溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
近日,在測試Flume結合Kafka結合Spark Streaming的實驗。今天把Flume與Spark的簡單結合做出來了,這里記錄一下,避免網友走彎路。有不周到的地方還希望路過的大神多多指教。
實驗比較簡單,分為兩部分:一、使用avro-client發送數據 二、使用netcat發送數據
首先Spark程序需要Flume的兩個jar包:
flume-ng-sdk-1.4.0、spark-streaming-flume_2.11-1.2.0
一、使用avro-client發送數據
1、 編寫Spark程序,該程序的功能是接收Flume事件
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
importorg.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.flume._
object FlumeEventTest{
defmain(args:Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF)
val hostname = args(0)
val port = args(1).toInt
val batchInterval = args(2)
val sparkConf = newSparkConf().setAppName("FlumeEventCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf,batchInterval)
valstream = FlumeUtils.createStream(ssc,hostname,port,StorageLevel.MEMORY_ONLY)
stream.count().map(cnt => "Received " + cnt + " flumeevents." ).print()
ssc.start()
ssc.awaitTermination()
}
}
2、 Flume配置文件參數
a1.channels = c1
a1.sinks = k1
a1.sources = r1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 9999
a1.sources.r1.type = avro
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
這里,使用avro向flume的44444端口發送數據;然后flume通過9999向Spark發送數據。
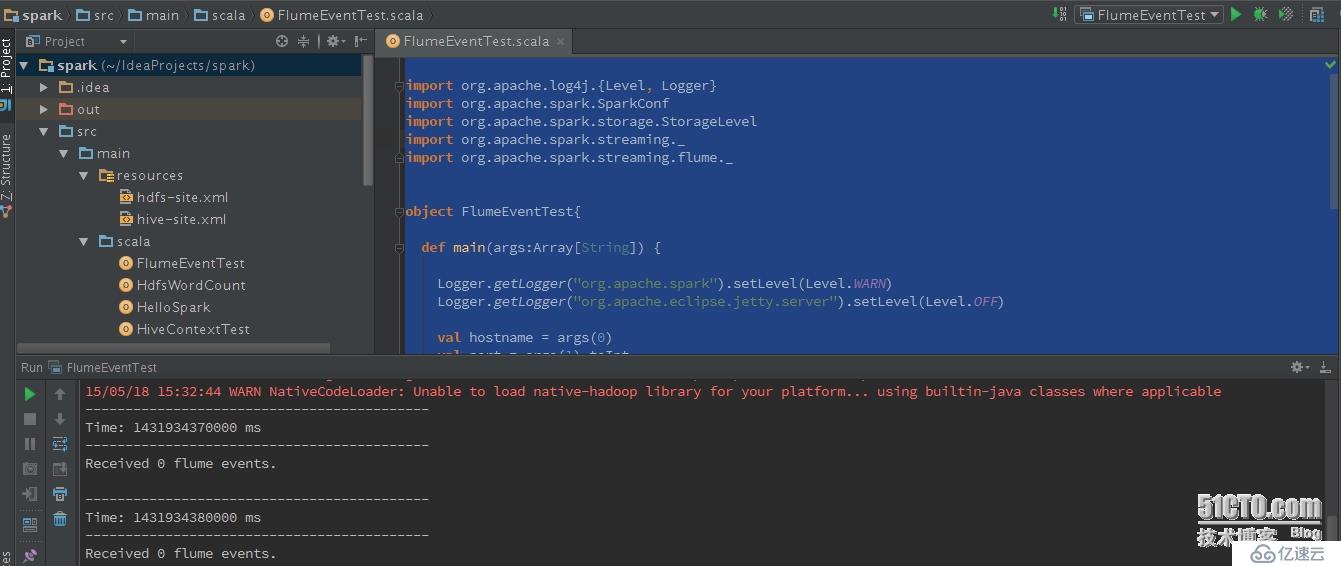
3、 運行Spark程序:
4、 通過Flume配置文件啟動Flumeagent
../bin/flume-ng agent --conf conf--conf-file ./flume-conf.conf --name a1
-Dflume.root.logger=INFO,console

