溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Spark原理的實例分析,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Hadoop存在缺陷:
基于磁盤,無論是MapReduce還是YARN都是將數據從磁盤中加載出來,經過DAG,然后重新寫回到磁盤中
計算過程的中間數據又需要寫入到HDFS的臨時文件
這些都使得Hadoop在大數據運算上表現太“慢”,Spark應運而生。
Spark的架構設計:
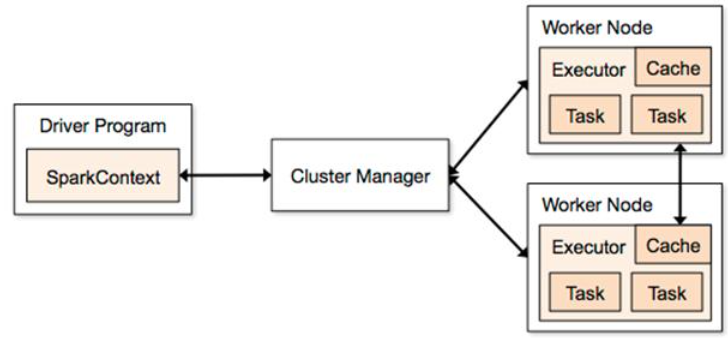
ClusterManager負責分配資源,有點像YARN中ResourceManager那個角色,大管家握有所有的干活的資源,屬于乙方的總包。
WorkerNode是可以干活的節點,聽大管家ClusterManager差遣,是真正有資源干活的主。
Executor是在WorkerNode上起的一個進程,相當于一個包工頭,負責準備Task環境和執行Task,負責內存和磁盤的使用。
Task是施工項目里的每一個具體的任務。
Driver是統管Task的產生與發送給Executor的,是甲方的司令員。
SparkContext是與ClusterManager打交道的,負責給錢申請資源的,是甲方的接口人。
整個互動流程是這樣的:
1 甲方來了個項目,創建了SparkContext,SparkContext去找ClusterManager申請資源同時給出報價,需要多少CPU和內存等資源。ClusterManager去找WorkerNode并啟動Excutor,并介紹Excutor給Driver認識。
2 Driver根據施工圖拆分一批批的Task,將Task送給Executor去執行。
3 Executor接收到Task后準備Task運行時依賴并執行,并將執行結果返回給Driver
4 Driver會根據返回回來的Task狀態不斷的指揮下一步工作,直到所有Task執行結束。
再看下圖加深下理解:
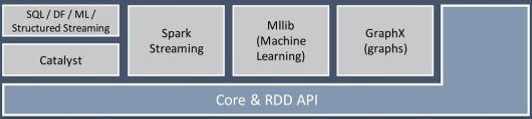
核心部分是RDD相關的,就是我們前面介紹的任務調度的架構,后面會做更加詳細的說明。
SparkStreaming:
基于SparkCore實現的可擴展、高吞吐、高可靠性的實時數據流處理。支持從Kafka、Flume等數據源處理后存儲到HDFS、DataBase、Dashboard中。
MLlib:
關于機器學習的實現庫,關于機器學習還是希望花點時間去系統的學習下各種算法,這里有一套基于Python的ML相關的博客教材http://blog.csdn.net/yejingtao703/article/category/7365067。
SparkSQL:
Spark提供的sql形式的對接Hive、JDBC、HBase等各種數據渠道的API,用Java開發人員的思想來講就是面向接口、解耦合,ORMapping、Spring Cloud Stream等都是類似的思想。
GraphX:
關于圖和圖并行計算的API,我還沒有用到過。
RDD(Resilient Distributed Datasets) 彈性分布式數據集
RDD支持兩種操作:轉換(transiformation)和動作(action)
轉換就是將現有的數據集創建出新的數據集,像Map;動作就是對數據集進行計算并將結果返回給Driver,像Reduce。
RDD中轉換是惰性的,只有當動作出現時才會做真正運行。這樣設計可以讓Spark更見有效的運行,因為我們只需要把動作要的結果送給Driver就可以了而不是整個巨大的中間數據集。
緩存技術(不僅限內存,還可以是磁盤、分布式組件等)是Spark構建迭代式算法和快速交互式查詢的關鍵,當持久化一個RDD后每個節點都會把計算分片結果保存在緩存中,并對此數據集進行的其它動作(action)中重用,這就會使后續的動作(action)變得跟迅速(經驗值10倍)。例如RDD0àRDD1àRDD2,執行結束后RDD1和RDD2的結果已經在內存中了,此時如果又來RDD0àRDD1àRDD3,就可以只計算最后一步了。
RDD之間的寬依賴和窄依賴:
窄依賴:父RDD的每個Partition只被子RDD的一個Partition使用。
寬依賴:父RDD的每個Partition會被子RDD的多個Partition使用。
寬和窄可以理解為褲腰帶,褲腰帶扎的緊下半身管的嚴所以只有一個兒子;褲腰帶幫的比較寬松下半身管的不禁會搞出一堆私生子,這樣就記住了。
