溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“PostgreSQL的DB buffer問題分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
首先今天要說的這部分buffer 如果要用其他的數據庫來理解的話,ORALCE 中有PGA 和 SGA, 今天要說的這部分就是 SGA, 數據庫中共享內存。而postgresql 中這塊共享內存和其他的數據庫不同的地方,在于大部分數據庫MYSQL 設置自己的 innodb_buffer_pool_size 一般是要設置成總內存的 60-80% , SQL SERVER 一般也會吃進大部分系統內存,并且一般不會再釋放,我們可以理解,這些數據庫(mysql, oracle ,sql server)都有自己的內存管理器,并且傾向性的獨占。
反觀postgresql 一般建議在設置share_buffer 的建議是系統總內存的25%,這與上邊的三個數據庫相比有點背道而馳的趕腳。所以就引出了今天的問題,到底POSTGRESQL 在內存的使用和緩存的使用中有什么“與眾不同”。
select current_setting(name),* from pg_settings where name like 'share%';
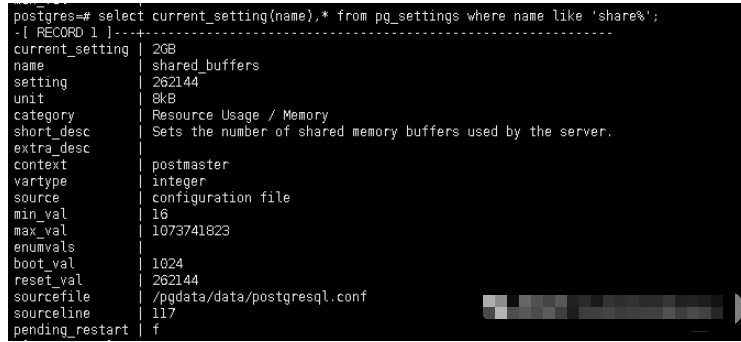
postgresql 在大部分的情況中是傾向于使用OS 的緩沖來完成工作的,也就是讀取的數據都是要經過OS CACHE 的,跳過system cache 大致只有WAL writes。那問題是為什么要需要buffer cache ,如果直接可以使用使用OS cache 不就可以了。
那到底為什么要有buffer cache 原因主要在于buffer cache 有數據庫獨有的算法,在postgresql 的 buffer cache 中可以通過近似LRU 的算法將經常被用到的數據,“粘”在buffer cache 中,增加數據庫自身緩沖的利用率。
那可能又有問題提出,為什么PG 建議將buffer cache 設置到總體的內存的25%,而不是更大,更大不是更好嗎? 實際上根據 PG9.X PG 10 的相關書籍中提到的,如果這樣可能適得其反,書中提出的觀點是,PG 在操作時,有一部分是通過系統的CACHE 會更直接。
所以這就引出另一個問題,我們怎么設置共享內存(LINUX系統中的)讓系統更好的為數據庫服務,下面是一個腳本,可以得到設置LINUX 共享內存的大小值
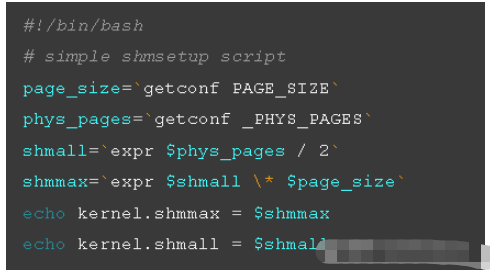
./shmsetup >> /etc/sysctl.conf
這位同學又問了另一個問題,就是既然PG 有 buffer cache 和 OS cache 那這樣的設計會浪費內存的空間。
這里想說的是不會,大家可以想一下,數據庫的系統buffer cache 是可以黏住經常訪問的數據,而系統的的緩沖是沒有這樣的功能的,也就是系統的緩沖和數據庫的BUFFER CACHE 之間存在相同的數據的可能性是比較低,一個數據會經常被訪問才能放到緩沖中,而如果一個經常被訪問的數據放到數據庫的 BUFFER 中,就不會再訪問系統的CACHE ,所以系統就會清理掉他,系統的緩沖和數據庫的緩沖能存在一樣的數據的可能性就比較低。
“PostgreSQL的DB buffer問題分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





