溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
spark的調度一直是我想搞清楚的東西,以及有向無環圖的生成過程、task的調度、rdd的延遲執行是怎么發生的和如何完成的,還要就是RDD的compute都是在executor的哪個階段調用和執行我們定義的函數的。這些都非常的基礎和困難。花一段時間終于弄白了其中的奧秘。總結起來,以便以后繼續完善。spark的調度分為兩級調度:DAGSchedule和TaskSchedule。DAGSchedule是根據job來生成相互依賴的stages,然后把stages以TaskSet形式傳遞給TaskSchedule來進行任務的分發過程,里面的細節會慢慢的講解出來的,比較長。
1、spark的RDD邏輯執行鏈
2、spark的job的劃分、stage的劃分
3、spark的DAGScheduler的調度
4、spark的TaskSchedule的調度
5、executor如何執行task以及我們定義的函數
都說spark進行延遲執行,通過RDD的DAG來生成相應的Stage等,RDD的DAG的形成過程,是通過依賴來完成的,每一個RDD通過轉換算子的時候都會生成一個和多個子RDD,在通過轉換算子的時候,在創建一個新的RDD的時候,也會創建他們之間的依賴關系。因此他們是通過Dependencies連接起來的,RDD的依賴不是我們的重點,如果想了解RDD的依賴,可以自行google,RDD的依賴分為:1:1的OneToOneDependency,m:1的RangeDependency,還有m:n的ShuffleDependencies,其中OneToOneDependency和RangeDependency又被稱為NarrowDependency,這里的1:1,m:1,m:n的粒度是對于RDD的分區而言的。
依賴中最根本的是保留了父RDD,其rdd的方法就是返回父RDD的方法。這樣其就形成了一個鏈表形式的結構,通過最后面的RDD根據依賴,可以向前回溯到所有的父類RDD。
我們以map為例,來看一下依賴是如何產生的。
通過map其實其實創建了一個MapPartitonsRDD的RDD
然后我們看一下MapPartitonsRDD的主構造函數,其又對RDD進行了賦值,其中父RDD就是上面的this對象指定的RDD,我們再看一下RDD這個類的構造函數:
其又調用了RDD的主構造函數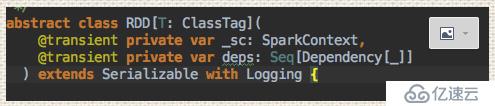
其實依賴都是在RDD的構造函數中形成的。
通過上面的依賴轉換就形成了RDD額DAG圖
生成了一個RDD的DAG圖: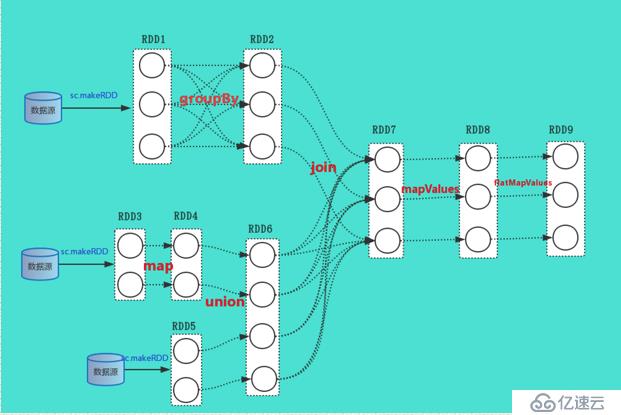
spark的job的劃分、stage的劃分
spark的Application劃分job其實挺簡單的,一個Application劃分為幾個job,我們就要看這個Application中有多少個Action算子,一個Action算子對應一個job,這個可以通過源碼來看出來,轉換算子是形成一個或者多個RDD,而Action算子是觸發job的提交。
比如上面的map轉換算子就是這樣的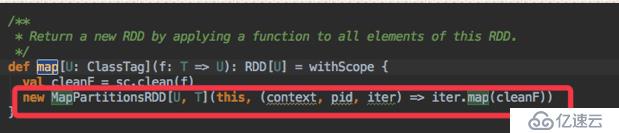
而Action算子是這樣的:
通過runJob方法提交作業。stage的劃分是根據是否進行shuflle過程來決定的,這個后面會細說。
spark的DAGScheduler的調度
當我們通過客戶端,向spark集群提交作業時,如果利用的資源管理器是yarn,那么客戶端向spark提交申請運行driver進程的機器,driver其實在spark中是沒有具體的類的,driver機器主要是用來運行用戶編寫的代碼的地方,完成DAGScheduler和TaskSchedule,追蹤task運行的狀態。記住,用戶編寫的主函數是在driver中運行的,但是RDD轉換和執行是在不同的機器上完成。其實driver主要負責作業的調度和分發。Action算子到stage的劃分和DAGScheduler的完成過程。
當我們在driver進程中運行用戶定義的main函數的時候,首先會創建SparkContext對象,這個是我們與spark集群進行交互的入口它會初始化很多運行需要的環境,最主要的是初始化了DAGScheduler和TaskSchedule。
