溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Flink 1.10Container環境怎么配置”,在日常操作中,相信很多人在Flink 1.10Container環境怎么配置問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Flink 1.10Container環境怎么配置”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
容器管理系統的演變
如資源隔離,因為 YARN 是以 Java 為基礎開發的,所以它很多資源方面的隔離有一些受限。
另外對 GPU 支持不夠,當然現在的 YARN 3.0 已經對 GPU 的調度和管理有一定支持,但之前版本對GPU 支持不是很好。
Flink on K8S intro
部署集群
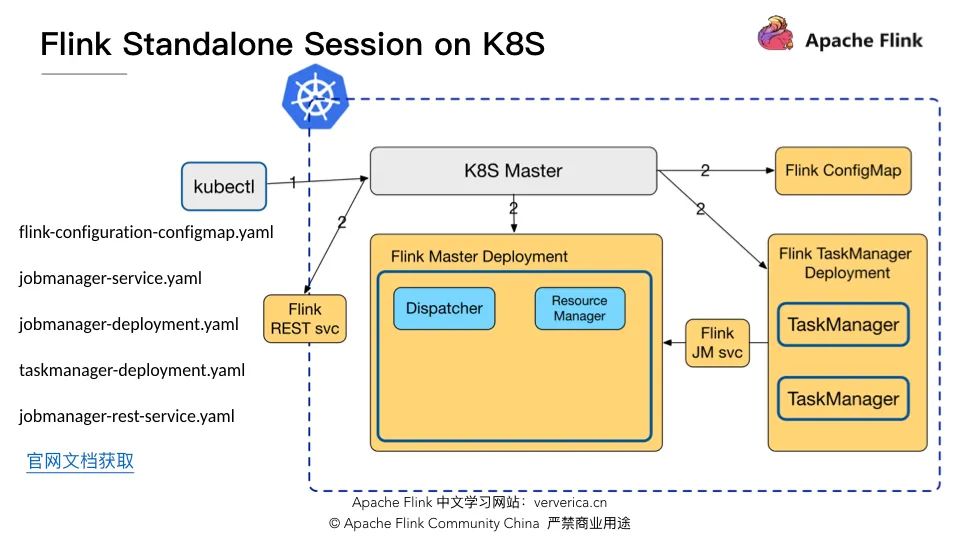
kubectl create -f flink-configuration-configmap.yamlkubectl create -f jobmanager-service.yamlkubectl create -f jobmanager-deployment.yamlkubectl create -f taskmanager-deployment.yaml
作業提交
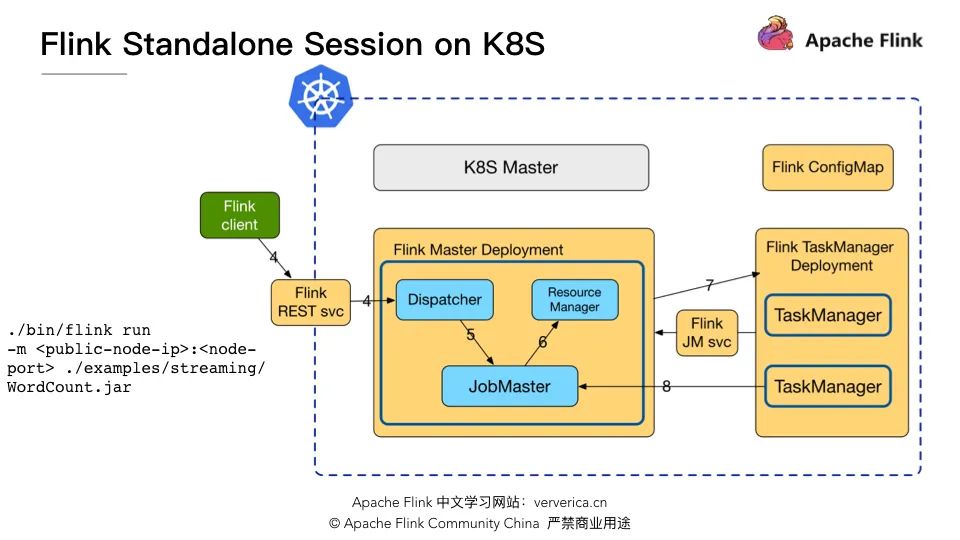
./bin/flink run -m : ./examples/streaming/WordCount.jar
