溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹怎么搭建Flink開發IDEA環境,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
一.IDEA開發環境
1.pom文件設置
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.7.6</hadoop.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!-- <arg>-make:transitive</arg> -->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.apache.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>2.flink開發流程
Flink具有特殊類DataSet并DataStream在程序中表示數據。您可以將它們視為可以包含重復項的不可變數據集合。在DataSet數據有限的情況下,對于一個DataStream元素的數量可以是無界的。
這些集合在某些關鍵方面與常規Java集合不同。首先,它們是不可變的,這意味著一旦創建它們就無法添加或刪除元素。你也不能簡單地檢查里面的元素。
集合最初通過在弗林克程序添加源創建和新的集合從這些通過將它們使用API方法如衍生map,filter等等。
Flink程序看起來像是轉換數據集合的常規程序。每個程序包含相同的基本部分:
1.獲取execution environment,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.加載/創建初始化數據
DataStream<String> text = env.readTextFile(file:///path/to/file);
3.指定此數據的轉換
val mapped = input.map { x => x.toInt }4.指定放置計算結果的位置
writeAsText(String path) print()
5.觸發程序執行
在local模式下執行程序
execute()
將程序達成jar運行在線上
./bin/flink run \ -m node21:8081 \ ./examples/batch/WordCount.jar \ --input hdfs:///user/admin/input/wc.txt\ --outputhdfs:///user/admin/output2\
二.Wordcount案例
1.Scala代碼
package com.xyg.streaming
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc:
*/
object SocketWindowWordCountScala {