我們以這樣的的一個RDD的邏輯執行圖來分析整個DAGScheduler的過程。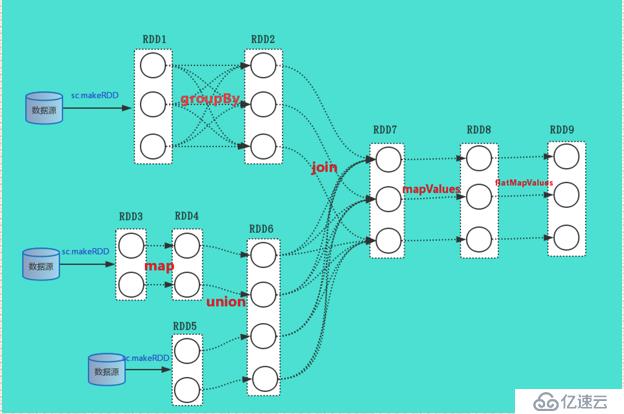
因為DAGScheduler發生在driver進程中,我們就沖Driver進程運行用戶定義的main函數開始。在上圖中RDD9是最后一個RDD并且其調用了Action算子,就會觸發作業的提交,其會調用SparkContext的runjob函數,其經過一系列的runJob的封裝,會調用DAGScheduler的runJob
在SparkContext中存在著runJob方法
def runJob[T, U: ClassTag](
rdd: RDD[T], // rdd為上面提到的RDD邏輯執行圖中的RDD9
func: (TaskContext, Iterator[T]) => U,這個方法也是RDD9調用Action算子傳入的函數
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
DAGScheduler的runJob
def runJob[T, U](
rdd: RDD[T], //RDD9
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
//在這里會生成一個job的守護進程waiter,用來等待作業提交執行是否完成,其又調用了submitJob,其以下的代
//碼都是用來處運行結果的一些log日志信息
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
submitJob的源代碼
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 檢查RDD的分區是否合法
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
//這一塊是把我們的job繼續進行封裝到JobSubmitted,然后放入到一個進程中池里,spark會啟動一個線程來處理我
//們提交的作業
val func2 = func.asInstanceOf[(TaskContext, Iterator[]) => ]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
在DAGScheduler類中有一個DAGSchedulerEventProcessLoop的類,用來接收處理DAGScheduler的消息事件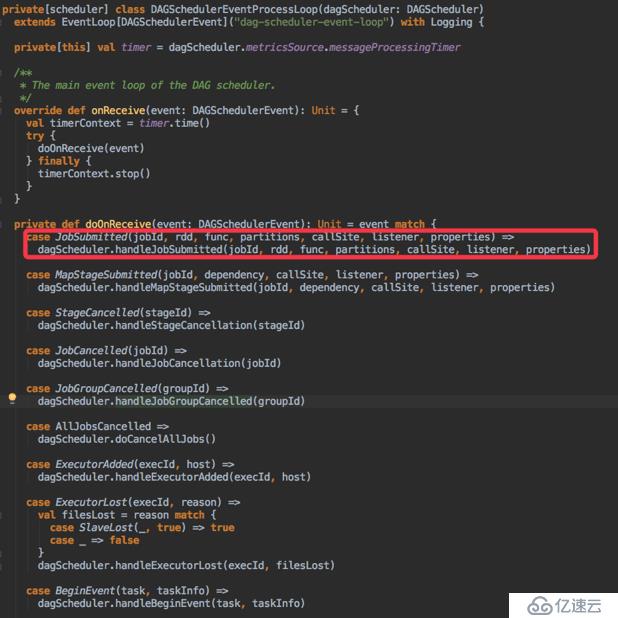
JobSubmitted對象,因此會執行第一個操作handleJobSubmitted,在這里我們要說一下,Stage的類型,在spark中有兩種類型的stage一種是ShuffleMapStage,和ResultStage,最后一個RDD對應的Stage是ResultStage,遇到Shuffle過程的RDD被稱為ShuffleMapStage。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[],//對應RDD9
func: (TaskContext, Iterator[]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// 先創建ResultStage。
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
上面的createResultStage其實就是RDD轉換為Stage的過程,方法如下
/*
創建ResultStage的時候,它會調用相關函數
*/
private def createResultStage(
rdd: RDD[], //對應上圖的RDD9
func: (TaskContext, Iterator[]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
/**
較容易看出來,根據上面的RDD邏輯依賴圖,其返回的ShuffleDependency就是RDD2和RDD1,RDD7和RDD6的依
