溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了C++ OpenCV圖像分割之如何實現高斯混合模型,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
前言
Gaussian Mixture Model (GMM)。事實上,GMM 和 k-means 很像,不過 GMM 是學習出一些概率密度函數來(所以 GMM 除了用在 clustering 上之外,還經常被用于 density estimation ),簡單地說,k-means 的結果是每個數據點被 assign 到其中某一個 cluster 了,而 GMM 則給出這些數據點被 assign 到每個 cluster 的概率,又稱作 soft assignment 。
得出一個概率有很多好處,因為它的信息量比簡單的一個結果要多,比如,我可以把這個概率轉換為一個 score ,表示算法對自己得出的這個結果的把握。也許我可以對同一個任務,用多個方法得到結果,最后選取“把握”最大的那個結果;另一個很常見的方法是在諸如疾病診斷之類的場所,機器對于那些很容易分辨的情況(患病或者不患病的概率很高)可以自動區分,而對于那種很難分辨的情況,比如,49% 的概率患病,51% 的概率正常,如果僅僅簡單地使用 50% 的閾值將患者診斷為“正常”的話,風險是非常大的,因此,在機器對自己的結果把握很小的情況下,會“拒絕發表評論”,而把這個任務留給有經驗的醫生去解決。
高斯混合模型--GMM(Gaussian Mixture Model)
統計學習的模型有兩種,一種是概率模型,一種是非概率模型。
所謂概率模型,是指訓練模型的形式是P(Y|X)。輸入是X,輸出是Y,訓練后模型得到的輸出不是一個具體的值,而是一系列的概率值(對應于分類問題來說,就是輸入X對應于各個不同Y(類)的概率),然后我們選取概率最大的那個類作為判決對象(軟分類--soft assignment)。所謂非概率模型,是指訓練模型是一個決策函數Y=f(X),輸入數據X是多少就可以投影得到唯一的Y,即判決結果(硬分類--hard assignment)。
所謂混合高斯模型(GMM)就是指對樣本的概率密度分布進行估計,而估計采用的模型(訓練模型)是幾個高斯模型的加權和(具體是幾個要在模型訓練前建立好)。每個高斯模型就代表了一個類(一個Cluster)。對樣本中的數據分別在幾個高斯模型上投影,就會分別得到在各個類上的概率。然后我們可以選取概率最大的類所為判決結果。
從中心極限定理的角度上看,把混合模型假設為高斯的是比較合理的,當然,也可以根據實際數據定義成任何分布的Mixture Model,不過定義為高斯的在計算上有一些方便之處,另外,理論上可以通過增加Model的個數,用GMM近似任何概率分布。
代碼演示
我們再新建一個項目名為opencv--GMM,按照配置屬性(VS2017配置OpenCV通用屬性),然后在源文件寫入#include和main方法.
