溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
r語言中DBSCAN算法的實現是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
DBSCAN(Density-BasedSpatial Clustering of Applications with Noise),一種基于密度的聚類方法,即找到被低密度區域分離的稠密區域,要求聚類空間中的一定區域內所包含對象(點或其他空間對象)的數目不小于某一給定閾值。
一、兩個參數。
1,距離參數(Eps)
2,鄰域內點最少個數(MinPts)
二、根據基于中心的密度進行點分類。
密度的基于中心的方法使得點分為三類:
1, 核心點。稠密區域內部的點。該點以Eps為半徑的區域內點的個數不少于MinPts(包括自身)。
2, 邊界點。稠密區邊緣上的點,不是核心點,但在某個或多個核心點鄰域內。
3, 噪聲點。稀疏區域中的點,既非核心點也非邊界點。
4, 密度可達。如果點p在核心點q的Eps鄰域內,則稱p是從q出發可以直接密度可達。如果存在點鏈p1,p2, …, pn,p1=q,pn=p,pi+1是從pi直接密度可達,則稱點p是從q關于r和M密度可達的,密度可達是單向的。
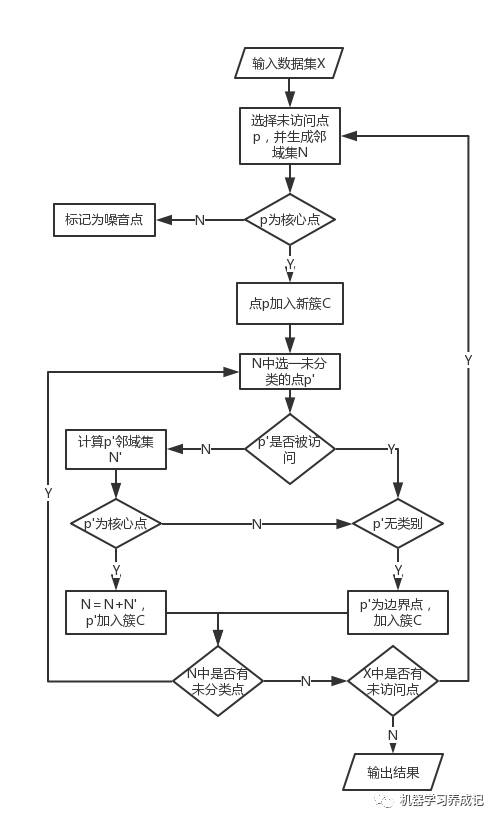
算法流程
從某點出發,將密度可達的點聚為一類,不斷進行區域擴張,直至所有點都被訪問。
R語言實現
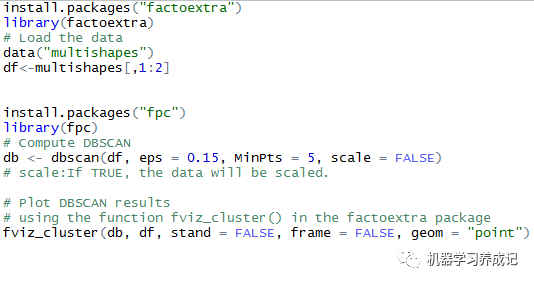
在R中實現DBSCAN聚類,可以使用fpc包中的dbscan()函數。在下面的例子中,我們使用factoextra包中的數據集multishapes進行演示。
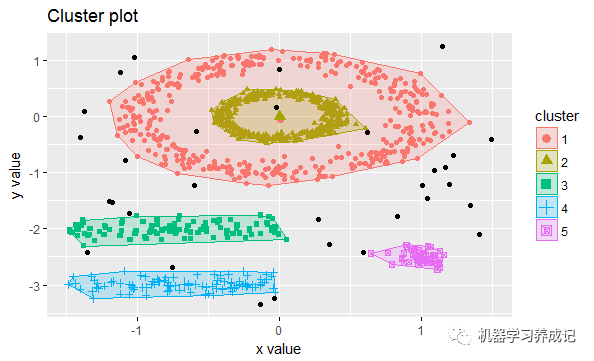
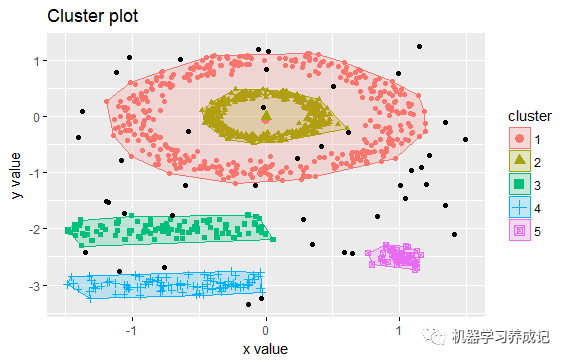
如下可查看聚類后的結果:
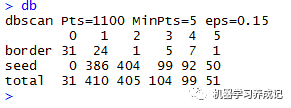
具體每個樣本點的分類結果,可用db$cluster查看,其中0表示噪聲點,如下隨機顯示50個點的分類結果:

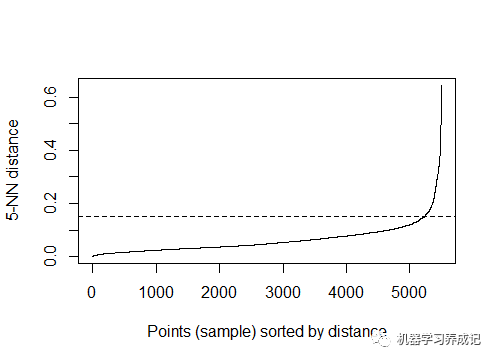
選擇最優的Eps值
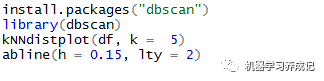
方法為計算每個點到其最近鄰的k個點的平均距離。k的取值根據MinPts由用戶指定。R語言中,使用dbscan包中的kNNdistplot()函數進行計算。
由圖可知,拐點處基本在0.15左右,因此可以認為最優Eps值在0.15左右。
自定義距離公式
dbscan()函數中計算距離公式為歐式距離,在一些特定的場合無法使用,比如要計算地圖上兩點的距離,就要應用特定的計算地圖上兩點的距離公式。
R里面的很多函數都是開源的,因此,直接運行fpc::dbscan可以看到此函數的原程序。我們用geosphere包中的distm()函數對原程序中的距離計算公式進行修改,實現地圖上兩點距離的計算。
將原程序中的distcomb函數改為如下形式:

將修改過的dbscan函數重新命名為disdbscan,重新將數據進行聚類:

DBSCAN優缺點
優點:
(1)聚類速度快,且能夠有效處理噪聲點。
(2)能發現任意形狀的空間聚類。
(3)聚類結果幾乎不依賴于點遍歷順序。
(4)不需要輸入要劃分的聚類個數。
缺點:
(1)當數據量增大時,要求較大的內存支持I/O消耗也很大;
(2)當空間聚類的密度不均勻、聚類間距差相差很大時,聚類質量較差。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