賴,如果存在A<-B<-C,這兩個都是shuffle依賴,那么對于C其只返回B的shuffle依賴,而不會返回A
/
private[scheduler] def getShuffleDependencies(
rdd: RDD[]): HashSet[ShuffleDependency[, , ]] = {
//用來存放依賴
val parents = new HashSet[ShuffleDependency[, , ]]
//遍歷過的RDD放入這個里面
val visited = new HashSet[RDD[]]
//創建一個待遍歷RDD的棧結構
val waitingForVisit = new ArrayStack[RDD[]]
//壓入finalRDD,邏輯圖中的RDD9
waitingForVisit.push(rdd)
//循環遍歷這個棧結構
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
// 如果RDD沒有被遍歷過執行其中的代碼
if (!visited(toVisit)) {
//然后把其放入已經遍歷隊列中
visited += toVisit
//得到依賴,我們知道依賴中存放的有父RDD的對象
toVisit.dependencies.foreach {
//如果這個依賴是shuffle依賴,則放入返回隊列中
case shuffleDep: ShuffleDependency[, , ] =>
parents += shuffleDep
case dependency =>
//如果不是shuffle依賴,把其父RDD壓入待訪問棧中,從而進行循環
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
/創建shuffleMapStage,根據上面得到的兩個Shuffle對象,分別創建了兩個shuffleMapStage
/
/
def createShuffleMapStage(shuffleDep: ShuffleDependency[, , _], jobId: Int): ShuffleMapStage = {
//這個RDD其實就是RDD1和RDD6
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId) //查看這兩個ShuffleMapStage是否存在父Shuffle的Stage
val id = nextStageId.getAndIncrement()
//創建ShuffleMapStage,下面是更新一下SparkContext的狀態
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
通過上面的源代碼分析,結合RDD的邏輯執行圖,我們可以看出,這個job擁有三個Stage,一個ResultStage,兩個ShuffleMapStage,一個ShuffleMapStage中的RDD是RDD1,另一個stage中的RDD是RDD6,從而,以上完成了RDD到Stage的切分工作。當切分完成后在handleJobSubmitted這個方法的最后,調用提交stage的方法。
submitStage源代碼比較簡單,它會檢查我們當前的stage依賴的父stage是否已經執行完成,如果沒有執行完成會循環提交其父stage等待其父stage執行完成了,才提交我們當前的stage進行執行。
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
提交task的方法源代碼,我們按照剛才的三個stage中,提交的是前兩個stage的過程來看待這個源代碼。以包含RDD1的stage為例
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// Get our pending tasks and remember them in our pendingTasks entry
stage.pendingPartitions.clear()
// 計算需要計算的分區數
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// 封裝stage的一些信息,得到stage到分區數的映射關系,即一個stage對應多少個分區需要計算