Spark運行效果:
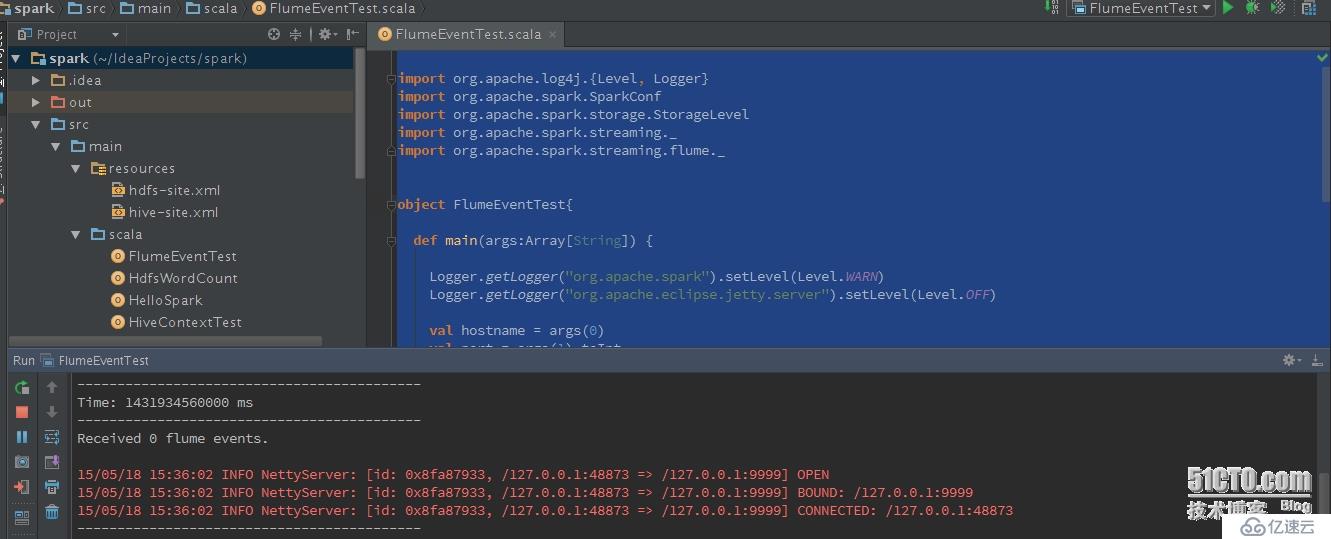
5、 使用avro來發送文件:
./flume-ng avro-client --conf conf -Hlocalhost -p 44444 -F/opt/servicesClient/Spark/spark/conf/spark-env.sh.template-Dflume.root.logger=DEBUG,console
Flume agent效果:

Spark效果:
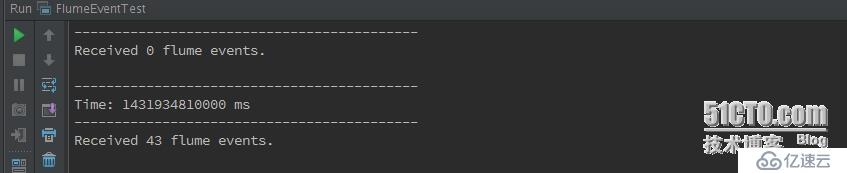
二、使用netcat發送數據
1、 Spark程序同上
2、 配置Flume參數
a1.channels = c1
a1.sinks = k1
a1.sources = r1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 9999
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
這里,使用telnet作為Flume的數據源
3、 運行Spark程序同上
4、 通過Flume配置文件啟動Flumeagent
../bin/flume-ng agent --conf conf--conf-file ./flume-conf.conf --name a1
-Dflume.root.logger=INFO,console

注意:這里使用netcat作為Flume的數據源,注意與avro作為源的效果區別
5、 使用telnet發送數據
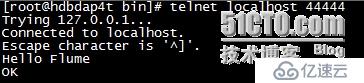
Spark效果:
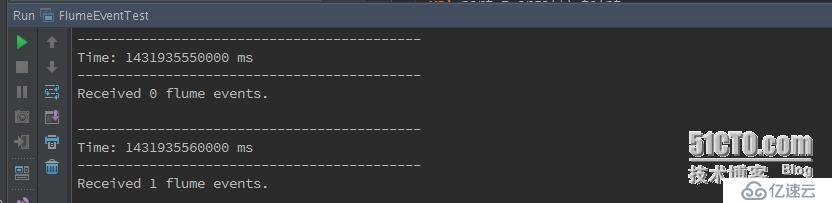
這是兩個比較簡單的demo,如果真正在項目中使用Flume來收集數據,使用Kafka作為分布式消息隊列,使用Spark Streaming實時計算,還需要詳細研究Flume和Spark流計算。
前段時間給部門做培訓,演示了Spark Streaming的幾個例子:文本處理、網絡數據處理、stateful操作和window操作,這幾天有時間整理整理,分享給大家。包括Spark MLlib的兩個簡單demo:基于K-Means的用戶分類和基于協同過濾的電影推薦系統。
今天看了斯坦福Andrew Ng教授的ML課程,講的很棒,這里把鏈接分享給大家:
http://open.163.com/special/opencourse/machinelearning.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





