溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關基于Milvus實現向量與結構化數據混合查詢的示例分析,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
通過深度學習的神經網絡模型,可以將圖片、視頻、語音、還有文本等非結構化數據轉換為特征向量。除了結構化的向量,這些數據往往也需添加其他屬性。如人臉圖片,可以添加性別、是否戴眼鏡、圖片抓取時間等標簽;文本可以添加語言類型、語料分類、文本創建時間等標簽。
以往,人們通常將特征向量存入結構化的標簽屬性表。但傳統數據庫無法針對海量、高維特征向量進行有效的搜索。這時就需要一個特征向量數據庫,用來高效存儲、檢索特征向量。
Milvus 是一款向量搜索引擎,可以輕松實現針對海量向量的高性能檢索。結合傳統關系型數據庫如 Postgres ,用其存儲 Milvus 對向量的唯一標識 ID 和向量的對應屬性。將 Milvus 向量檢索結果,在 Postgres 中進一步查詢,就能快速得出混合查詢結果,具體解決方案如下:
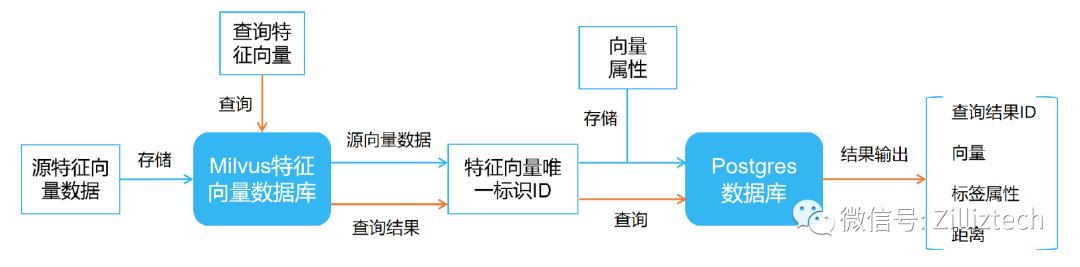
1、特征向量存儲
如上圖藍色實線,其表示 Milvus 混合查詢的特征向量存儲過程。首先,將源特征向量數據存入 Milvus 特征向量數據庫, Milvus 會給返回每個源向量數據對應的 ID 。然后將每個特征向量的唯一標識 ID 與其標簽屬性存儲至關系型數據庫,如 Postgres ,至此完成特征向量與標簽屬性的存儲。
2、特征向量檢索
如上圖橙色實線,其表示 Milvus 混合查詢的特征向量檢索過程。向 Milvus 中傳入需要查詢的特征向量數據, Milvus 會得出與搜索向量相似度最高的查詢結果 ID ,利用該結果 ID 到 Postgres 中進行查詢,最終得出檢索向量的混合查詢結果。
至此,你可能會有疑問,為什么不直接將特征向量和對應屬性存儲在關系型數據庫中呢?接下來將用 Milvus 對 ANN_SIFT1B 中的一億數據進行測試,為你解答,參考鏈接[1]。
1、特征向量數據集
本次實現的 Mivus 混合查詢,其特征向量提取自 ANN_SIFT1B 中 Base Set 文件中的一億數據( 128 維)。特征向量檢索時從 Query set 中提取,假定 ANN_SIFT1B 數據集為人臉特征向量,并為每個向量添加性別、是否戴眼鏡、圖片抓取時間的標簽:
# 提取 Base Set 文件中的一億數據,以用于導入 Milvusvectors = load_bvecs_data(FILE_PATH,10000000)# 為向量隨機生成性別、是否戴眼鏡、圖片抓取時間標簽sex = random.choice(['female','male'])get_time = fake.past_datetime(start_date="-120d", tzinfo=None)is_glasses = random.choice(['True','False'])
2、特征向量存儲
將一億數據導入 Milvus ,其返回的 ids 是向量對應的唯一表示 ID ,將 ids 與向量的標簽存入 Postgres ,當然,原始特征向量也可以存入 Postgres (可選):
# 將一億原始數據導入 Milvusstatus, ids = milvus.add_vectors(table_name=MILVUS_TABLE, records=vectors)# 將 ids 與向量的標簽存入 Postgressql = "INSERT INTO PG_TABLE_NAME VALUES(ids, sex, get_time, is_glasses);"cur.execute(sql)
3、特征向量檢索
向 Milvus 中傳入需要搜索的向量。設定 TOP_K=10 以及 DISTANCE_THRESHOLD=1 (可根據需求修改), TOP_K 表示搜索與查詢向量相似度最高的前 10 個結果,DISTANCE_THRESHOLD表示查詢向量與搜索結果向量的距離閾值。
ANN_SIFT1B 中采用歐氏距離計算,參數設定后 Milvus 將返回查詢結果的 ids ,利用該 ids 到 Postgres 中進行查詢,最終混合查詢結果。
# 根據 query_location 從 Query set 中提取需要搜索的向量vector = load_query_list(QUERY_PATH,query_location)# 向 Milvus 中傳入需要搜索的向量 vectorsstatus, results = milvus.search_vectors(table_name = MILVUS_TABLE,query_records=vector, top_k=top_k)# 利用 Milvus 返回的 results.ids 到 Postgres 中進行查詢sql = "select * from PG_TABLE_NAME where ids = results.ids ;"cur.execute(sql)
在對一億數據進行混合查詢時, Milvus 特征向量搜索僅需 70ms ,在 Postgres 中對 Milvus 搜索結果的 ids 進行查詢不超過 7ms 。
總的來說,利用 Milvus 特征向量數據庫,可以快速實現向量與結構化數據的混合查詢。若僅使用傳統的關系型數據庫進行向量查詢,不僅大規模向量數據存儲難,而且無法高性能完成特征向量檢索。
| Milvus 特征向量搜索時間 | Postgres 搜索ids時間 |
|---|---|
| 70 ms | 1 ms ~ 7 ms |
這里實現了基于 Milvus 的混合查詢。在一億特征向量數據集的情況下,混合查詢時間不超過 77 ms 。
并且基于 Milvus 易管易用的特性,通過參考 Milvus 混合查詢方案[2] 所提供的工具,能輕松實現向量和結構化數據的混合查詢,更好的支持業務需求。
關于基于Milvus實現向量與結構化數據混合查詢的示例分析就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