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}//得到每個分區對應的具體位置,即分區的數據位于集群的哪臺機器上。
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 這個把上面stage要計算的分區和每個分區對應的物理位置進行了從新封裝,放在了latestInfo里面
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
//序列化我們剛才得到的信息,以便在driver機器和work機器之間進行傳輸
var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}//封裝stage構成taskSet集合,ShuffleMapStage對應的task為ShuffleMapTask,而ResultStage對應的taskSet為ResultTask
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
//提交task給TaskSchedule
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
submitWaitingChildStages(stage)}
}
到此,完成了整個DAGScheduler的調度。
spark的Task的調度,我們要明白其調度過程,其根據不同的資源管理器擁有不同的調度策略,因此也擁有不同的調度守護進程,這個守護進程管理著集群的資源信息,spark提供了一個基本的守護進程的類,來完成與driver和executor的交互:CoarseGrainedSchedulerBackend,它應該運行在集群資源管理器上,比如yarn等。他收集了集群work機器的一般資源信息。當我們形成tasks將要進行調度的時候,driver進程會與其通信,請求資源的分配和調度,其會把最優的work節點分配給task來執行其任務。而TaskScheduleImpl實現了task調度的過程,采用的調度算法默認的是FIFO的策略,也可以采用公平調度策略。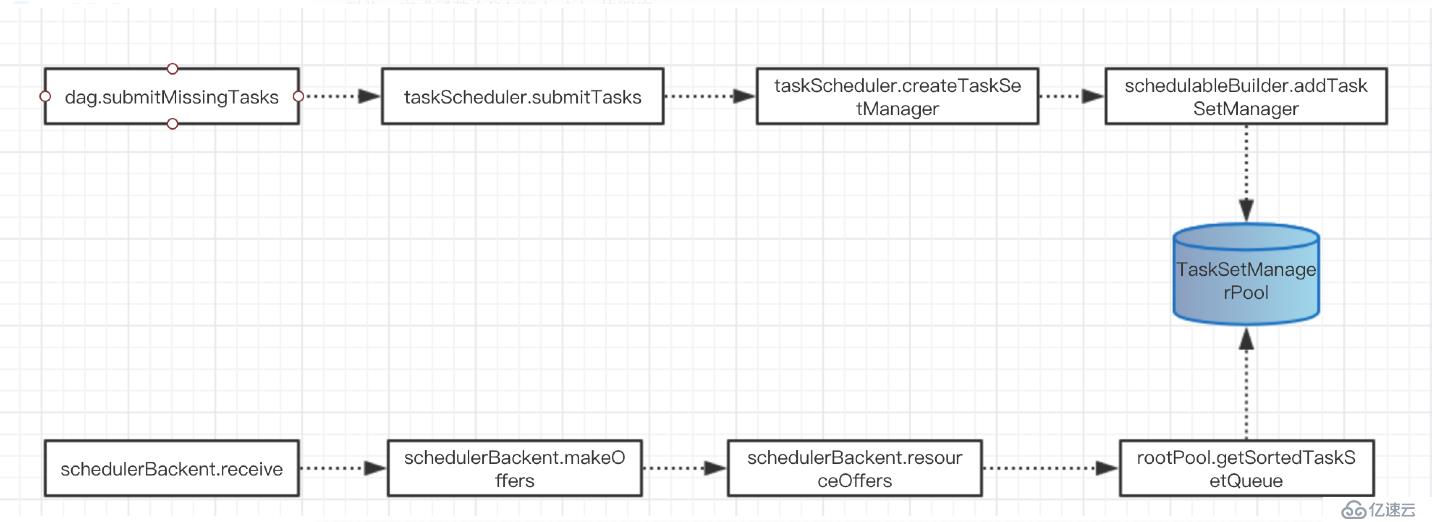
當我們提交task時,其會創建一個管理task的類TaskSetManager,然后把其加入到任務調度池中。
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 創建taskSetManager,以下為更新一下狀態
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{._2.taskSet.id}.mkString(",")}")
}
//把封裝好的taskSet,加入到任務調度隊列中。
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true}
//這個地方就是向資源管理器發出請求,請求任務的調度
backend.reviveOffers()
}
/*
*這個方法是位于CoarseGrainedSchedulerBackend類中,driver進程會想集群管理器發送請求資源的請求。
/
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}
當其收到這個請求時,其會調用這樣的方法。
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
//發送的請求滿足這個條件
case ReviveOffers =>
makeOffers()
case KillTask(taskId, executorId, interruptThread) =>
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.executorEndpoint.send(KillTask(taskId, executorId, interruptThread))
case None =>
// Ignoring the task kill since the executor is not registered.