對于窄依賴的RDD,可以用一個計算單元來處理父子partition的,并且這些Partition相互獨立可以并行執行;對于寬依賴完全相反。
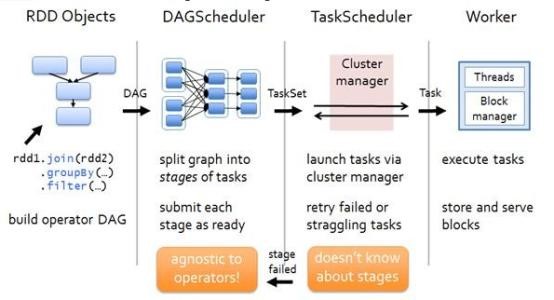
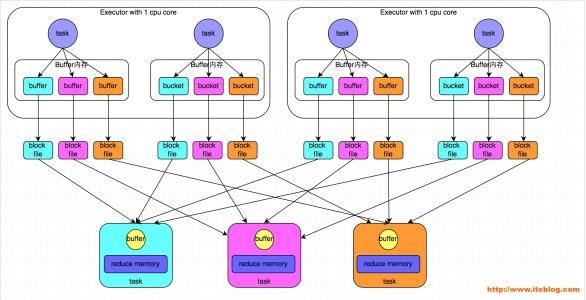
在故障回復時窄依賴表現的效率更高,兒子壞了可以通過重算爹來得到兒子,反正就這一個兒子當爹的恢復效率就是100%。但是對于寬依賴效率就很低了,如下圖:
用戶編排的代碼由一個個的RDD Objects組成,DAGScheduler負責根據RDD的寬依賴拆分DAG為一個個的Stage,買個Stage包含一組邏輯完全相同的可以并發執行的Task。TaskScheduler負責將Task推送給從ClusterManager那里獲取到的Worker啟動的Executor。
DAGScheduler(統一化的,Spark說了算):
詳細的案例分析下如何進行Stage劃分,請看下圖
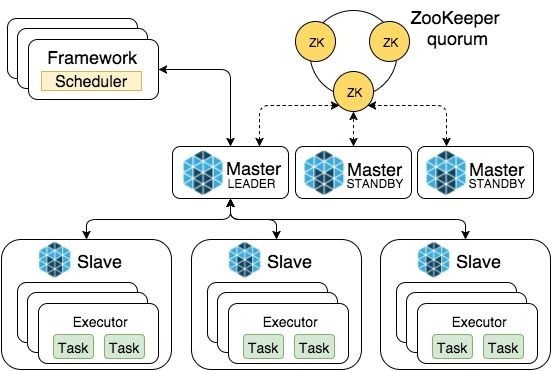
Worker部分采用Master/Slaver模式,Master是整個系統的核心部件所以用ZooKeeper做高可用性加固,Slaver真正創建Executor執行Task并將自己的物理計算資源匯報給Master,Master負責將slavers的資源按照策略分配給Framework。
Mesos資源調度分為粗粒度和細粒度兩種方式:
粗粒度方式是啟動時直接向Master申請執行全部Task的資源,并等所有計算任務結束后才釋放資源;細粒度方式是根據Task需要的資源不停的申請和歸還。兩個方式各有利弊,粗粒度的優點是調度成本小,但是會因木桶效應造成資源長期被霸占;細粒度沒有木桶效應,但是調度上的管理成本較高。
YARN模式:
在洗牌過程中StageA每個當前的Task會把自己的Partition按照stageB中Partition的要求做Hash產生stageB中task數量的Partition(這里特別強調是每個stageA的task),這樣就會有len(stageA.task)*len(stageB.task)這么多的小file在中間過程產生,如果要緩存RDD結果還需要維護到內存,下個stageB需要merge這些file又涉及到網絡的開銷和離散文件的讀取,所以說超過一定規模的任務用Hash Base模式是非常吃硬件的。
盡管后來Spark版本推出了Consolidate對基于Hash的模式做了優化,但是只能在一定程度上減少block file的數量,沒有根本解決上面的缺陷。
Sort Base Shuffle(spark1.2開始默認):
Sort模式下StageA每個Task會產生2個文件:內容文件和索引文件。內容文件是根據StageB中Partition的要求自己先sort好并生成一個大文件;索引文件是對內容文件的輔助說明,里面維護了不同的子partition之間的分界,配合StageB的Task來提取信息。這樣中間過程產生文件的數量由len(stageA.task)*len(stageB.task)減少到2* len(stageA.task),StageB對內容文件的讀取也是順序的。Sort帶來的另一個好處是,一個大文件對比與分散的小文件更方便壓縮和解壓,通過壓縮可以減少網絡IO的消耗。(PS:但是壓縮和解壓的過程吃CPU,所以要合理評估)
Sort和Hash模式通過spark.shuffle.manager來配置的。
Storage模塊:
存儲介質:內存、磁盤、Tachyon(這貨是個分布式內存文件,與Redis不一樣,Redis是分布式內存數據庫),存儲級別就是它們單獨或者相互組合,再配合一些容錯、序列化等策略。例如內存+磁盤。
負責存儲的組件是BlockManager,在Master(Dirver)端和Slaver(Executor)端都有BlockManager,分工不同。Slaver端的將自己的BlockManager注冊給Master,負責真正block;Master端的只負責管理和調度。
Storage模塊運行時內存默認占Executor分配內存的60%,所以合理的分配Executor內存和選擇合適的存儲級別需要平衡下Spark的性能和穩定。
Spark的出現很好的彌補了Hadoop在大數據處理上的不足,同時隨著枝葉不斷散開,出線了很多的衍生的接口模塊豐富了Spark的應用場景,也降低了Spark與其他技術的接入門檻。
以上就是Spark原理的實例分析,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。