def main(args: Array[String]) : Unit = {
// 定義一個數據類型保存單詞出現的次數
case class WordWithCount(word: String, count: Long)
// port 表示需要連接的端口
val port: Int = try {
ParameterTool.fromArgs(args).getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'")
return
}
}
// 獲取運行環境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 連接此socket獲取輸入數據
val text = env.socketTextStream("node21", port, '\n')
//需要加上這一行隱式轉換 否則在調用flatmap方法的時候會報錯
import org.apache.flink.api.scala._
// 解析數據, 分組, 窗口化, 并且聚合求SUM
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("count")
// 打印輸出并設置使用一個并行度
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
}2.Java代碼
package com.xyg.streaming;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc: 使用flink對指定窗口內的數據進行實時統計,最終把結果打印出來
* 先在node21機器上執行nc -l 9000
*/
public class StreamingWindowWordCountJava {
public static void main(String[] args) throws Exception {
//定義socket的端口號
int port;
try{
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch (Exception e){
System.err.println("沒有指定port參數,使用默認值9000");
port = 9000;
}
//獲取運行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//連接socket獲取輸入的數據
DataStreamSource<String> text = env.socketTextStream("node21", port, "\n");
//計算數據
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word:splits) {
out.collect(new WordWithCount(word,1L));