logWarning(s"Attempted to kill task $taskId for unknown executor $executorId.")
}
}
/*
*這個方法是搜集集群上現在還在活著的機器的相關信息。并且進行封裝成WorkerOffer類,
/*
得到集群中空閑機器的信息后,我們通過此方法來篩選出滿足我們這次任務要求的機器,然后返回TaskDescription類
*這個類封裝了task與excutor的相關信息
/
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
//檢查work是否已經存在了,把不存在的加入到work調度池中
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// 打亂work機器的順序,以免每次分配任務時都在同一個機器上進行。避免某一個work計算壓力太大。
val shuffledOffers = Random.shuffle(offers)
//對于每一work,創建一個與其核數大小相同的數組,數組的大小決定了這臺work上可以并行執行task的數目.
val tasks = shuffledOffers.map(o => new ArrayBufferTaskDescription)
//取出每臺機器的cpu核數
val availableCpus = shuffledOffers.map(o => o.cores).toArray
//從task任務調度池中,按照我們的調度算法,取出需要執行的任務
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// 下面的這個循環,是用來標記task根據work的信息來標定數據本地化的程度的。當我們在yarn資源管理器,以--driver-mode配置
//為client時,我們就會在打出來的日志上看出每一臺機器上運行task的數據本地化程度。同時還會選擇每個task對應的work機器
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
//返回taskDescription對象
return tasks
}
/*
task選擇執行其任務的work其實是在這個函數中實現的,從這個可以看出,一臺work上其實是可以運行多個task,主要是看如何
*進行算法調度
/
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean = {
var launchedTask = false
//循環所有的機器,找適合此機器的task
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
//判斷其剩余的cpu核數是否滿足我們的最低配置,滿足則為其分配任務,否則不為其分配任務。
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
//這個for中的resourOffer就是來判斷其標記任務數據本地化的程度的。task(i)其實是一個數組,數組大小和其cpu核心數大小相同。
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
}
}
}
return launchedTask
}
以上完成了從TaskSet到task和work機器的綁定過程的所有任務。下面就是如何發送task到executor進行執行。在makeOffers()方法中調用了launchTasks方法,這個方法其實就是發送task作業到指定的機器上。只此,spark TaskSchedule的調度就此結束。
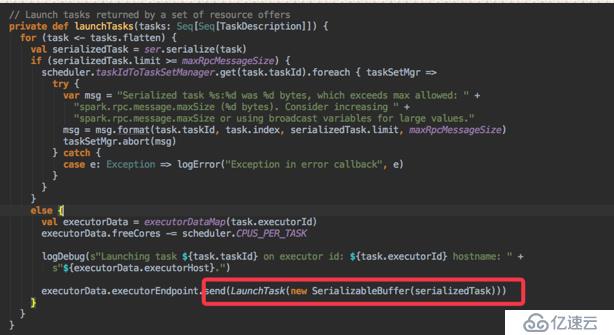
當TaskSchedule完成對task的調度時,task需要在work機器上來進行執行。此時,work機器就會啟動一個Backend的守護進程,用來完成與driver和資源管理器的通信。這個Backend就是CoarseGrainedExecutorBackend,啟動的main主函數為,從main函數中可以看出,其主要進行參數的解析,然后運行run方法。
def main(args: Array[String]) {
var driverUrl: String = null
var executorId: String = null
var hostname: String = null
var cores: Int = 0
var appId: String = null
var workerUrl: Option[String] = None
val userClassPath = new mutable.ListBuffer[URL]()
var argv = args.toList
while (!argv.isEmpty) {
argv match {
case ("--driver-url") :: value :: tail =>
driverUrl = value
argv = tail
case ("--executor-id") :: value :: tail =>
executorId = value
argv = tail
case ("--hostname") :: value :: tail =>
hostname = value
argv = tail
case ("--cores") :: value :: tail =>
cores = value.toInt
argv = tail
case ("--app-id") :: value :: tail =>
appId = value
argv = tail
case ("--worker-url") :: value :: tail =>
// Worker url is used in spark standalone mode to enforce fate-sharing with worker
workerUrl = Some(value)
argv = tail
case ("--user-class-path") :: value :: tail =>
userClassPath += new URL(value)