優點是無需修改 Flink 源碼,僅僅只需預先定義一些yaml 文件,集群就可以啟動,互相之間的通信完全不經過 K8S Master;
缺點是資源需要預先申請無法動態調整,而 Flink on YARN 是可以在提交作業時聲明集群所需的 JM 和 TM 的資源。

Flink on K8S 實戰分享
日志搜集
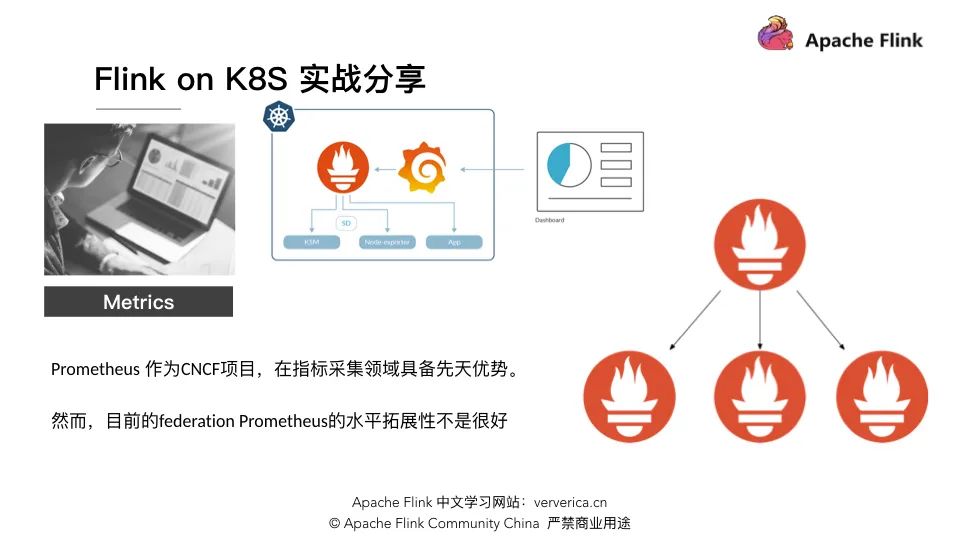
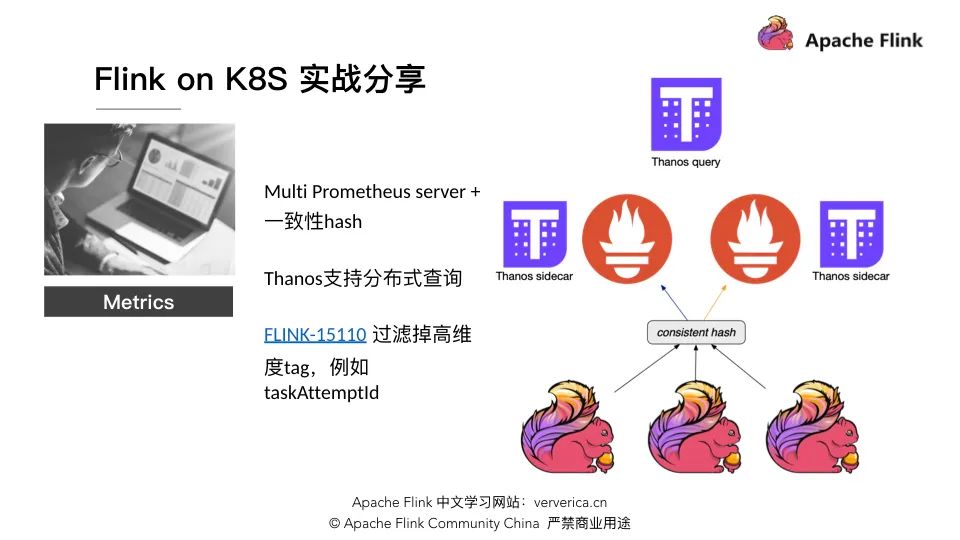
Metrics
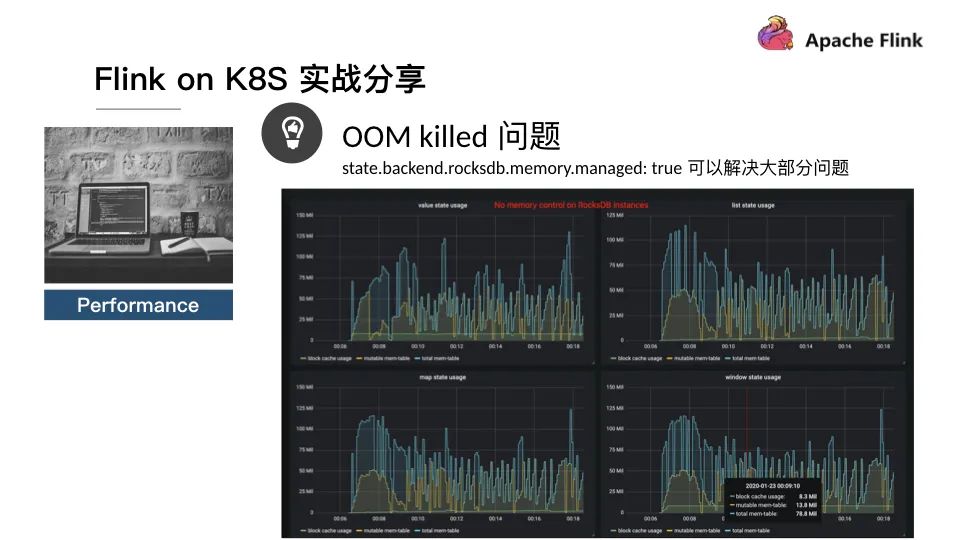
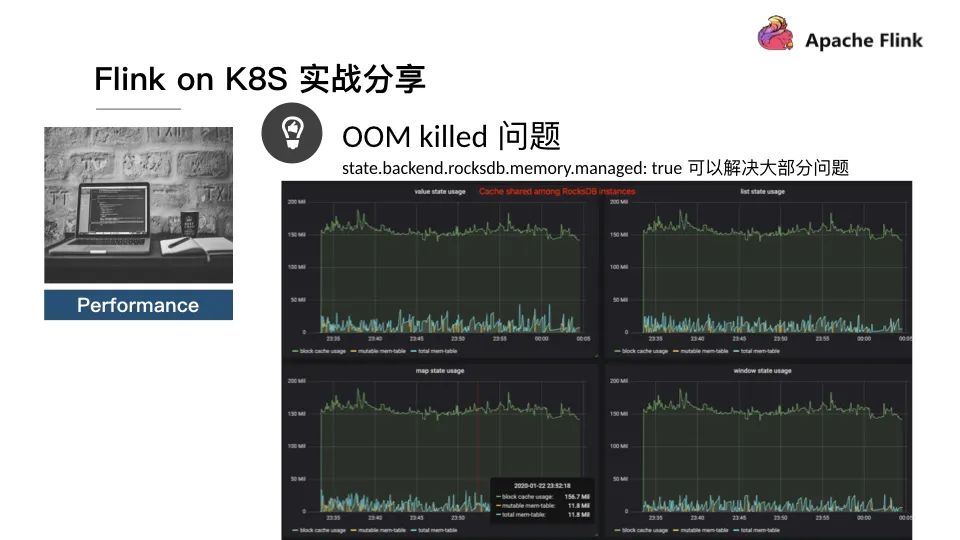
性能



OOM killed


Demo
apiVersion: apps/v1kind: Deploymentmetadata: name: flink-taskmanagerspec: replicas: 2 selector: matchLabels: app: flink component: taskmanager template: metadata: labels: app: flink component: taskmanager spec: containers: - name: taskmanager image: reg.docker.alibaba-inc.com/chagan/flink:latest workingDir: /opt/flink command: ["/bin/bash", "-c", "$FLINK_HOME/bin/taskmanager.sh start; \ while :; do if [[ -f $(find log -name '*taskmanager*.log' -print -quit) ]]; then tail -f -n +1 log/*taskmanager*.log; fi; done"] ports: - containerPort: 6122 name: rpc livenessProbe: tcpSocket: port: 6122 initialDelaySeconds: 30 periodSeconds: 60 volumeMounts: - name: flink-config-volume mountPath: /opt/flink/conf/ - name: state-volume mountPath: /dump/1/state securityContext: runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary volumes: - name: flink-config-volume configMap: name: flink-config items: - key: flink-conf.yaml path: flink-conf.yaml - key: log4j.properties path: log4j.properties - name: state-volume hostPath: path: /dump/1/state type: DirectoryOrCreate
Q&A 問答
到此,關于“Flink 1.10Container環境怎么配置”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