}
}
})//打平操作,把每行的單詞轉為<word,count>類型的數據
//針對相同的word數據進行分組
.keyBy("word")
//指定計算數據的窗口大小和滑動窗口大小
.timeWindow(Time.seconds(2),Time.seconds(1))
.sum("count");
//把數據打印到控制臺,使用一個并行度
windowCount.print().setParallelism(1);
//注意:因為flink是懶加載的,所以必須調用execute方法,上面的代碼才會執行
env.execute("streaming word count");
}
/**
* 主要為了存儲單詞以及單詞出現的次數
*/
public static class WordWithCount{
public String word;
public long count;
public WordWithCount(){}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}3.運行測試
首先,使用nc命令啟動一個本地監聽,命令是:
[admin@node21 ~]$ nc -l 9000
通過netstat命令觀察9000端口。netstat -anlp | grep 9000,啟動監聽如果報錯:-bash: nc: command not found,請先安裝nc,在線安裝命令:yum -y install nc。
然后,IDEA上運行flink官方案例程序
node21上輸入
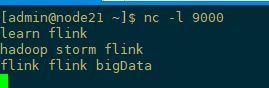
IDEA控制臺輸出如下
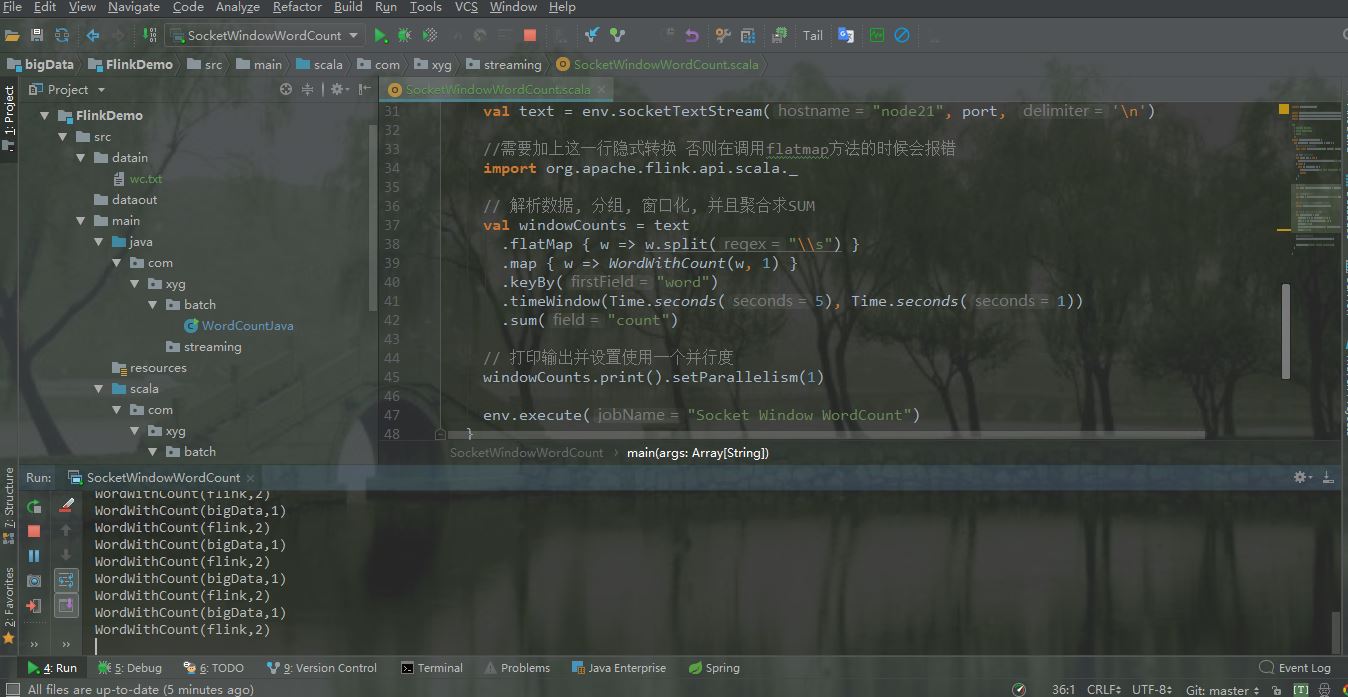
4.集群測試
這里單機測試官方案例
[admin@node21 flink-1.6.1]$ pwd /opt/flink-1.6.1 [admin@node21 flink-1.6.1]$ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host node21. Starting taskexecutor daemon on host node21. [admin@node21 flink-1.6.1]$ jps StandaloneSessionClusterEntrypoint TaskManagerRunner Jps [admin@node21 flink-1.6.1]$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
程序連接到套接字并等待輸入。您可以檢查Web界面以驗證作業是否按預期運行:
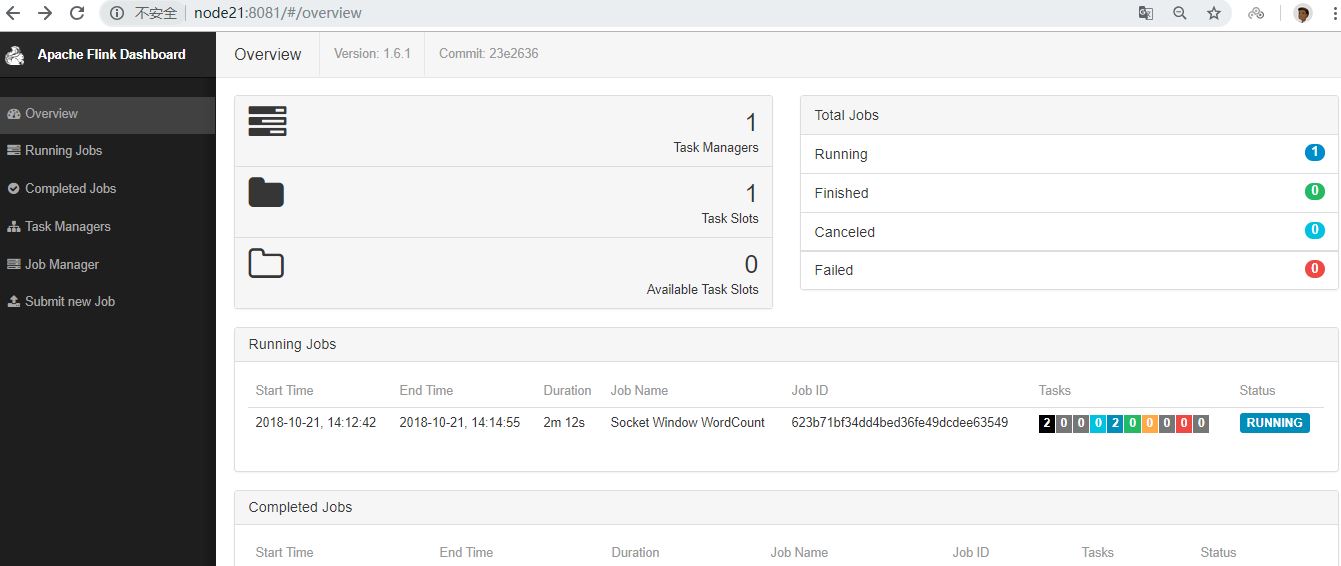
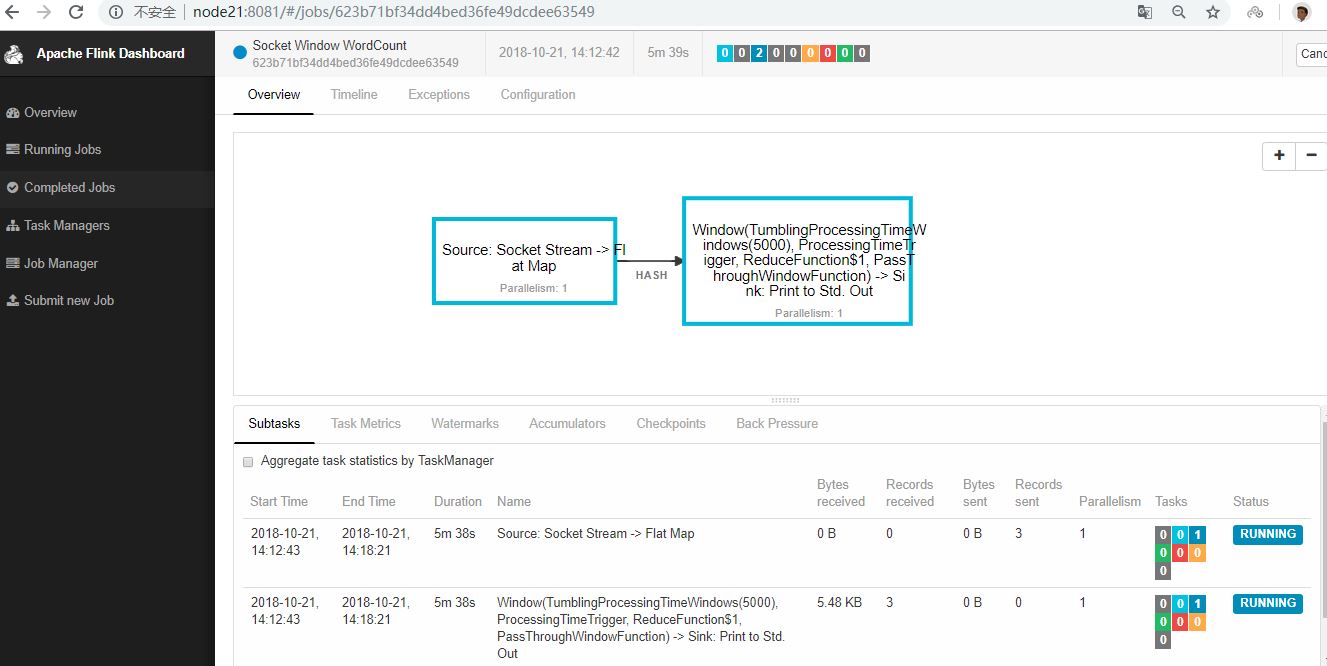