argv = tail
case Nil =>
case tail =>
// scalastyle:off println
System.err.println(s"Unrecognized options: ${tail.mkString(" ")}")
// scalastyle:on println
printUsageAndExit()
}
}
if (driverUrl == null || executorId == null || hostname == null || cores <= 0 ||
appId == null) {
printUsageAndExit()
}
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
System.exit(0)
}
/*
可以看出,run方法只是進行了一些需要運行task所需要的環境進行配置。并且創建相應的運行環境。
/
private def run(
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
appId: String,
workerUrl: Option[String],
userClassPath: Seq[URL]) {
Utils.initDaemon(log)
SparkHadoopUtil.get.runAsSparkUser { () =>
// Debug code
Utils.checkHost(hostname)
// Bootstrap to fetch the driver's Spark properties.
val executorConf = new SparkConf
val port = executorConf.getInt("spark.executor.port", 0)
val fetcher = RpcEnv.create(
"driverPropsFetcher",
hostname,
port,
executorConf,
new SecurityManager(executorConf),
clientMode = true)
val driver = fetcher.setupEndpointRefByURI(driverUrl)
val cfg = driver.askWithRetrySparkAppConfig
val props = cfg.sparkProperties ++ Seq[(String, String)](("spark.app.id", appId))
fetcher.shutdown()
// Create SparkEnv using properties we fetched from the driver.
val driverConf = new SparkConf()
for ((key, value) <- props) {
// this is required for SSL in standalone mode
if (SparkConf.isExecutorStartupConf(key)) {
driverConf.setIfMissing(key, value)
} else {
driverConf.set(key, value)
}
}
if (driverConf.contains("spark.yarn.credentials.file")) {
logInfo("Will periodically update credentials from: " +
driverConf.get("spark.yarn.credentials.file"))
SparkHadoopUtil.get.startCredentialUpdater(driverConf)
}
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
SparkHadoopUtil.get.stopCredentialUpdater()
}
}
其執行函數的調用過程如下: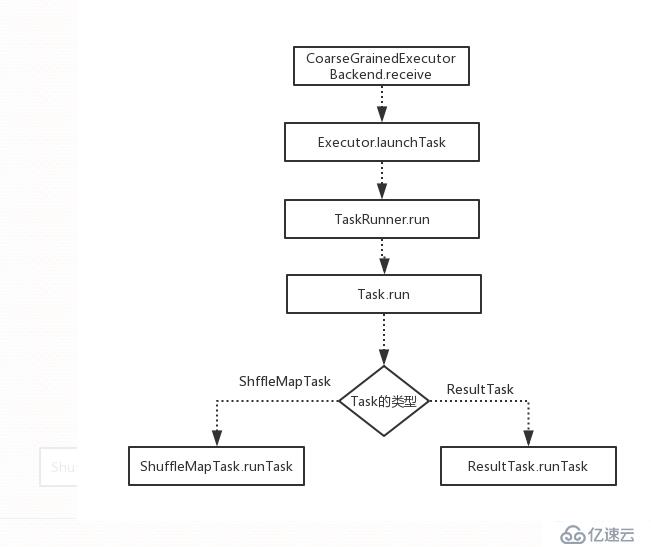
我們知道當我們完成TaskSchedule的調度時,是通過rpc發送了一個消息,如下圖所示,當work機器的Backend啟動以后,其會與driver進程進行rpc通信,當其收到LaunchTask的消息后,其會執行下面的代碼。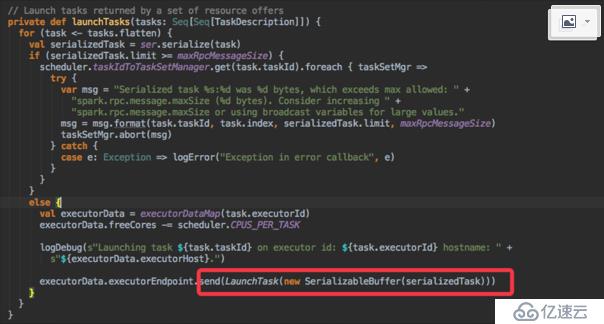
我們可以看出此方法存在很多的情況,根據接收到的不同的消息,執行不同的代碼。我們上面執行的是LaunchTask的請求。
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
case RegisterExecutorFailed(message) =>
exitExecutor(1, "Slave registration failed: " + message)
//提交任務時,執行這樣的操作。
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
//先反序列化
val taskDesc = ser.deserializeTaskDescription
logInfo("Got assigned task " + taskDesc.taskId)
//然后執行launchTask操作。
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
case KillTask(taskId, _, interruptThread) =>
if (executor == null) {
exitExecutor(1, "Received KillTask command but executor was null")
} else {
executor.killTask(taskId, interruptThread)
}
case StopExecutor =>
stopping.set(true)
logInfo("Driver commanded a shutdown")