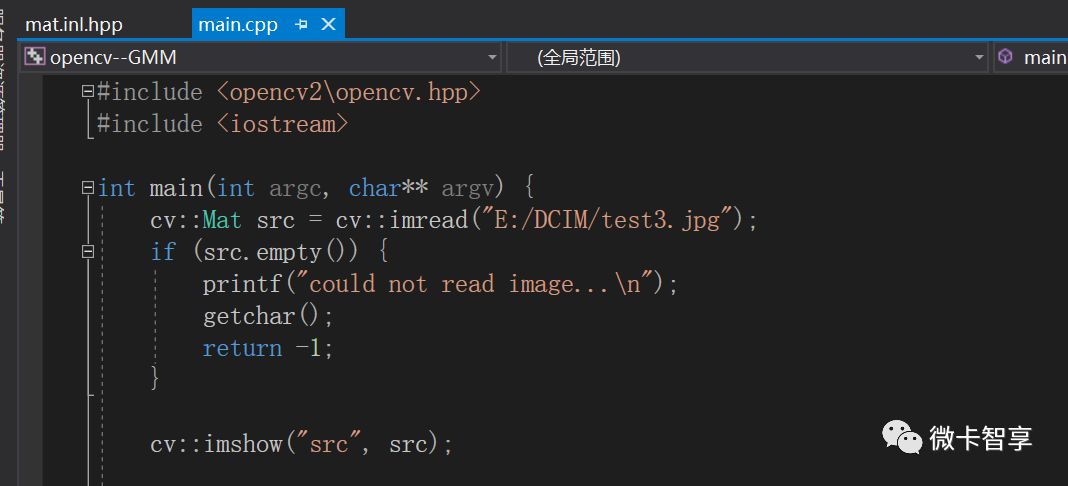
先初始化數據

獲取源圖像的寬,高和圖像的通道數及總的像素點數,并定義要用的Mat
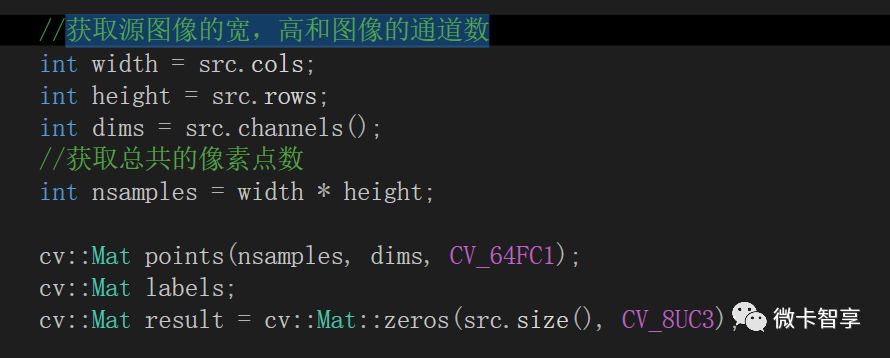
將圖像的RGB像素數轉換為樣本數據
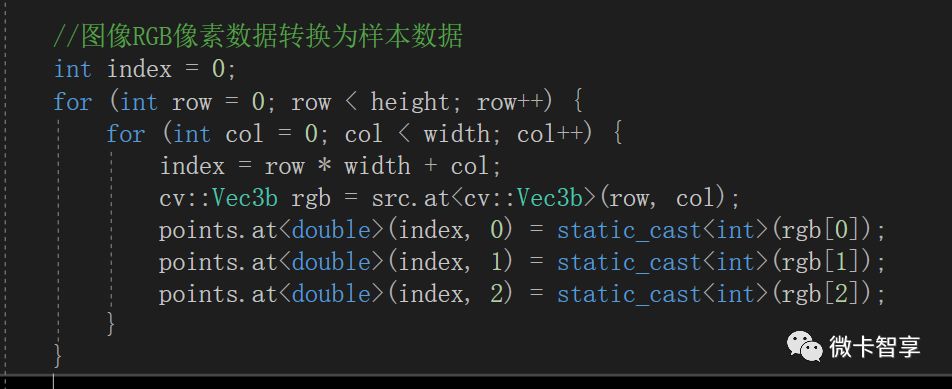
通過EM方法對像素進行訓練
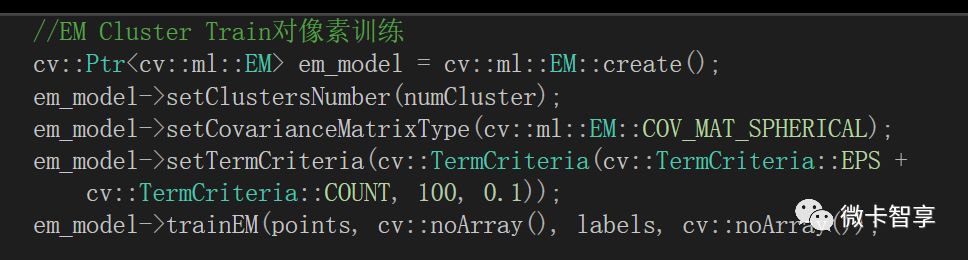
對每個像素標記顏色和顯示
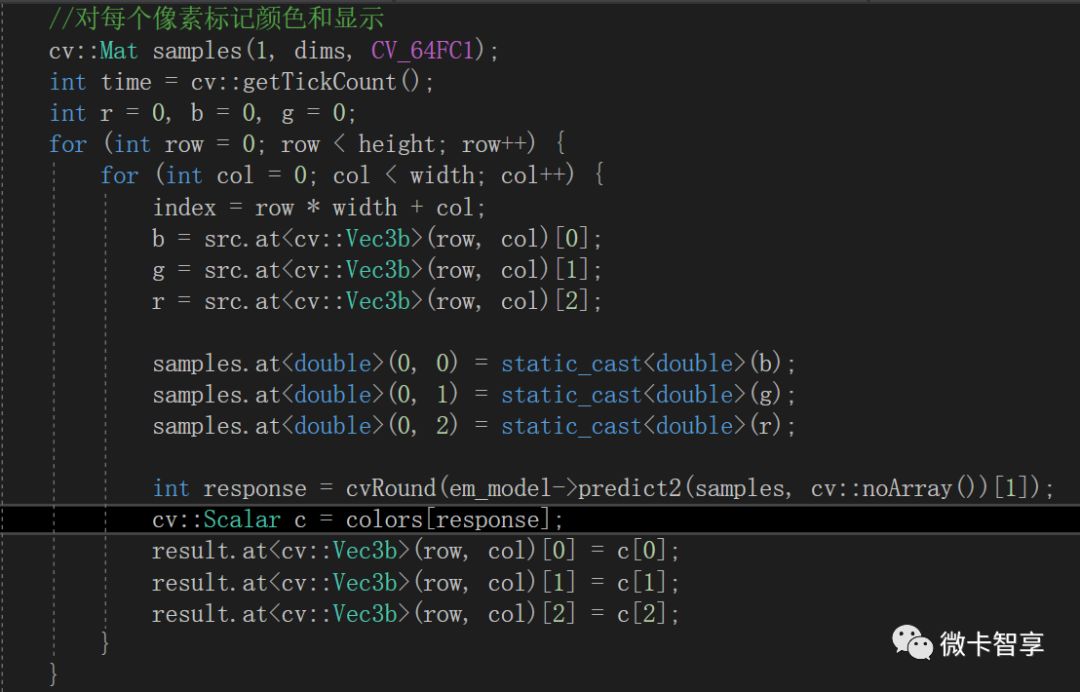
打印出用的時間和顯示最終圖像