單詞在5秒的時間窗口(處理時間,翻滾窗口)中計算并打印到stdout。監視TaskManager的輸出文件并寫入一些文本nc(輸入在點擊后逐行發送到Flink):

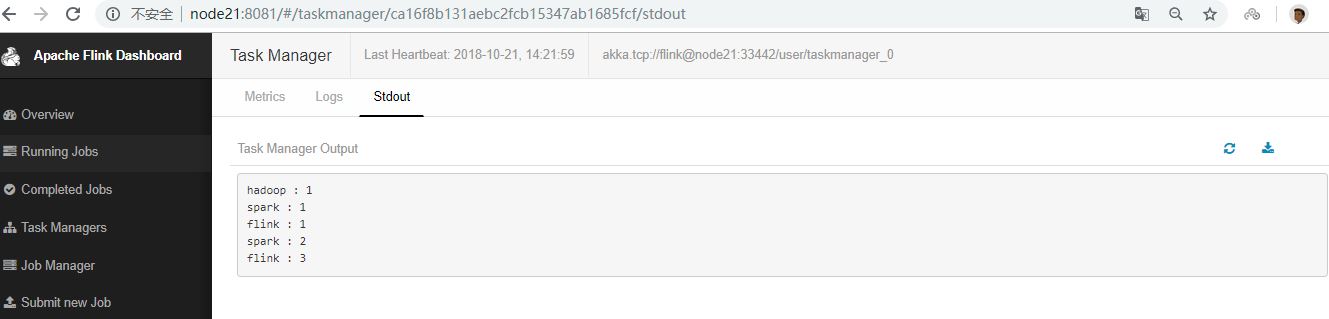
三.使用IDEA開發離線程序
Dataset是flink的常用程序,數據集通過source進行初始化,例如讀取文件或者序列化集合,然后通過transformation(filtering、mapping、joining、grouping)將數據集轉成,然后通過sink進行存儲,既可以寫入hdfs這種分布式文件系統,也可以打印控制臺,flink可以有很多種運行方式,如local、flink集群、yarn等.
1. scala程序
package com.xyg.batch
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
object WordCountScala{
def main(args: Array[String]) {
//初始化環境
val env = ExecutionEnvironment.getExecutionEnvironment
//從字符串中加載數據
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
//分割字符串、匯總tuple、按照key進行分組、統計分組后word個數
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
//打印
counts.print()
}
}2. java程序
package com.xyg.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
public class WordCountJava {
public static void main(String[] args) throws Exception {
//構建環境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//通過字符串構建數據集
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
//分割字符串、按照key進行分組、統計相同的key個數
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//打印
wordCounts.print();
}
//分割字符串的方法
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}3.運行
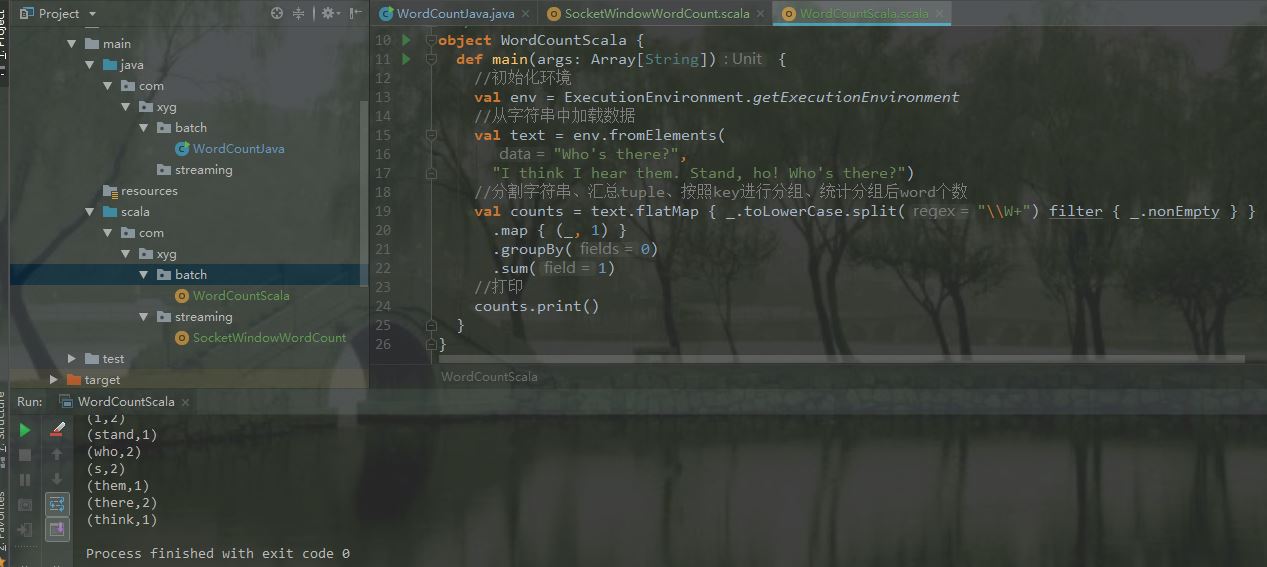
以上是“怎么搭建Flink開發IDEA環境”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