// Cannot shutdown here because an ack may need to be sent back to the caller. So send
// a message to self to actually do the shutdown.
self.send(Shutdown)
case Shutdown =>
stopping.set(true)
new Thread("CoarseGrainedExecutorBackend-stop-executor") {
override def run(): Unit = {
// executor.stop() will call SparkEnv.stop() which waits until RpcEnv stops totally.
// However, if executor.stop() runs in some thread of RpcEnv, RpcEnv won't be able to
// stop until executor.stop() returns, which becomes a dead-lock (See SPARK-14180).
// Therefore, we put this line in a new thread.
executor.stop()
}
}.start()
}
Executor的相關源代碼,從源碼中我們可以看出,對于Task,其創建了一個TaskRunner的線程,并且把其放入到執行隊列中進行執行。
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
從下面可以看出,其定義的就是一個線程,那我們就看一下這個線程的run方法。
override def run(): Unit = {
//初始化線程運行需要的一些環境
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
//得到當前進程的類加載器
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
//更新相關的狀態
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {//反序列化類相關的依賴,得到相關的參數
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskProps)//更新依賴配置
updateDependencies(taskFiles, taskJars)
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
task.localProperties = taskProps
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
if (killed) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)//追蹤緩存數據的位置
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
taskStartCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException = true//運行任務的run方法來運行task,主要就是下面的task.run方法,它又會調用runTask方法來真正執行task,前面我們提到過,job變
//為stage有兩種,ShuffleMapStage和ResultStage,那么其對應的也有兩個Task:ShuffleMapTask和ResultTask,不同的task類型,執行不同的run方法。
val value = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
//下面就是根據上面的運行結果,來進行一些判斷和日志的打出
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
}
val taskFinish = System.currentTimeMillis()
val taskFinishCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the task has been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu - deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu - taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case ffe: FetchFailedException =>
val reason = ffe.toTaskFailedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case _: TaskKilledException =>
logInfo(s"Executor killed $taskName (TID $taskId)")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled))
case _: InterruptedException if task.killed =>
logInfo(s"Executor interrupted and killed $taskName (TID $taskId)")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled))
case CausedBy(cDE: CommitDeniedException) =>
val reason = cDE.toTaskFailedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: Throwable =>
// Attempt to exit cleanly by informing the driver of our failure.