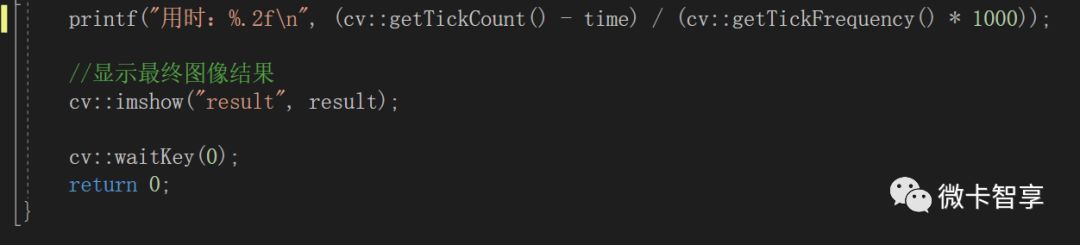
我們來看一下運行后的結果

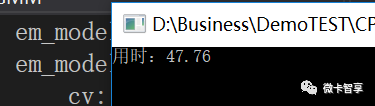
因為高斯混合模型是通過EM進行數據訓練進行分析的,所以對數據進行訓練就需要耗時操作,下面就是我們得到上圖結果所用到的時間,花了47秒多,相對來說是比較耗時的操作了。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“C++ OpenCV圖像分割之如何實現高斯混合模型”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





