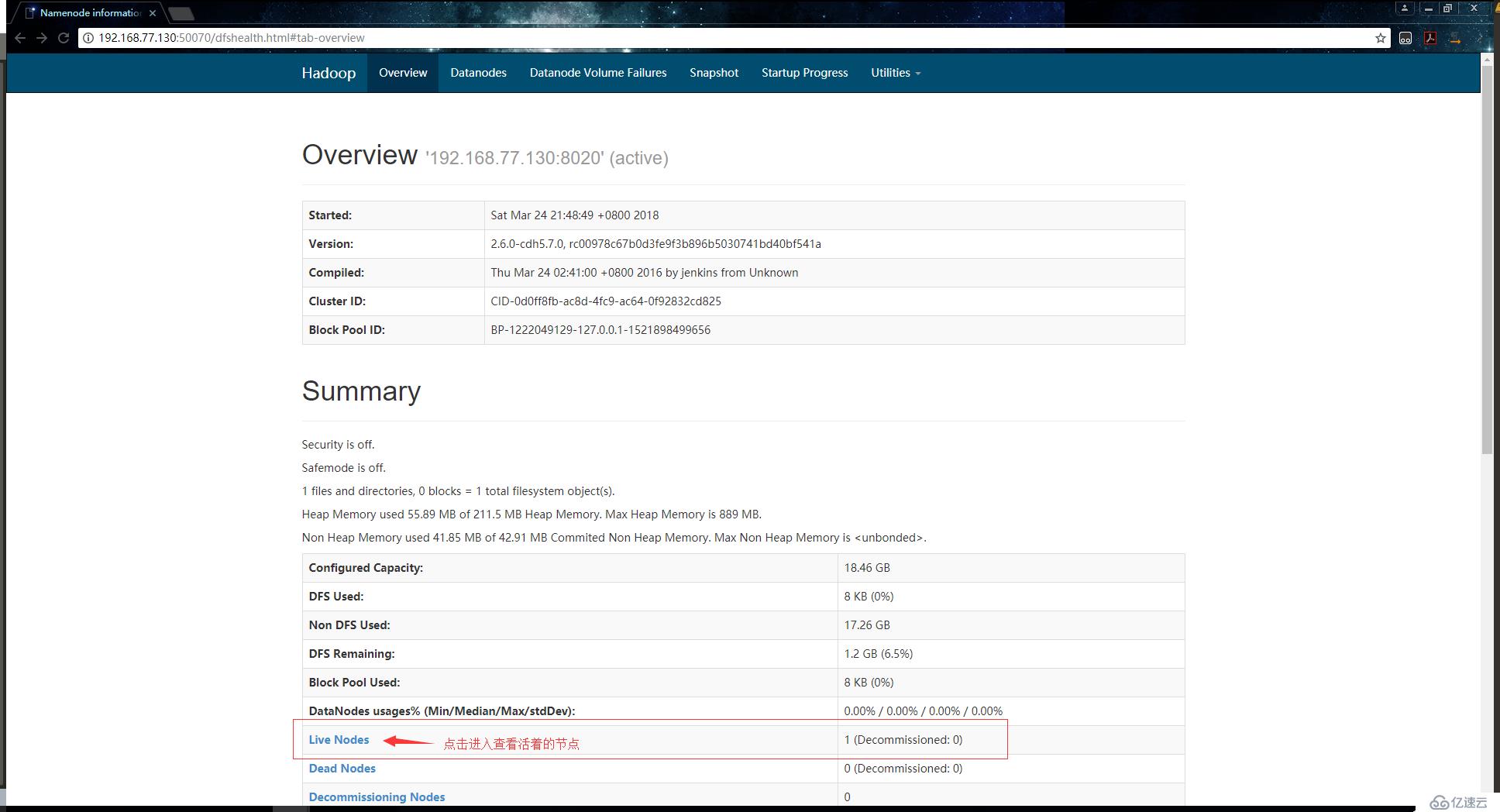
點擊Live Nodes查看活著的節點:
如上,可以看到節點的信息。到此,我們偽分布式的hadoop集群就搭建完成了。
以上已經介紹了如何搭建偽分布式的Hadoop,既然環境已經搭建起來了,那要怎么去操作呢?這就是本節將要介紹的內容:
HDFS自帶有一些shell命令,通過這些命令我們可以去操作HDFS文件系統,這些命令與Linux的命令挺相似的,如果熟悉Linux的命令很容易就可以上手HDFS的命令,關于這些命令的官方文檔地址如下:
http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html
以下介紹幾個常用的命令:
首先我們創建一個測試文件:
[root@localhost ~]# cd /data/
[root@localhost /data]# vim hello.txt # 隨便寫一些內容
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
[root@localhost /data]# 1.查看文件系統的根目錄:
[root@localhost /data]# hdfs dfs -ls /
[root@localhost /data]#2.將剛剛創建的文件拷貝到文件系統的根目錄下:
[root@localhost /data]# hdfs dfs -put ./hello.txt /
[root@localhost /data]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 49 2018-03-24 22:37 /hello.txt
[root@localhost /data]# 3.查看文件內容:
[root@localhost /data]# hdfs dfs -cat /hello.txt
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