// If anything goes wrong (or this was a fatal exception), we will delegate to
// the default uncaught exception handler, which will terminate the Executor.
logError(s"Exception in $taskName (TID $taskId)", t)
// Collect latest accumulator values to report back to the driver
val accums: Seq[AccumulatorV2[_, _]] =
if (task != null) {
task.metrics.setExecutorRunTime(System.currentTimeMillis() - taskStart)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.collectAccumulatorUpdates(taskFailed = true)
} else {
Seq.empty
}
val accUpdates = accums.map(acc => acc.toInfo(Some(acc.value), None))
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _: NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
// Don't forcibly exit unless the exception was inherently fatal, to avoid
// stopping other tasks unnecessarily.
if (Utils.isFatalError(t)) {
SparkUncaughtExceptionHandler.uncaughtException(t)
}
} finally {
runningTasks.remove(taskId)
}}
}
前面我們提到過,job變為stage有兩種,ShuffleMapStage和ResultStage,那么其對應的也有兩個Task:ShuffleMapTask和
ResultTask,不同的task類型,執行不同的Task.runTask方法。Task.run方法中調用了runTask的方法,這個方法在上面兩個Task類中都進行了重寫。
ShuffleMapTask的runTask方法
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
//首先進行一些初始化操作
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
//反序列化,這里的rdd,其實是我們進行shuffle之前的最后一個rdd,這個我們在前面已經說到的。
val (rdd, dep) = ser.deserialize[(RDD[], ShuffleDependency[, , ])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
//下面就是把每一個shuffle之前的stage的最后一個rdd進行寫入操作,但是沒有看到task執行我們寫的函數,也沒有看到其調用compute函數以及rdd之間的管道執行也沒有體現出來,往下看,會揭露這些問題的面紗。
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
對于上面紅色部分的問題,我們在這里進行詳細的解釋。RDD會根據依賴關系來形成一個有向無環圖,通過最后一個RDD和其依賴,我們就可以反向查找其對應的所有父類。如果沒有shuffle過程,那么其就會形成管道,形成管道的好處就是所有RDD的中間結果不需要進行存儲,直接就把我們的定義的多個函數串連起來,從輸入到輸出中間結果不需要存儲,節省了時間和空間。同時我們也知道RDD的中間結果可以持久化到內存或者硬盤上,spark對于這個是可以追蹤到的。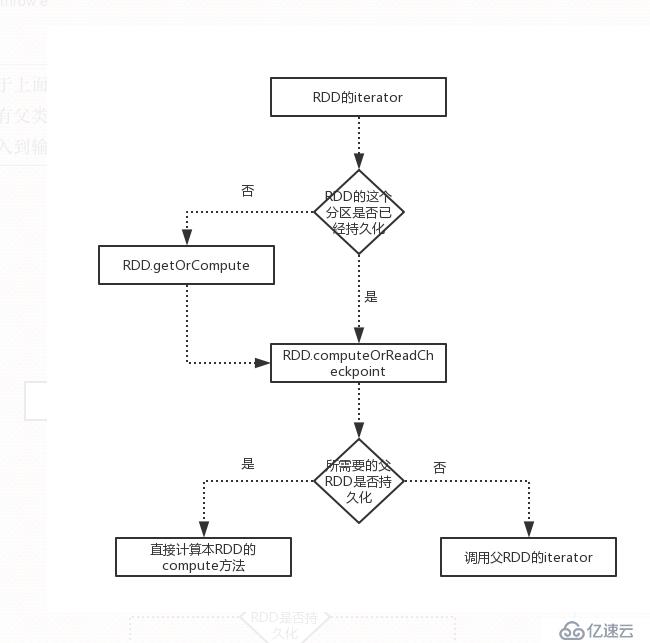
通過上面的分析,我們可以看出,executor中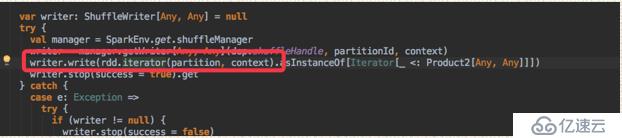
正是我們RDD往前回溯的開始。對于shuffle過程和ResultTask的runTask的執行過程以后會在慢慢跟進。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