[root@localhost /data]# 4.創建目錄:
[root@localhost /data]# hdfs dfs -mkdir /test
[root@localhost /data]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 1 root supergroup 49 2018-03-24 22:37 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 22:40 /test
[root@localhost /data]# 5.遞歸創建目錄:
[root@localhost /data]# hdfs dfs -mkdir -p /test/a/b/c6.遞歸查看目錄:
[root@localhost /data]# hdfs dfs -ls -R /
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:02 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b/c
[root@localhost /data]# 7.拷貝文件:
[root@localhost /data]# hdfs dfs -copyFromLocal ./hello.txt /test/a/b
[root@localhost /data]# hdfs dfs -ls -R /
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:02 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a
drwxr-xr-x - root supergroup 0 2018-03-24 23:06 /test/a/b
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b/c
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:06 /test/a/b/hello.txt
[root@localhost /data]# 8.從文件系統中拿出文件:
[root@localhost /data]# hdfs dfs -get /test/a/b/hello.txt9.刪除文件:
[root@localhost /data]# hdfs dfs -rm /hello.txt
Deleted /hello.txt
[root@localhost /data]# 10.刪除目錄:
[root@localhost /data]# hdfs dfs -rm -R /test
Deleted /test
[root@localhost /data]# 以上就是最為常用的一些操作命令了,如果需要使用其他命令,直接執行hdfs dfs就可以查看到所支持的所有命令。
接下來我們在瀏覽器里查看文件系統,首先將剛剛刪除的文件put回去:
[root@localhost /data]# hdfs dfs -put ./hello.txt /在瀏覽器上查看文件系統:
查看文件的信息: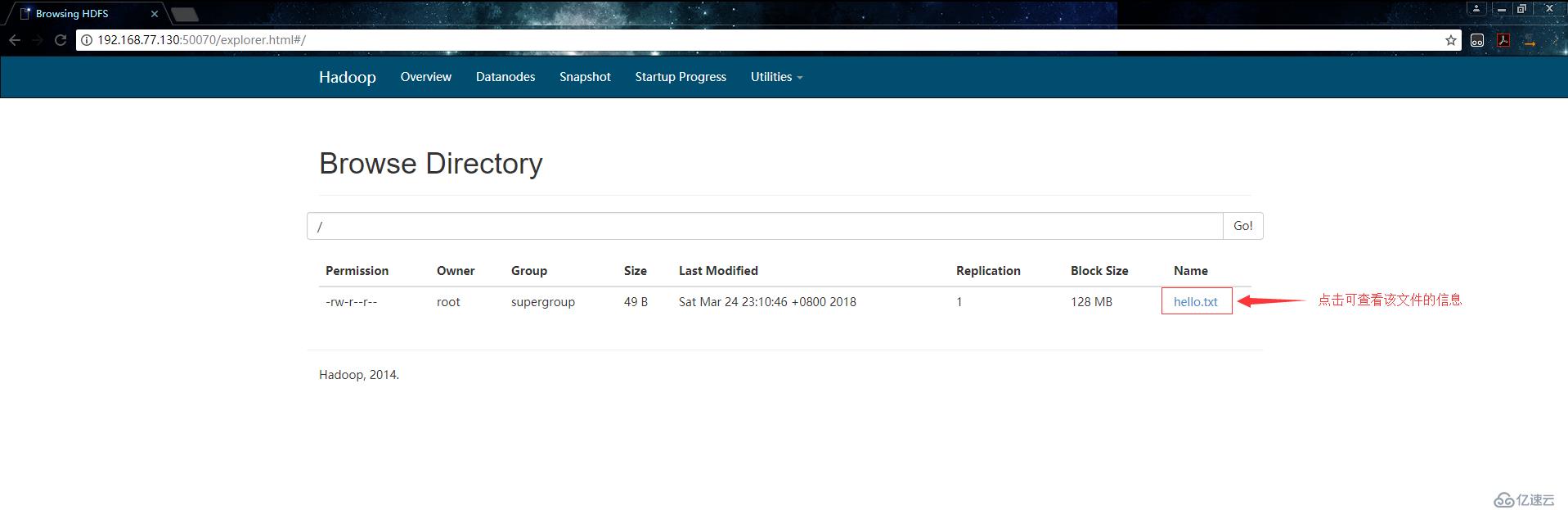
可以看到關于該文件的詳細信息: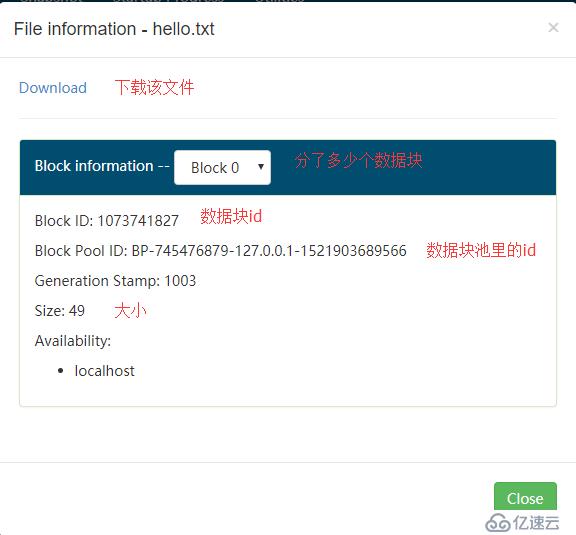
由于這個文件太小了,所以只有一個數據塊。
我們來put一個比較大的文件,例如我們之前使用的Hadoop的安裝包:
[root@localhost /data]# cd /usr/local/src/
[root@localhost /usr/local/src]# hdfs dfs -put ./hadoop-2.6.0-cdh6.7.0.tar.gz /如下,可以看到,這個文件被分為了三個數據塊: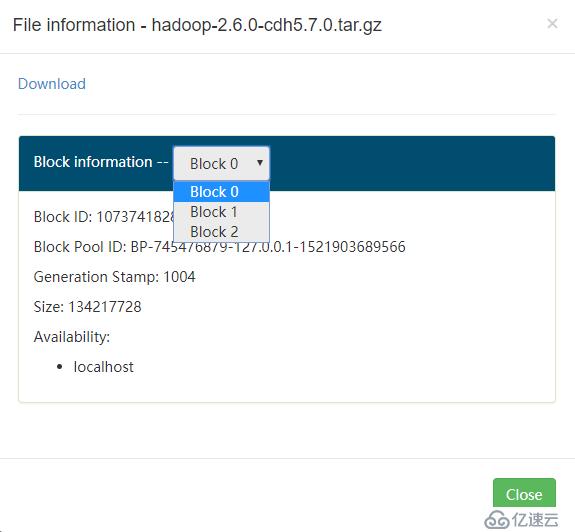
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





